Svelte 컴파일러가 55% 빨라졌다. 수정은 3개의 파일이었다.
Source: Dev.to


오슬로에 사는 개발자가 이 PR이 열리기 3일 전에 GitHub 이슈를 열었습니다. 그의 질문은 간단했습니다:
“Svelte가 도구 성능을 개선하기 위한 로드맵은 어떻게 되나요?”
Rich Harris의 답변은 더 짧았습니다: 공식적인 로드맵은 없습니다. 프로파일링하고, 발견한 문제를 고치세요.
그래서 Mathias Picker는 바로 그렇게 했습니다. 그는 Svelte 컴파일러를 프로파일링하고, 두 서브시스템의 교차점에 숨겨진 두 가지 알고리즘 문제를 찾아냈으며, 세 개의 코드 파일을 수정하는 풀 리퀘스트를 열었습니다.
Rich Harris의 리뷰: “fantastic!”
PR은 같은 날 머지되었습니다. Svelte 컴파일러의 분석 단계가 20 %–55 % 빠르게 동작하게 되었습니다. 하지만 diff에서는 보이지 않는 부분이 있습니다: 그 파일 중 하나인 state.js는 30개의 파일이 모든 컴파일러 단계에서 공유하는 전역 상태이며, 이를 변경하면 2,036개의 하위 파일이 영향을 받게 됩니다.
GitHub가 표시한 내용: 4개의 파일이 변경됨.
의존성 그래프가 보여준 내용: 2,036.
PR
sveltejs/svelte#17823 — “perf: 컴파일러 분석 단계 최적화”
Svelte의 컴파일러는 세 단계로 작동합니다:
- Parse – 텍스트 → AST
- Analyze – 의미 추출 (스코핑, 반응성, CSS 가지치기)
- Transform – JavaScript 생성
분석 단계는 컴파일러가 스코핑, 반응성, CSS 가지치기를 파악하는 단계이며, 바로 이 작업 때문에 Svelte가 마법처럼 느껴집니다.
그 안에 두 가지 문제가 숨어 있었습니다.
Problem 1: CSS pruning walked the stylesheet once per element
컴파일러는 어떤 CSS 규칙이 실제로 어떤 요소에 적용되는지 판단해야 합니다—사용되지 않는 규칙은 제거됩니다. 기존 코드는 모든 요소를 순회하면서 각 요소마다 전체 CSS AST를 탐색했습니다:
// Before: O(n × m) — n elements, m CSS rules
for (const node of analysis.elements) {
prune(analysis.css.ast, node); // walks entire stylesheet each time
}요소 50개와 CSS 규칙 100개가 있을 경우, 스타일시트 AST를 50번 전체 탐색하게 됩니다.
Fix: 루프 순서를 뒤바꿔—스타일시트를 한 번만 순회하고 각 선택자 안에서 요소를 매칭합니다.
// After: one walk, elements matched inside
prune(analysis.css.ast, analysis.elements);Problem 2: Deep‑cloning a stack on every AST node
Svelte는 경고를 억제하는 “ 주석을 지원합니다. 컴파일러는 이를 스택으로 추적합니다. 기존 코드는 모든 AST 노드마다 structuredClone(ignore_stack)을 호출했는데, 실제로는 컴포넌트당 0–5번 정도만 나타나는 무시 주석 때문에 불필요한 작업이었습니다:
// Before: deep‑clone on every AST node visit
ignore_map.set(node, structuredClone(ignore_stack));일반적인 컴포넌트는 500–2,000개의 AST 노드를 가지고 있습니다. 즉, 거의 변하지 않는 배열을 500–2,000번이나 깊게 복제하게 됩니다.
Fix: 스냅샷을 캐시하고 push_ignore 또는 pop_ignore가 실제로 스택을 변경할 때만 다시 구축합니다.
export function get_ignore_snapshot() {
if (cached_ignore_snapshot === null) {
cached_ignore_snapshot = ignore_stack.map((s) => new Set(s));
}
return cached_ignore_snapshot;
}Results (500 compilations later)
| Component | Before | After | Speed‑up |
|---|---|---|---|
| 80+ selectors, 12 elements | 3.405 ms | 2.680 ms | 21 % |
Nested each blocks | 2.034 ms | 1.575 ms | 23 % |
| 100 rules, 50 elements | 10.099 ms | 4.564 ms | 55 % |
Three files. Two fixes. A noticeable performance win.
