SQLite에서 UUID 기본키의 위험성
출처: Hacker News
2026년 6월 5일
데이터베이스에서 기본 키로 무작위 UUID를 사용하는 경우가 흔합니다. 무작위 UUID(UUID4)의 정렬되지 않은 특성 때문에 B‑tree에 행을 무작위로 삽입하고 재균형을 해야 하므로 클러스터드 인덱스에서 페이지가 많이 추가되는 것이 알려진 단점 중 하나입니다. 이 글에서는 그 추가 페이지 작업이 초래하는 성능 비용을 보다 직관적으로 이해할 수 있도록 돕고자 합니다.
이 글은 SQLite에 초점을 맞추고 있지만, 클러스터드 인덱스를 사용하는 다른 데이터베이스에서도 무작위 UUID 문제는 동일하게 나타납니다.
클러스터드 인덱스란?
클러스터드 인덱스는 테이블에 저장된 행들의 물리적 저장 순서를 결정합니다. 테이블의 데이터 행은 인덱스의 리프 페이지에 인덱스 키 순으로 정렬되어 저장됩니다. 따라서:
- 테이블당 클러스터드 인덱스는 하나만 존재할 수 있습니다(행은 한 가지 방식으로만 물리적으로 정렬될 수 있음).
- 클러스터드 인덱스 자체가 테이블이며, 리프 노드에는 전체 행 데이터가 들어 있습니다.
- 반면 비클러스터드 인덱스는 인덱스된 컬럼과 실제 행 데이터를 가리키는 포인터만 저장하고, 실제 데이터는 다른 곳에 존재합니다.
Rowid
일반적인 SQLite 테이블은 rowid 라는 암묵적인 64비트 정수 기본 키를 가집니다. 테이블 데이터는 rowid 순으로 정렬된 B‑tree에 저장되며, 이는 사실상 SQLite의 클러스터드 인덱스입니다. 행의 물리적 저장 순서는 rowid 순서를 따릅니다.
WITHOUT ROWID
SQLite는 WITHOUT ROWID 테이블도 지원합니다. 이 테이블은 암묵적인 rowid 가 없으며, 대신 사용자가 선언한 기본 키가 클러스터드 인덱스로 사용됩니다.
기준선
우선 일반적인 rowid 정수 기본 키를 사용한 성능 기준선을 잡아보겠습니다. 1백만 행씩 10번, 총 1천만 행을 삽입합니다.
(d/q writer
["CREATE TABLE IF NOT EXISTS event(id INT PRIMARY KEY, data BLOB)"])
(dotimes [_ 100]
(time
(d/with-write-tx [db writer]
(dotimes [_ 1000000]
(d/q db ["INSERT INTO event (data) values (?)" data])))))결과:
total rowstime in ms1000000012082000000011023000000011774000000011385000000010866000000011017000000010708000000010699000000010791000000001081
대략 초당 백만 건의 삽입 속도입니다.
UUID4
이제 UUID4 로 테스트해보겠습니다.
(d/q writer
["CREATE TABLE IF NOT EXISTS event(id BLOB PRIMARY KEY, data BLOB) WITHOUT ROWID"])
(dotimes [_ 10]
(time
(d/with-write-tx [db writer]
(dotimes [_ 1000000]
(d/q db ["INSERT INTO event (id, data) values (?, ?)"
(random-uuid4-bytes) data])))))결과:
total rowstime in ms10000000264920000000564430000000713740000000835250000000935960000000981770000000104908000000011130900000001166810000000012586
오우! 10~12배 정도 느려졌네요?!
프로파일링
큰 차이가 나타났으니 직접 프로파일링해보겠습니다.
아래는 정규화된 diffgraph 입니다. diffgraph는 두 개의 프로파일 스냅샷(여기서는 INT와 UUID4)을 비교해 flamegraph 형태로 차이를 보여줍니다. 일반 diffgraph가 절대적인 변화를 보여주는 반면, 정규화된 뷰는 두 프로파일 간 샘플 수를 동일하게 맞춰 상대적인 차이를 백분율로 표시합니다. 이는 두 프로파일이 실행된 시간이 서로 다를 때 유용합니다.
