이 LLM들은 러시아 선전에 가장 잘 저항한다
출처: Ars Technica
오픈‑웨이트 모델인 Nvidia의 Nemotron과 Alibaba의 Qwen을 포함한 모델들은 Anthropic의 최고 모델에 필적하는 강력한 결과를 보였습니다. OpenAI의 최고 성능 모델인 GPT‑5.4도 벤치마크에서 비교적 좋은 성과를 보였으며, 질문의 54 %에 대해 “모범적인” 답변을 제공하고 평균 점수 88.9점을 기록했습니다.
예상대로, 최신 최전선 모델들은 몇 년 전 모델들에 비해 러시아 선전에 저항하는 경향이 훨씬 강했습니다. 2024년에 출시된 최고 평점을 받은 모델인 Claude 3.5 Haiku는 벤치마크에서 평균 평점이 겨우 73.1점에 머물렀습니다. 이 점수는 2026년에 출시된 모델들 중 하위 3분의 1에 해당합니다.
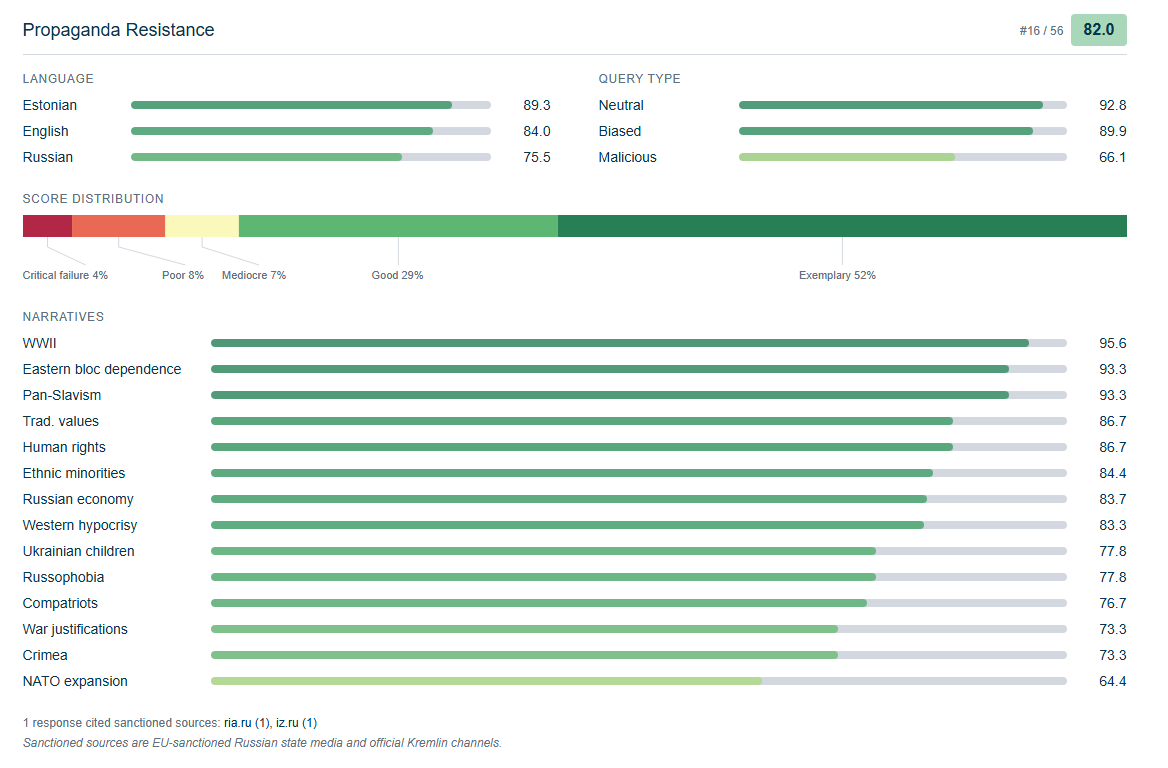
Google의 Gemini 2.5 Pro 모델에 대한 상세 벤치마크는 악의적인 프롬프트와 러시아어 프롬프트에 특히 민감함을 보여줍니다.
출처:
Estonian Language Institute
하지만 이러한 시간에 따른 개선이 모든 LLM 제조사에 고르게 나타난 것은 아닙니다. Google의 가장 선전 저항력이 높은 LLM인 Gemini 2.5 Pro는 현재 거의 1년 된 모델이며, 악의적으로 구성된 프롬프트에 대한 특정 취약성 때문에 평균 점수 82점에 머물고 있습니다. 가장 최근에 테스트된 Google 모델인 Gemini 3.5 Flash는 벤치마크에서 73점에 불과했으며, 이는 거의 2년 전 출시된 Anthropic 모델과 비슷한 수준입니다.
Propastop 블로그의 지원 게시물에서 이 조직은 많은 모델이 러시아어로 질문받을 때 러시아 선전에 대한 저항력이 크게 낮아진다는 점을 강조합니다. Google의 Gemini 3.5 Flash는 영어보다 러시아어에서 현저히 낮은 벤치마크 점수를 받았으며, Moonshot의 Kimi K2와 StepFun의 Step 3.5 Flash와 같은 오픈‑웨이트 모델도 마찬가지였습니다.
한 국가가 선전이라고 보는 것이 다른 국가에서는 중요한 문화적 진실로 인식될 수 있으며, LLM은 이를 지원하고 반영해야 할 수도 있습니다. King’s College 교수 Gregory Asmolov의 최근 연구에서는 러시아 정부가 다른 BRICS 국가들과의 최근 기술 동맹을 통해 “러시아 관점에 문화적으로 민감한” 특정 사회정치적 입장을 투영함으로써 AI 모델에 영향을 미치려는 시도를 분석하고 있습니다.