의존성 그래프가 보여주는 내용
GitHub diff에서는 이 세 파일이 Svelte 아키텍처에서 어디에 위치하는지 숨겨져 있습니다 (네 번째 변경 파일은 .changeset 메타데이터 항목이며 코드가 없습니다).

파일 위치
| 파일 | 위치 | 역할 | 가져오기 영향 |
|---|---|---|---|
state.js | packages/svelte/src/compiler/state.js | 공유 전역 상태 (경고, 파일명, 소스, 무시 스택) | 30개의 파일이 세 단계 전체에 걸쳐 import |
index.js | packages/svelte/src/compiler/phases/2-analyze/index.js | 분석 단계 진입점 | 모든 컴포넌트에 대한 분석 워크를 조정 |
css-prune.js | packages/svelte/src/compiler/phases/2-analyze/css/css-prune.js | CSS 데드코드 제거 수행 | 어떤 CSS 규칙이 어떤 요소에 적용되는지 결정 |
3‑D 그래프에서 state.js를 선택하고 그 폭발 반경을 확장하면 파장이 즉시 나타납니다: 세 단계 전체에 걸쳐 30개의 직접 import자가 있고, 이들은 단계 진입점으로 연결되며, 그 진입점은 컴파일러 루트로, 컴파일러 루트는 모든 테스트 하네스로 연결됩니다. 파장이 멈출 때쯤이면 3,301개 파일 중 2,036개가 활성화됩니다—전체 Svelte 코드베이스의 **62 %**가 세 파일만 변경된 결과입니다.
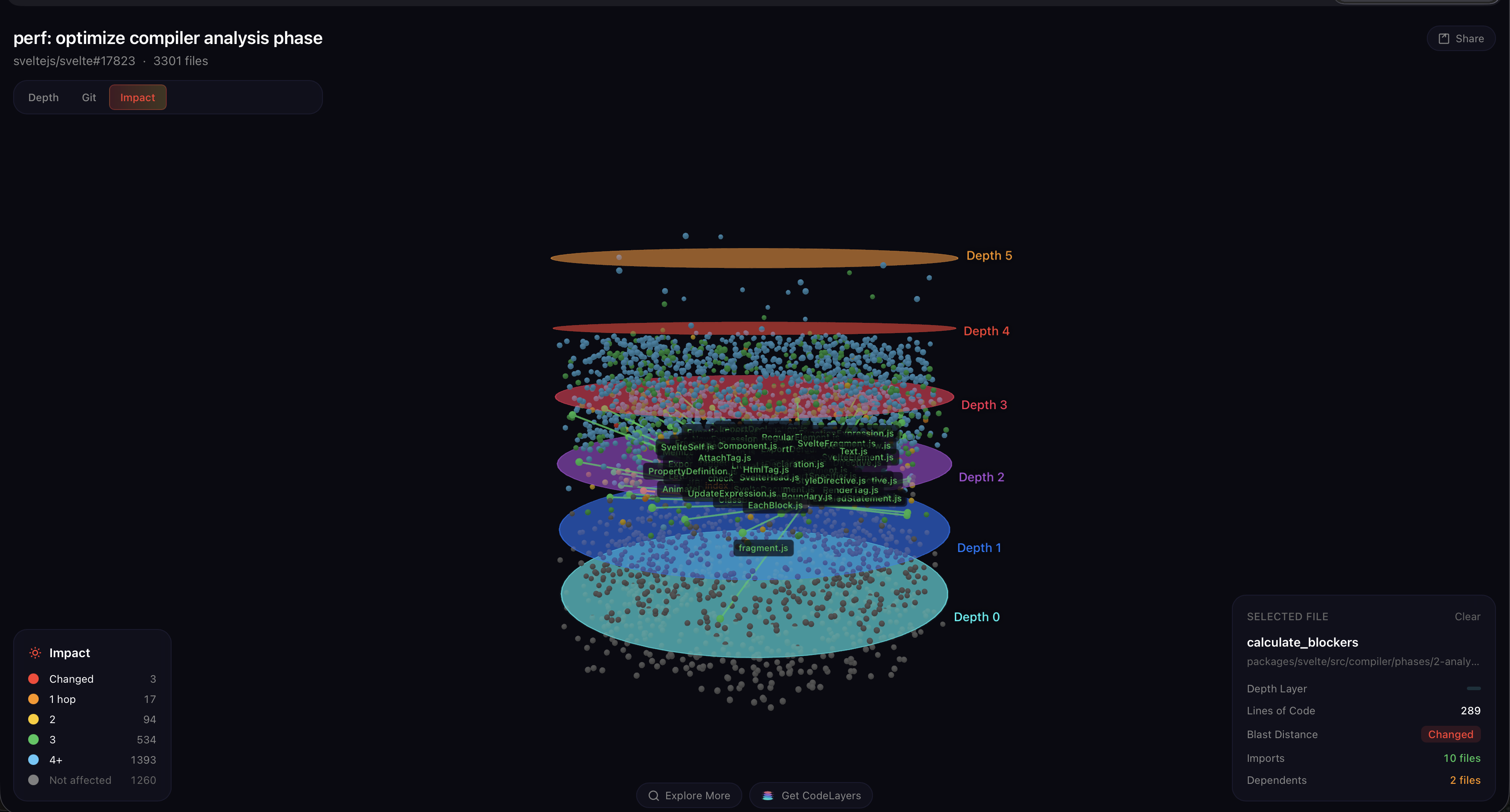
이것이 평면 diff 뷰에서는 얻을 수 없는 인사이트입니다. `state.js`는 Mathias가 건드린 파일 중 가장 연결성이 높은 파일이며—분석 단계에 있지 않고, 오히려 *그 아래*에 있어 모든 것이 공유합니다. 그래서 이러한 최적화가 매우 중요한 이유는 그가 수정한 코드 경로가 **모든 컴포넌트의 모든 AST 노드**에서 실행되며, 전체 컴파일러가 의존하는 모듈 안에 있기 때문입니다. 3개의 파일 수정이 2,000개의 파일에 파급 효과를 미치는 이유—파일들이 구조적 하중을 담당하고 있기 때문입니다.더 큰 이야기
Mathias는 하나의 PR에 그치지 않았습니다. 8일 동안 다섯 개의 성능 풀 리퀘스트를 열었습니다:
| PR | 수정 내용 | 속도 향상 | 탐색 |
|---|---|---|---|
| #17811 | 파서 핵심 경로 | 18 % 더 빠름 | View in 3D |
| #17823 | 분석 단계 (이번 PR) | 21‑55 % 더 빠름 | View in 3D |
| #17839 | 요소 상호작용 캐싱 | ~8 % 더 빠름 | — |
| #17844 | O(n²) 스코프‑이름 스캔 | ~10 % 더 빠름 | View in 3D |
| #17846 | CSS 선택자 정리 | ~16 % 더 빠름 | View in 3D |
모두 Rich Harris가 병합했으며 며칠 내에 배포되었습니다.
한 가지 질문으로 시작했습니다: “Svelte의 도구 성능 향상 로드맵은 무엇인가요?”
그 답은 하나의 개발자와 프로파일러, 8일, 그리고 다섯 개의 풀 리퀘스트였습니다.
직접 확인해 보세요
우리는 이 PR을 CodeLayers Explore 로 실행했습니다 – GitHub PR URL을 붙여넣으면 인터랙티브한 3‑D 의존성 그래프를 얻을 수 있습니다. 여기 sveltejs/svelte#17823 입니다:
- 아무 노드나 클릭하세요.
- 그래프를 회전시키세요.
- 변경된 파일을 선택하면 깊이 링을 통해 블라스트 반경이 확장되는 것을 볼 수 있습니다.
- 분석 단계가 파서와 트랜스포머에 비해 어디에 위치하는지 확인하세요.
내 PR에서도 이런 가시성을 원하시나요?
- VS Code 확장 – 코드를 작성하면서 블라스트 반경을 인라인으로 표시합니다 (트리 뷰, 여백 장식, 11개 언어에 대한 CodeLens 주석). 로컬에서 실행되며, 데이터가 머신을 떠나지 않습니다.
- GitHub Action – 모든 PR에 3‑D 시각화 링크를 자동으로 게시합니다. 설정은 2분이면 끝나고, 리뷰어는 차이점(diff)으로는 알 수 없는 내용을 즉시 확인할 수 있습니다.
이것은 Blast Radius #1 입니다 – 매주 실제 오픈소스 PR을 3‑D 의존성 그래프로 실행하고 diff가 놓친 부분을 보여주는 시리즈입니다. 시각화해 주길 원하는 PR이 있나요? Bluesky에서 우리를 찾아보세요.