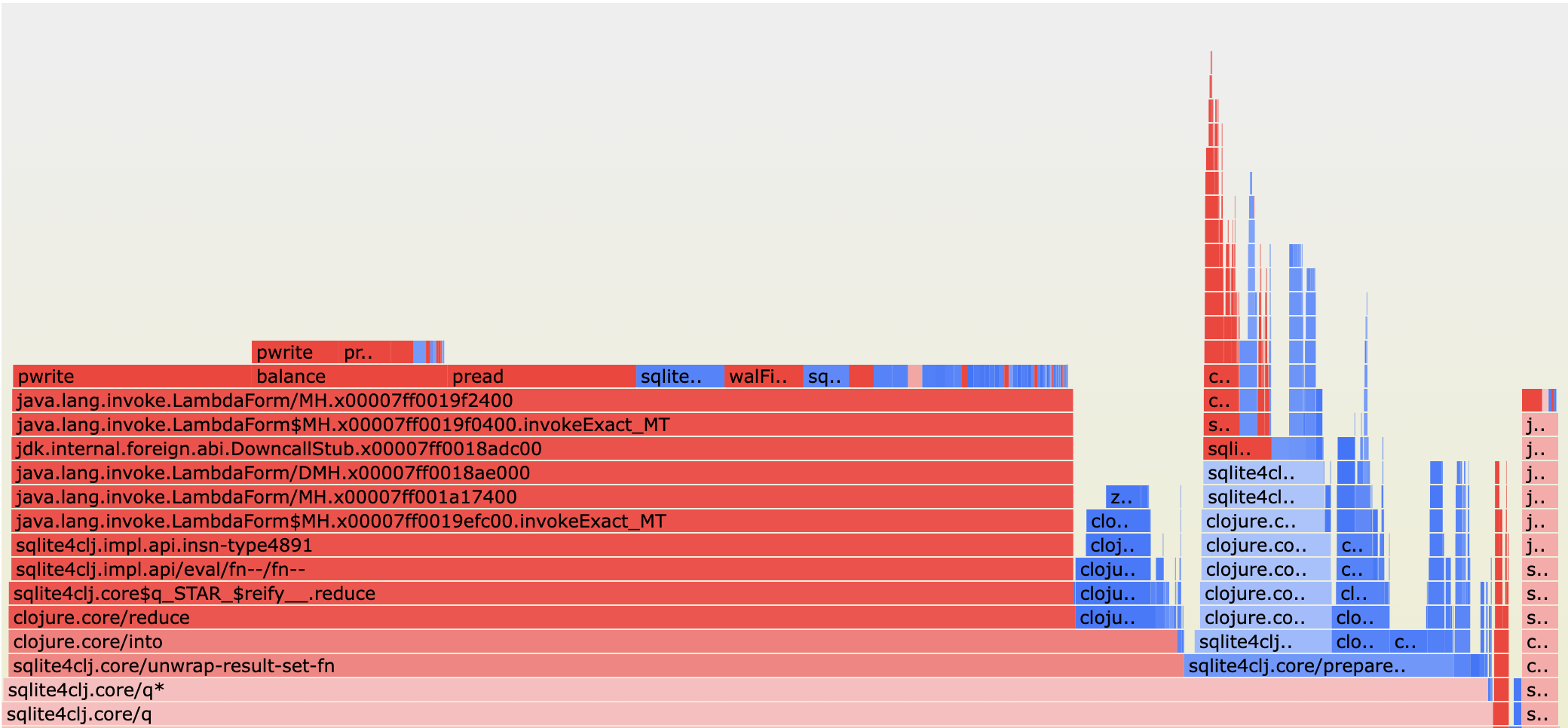
색상은 변화 방향을 나타냅니다. 파란색 프레임은 두 번째 프로파일(UUID4)에서 해당 함수에 소요된 시간이 첫 번째 프로파일(INT)보다 적다는 뜻이고, 빨간색 프레임은 더 많이 소요됐다는 의미입니다. 색상의 강도는 해당 프레임 자체(자체 시간)의 샘플 수 변화 비율을 나타냅니다.
diffgraph를 보면 트리를 재균형하는 데, 그리고 읽기·쓰기 작업에 훨씬 더 많은 시간이 소비되고 있음을 알 수 있습니다. 이는 UUID4가 무작위 순서이기 때문에 SQLite가 B‑tree를 지속적으로 재균형해야 하기 때문입니다.
UUID7
이론적으로는 시간 순서가 보장되는 UUID7을 사용하면 UUID4의 정렬 문제를 없앨 수 있습니다. 실제로 성능이 개선되는지 확인해보겠습니다.
(d/q writer
["CREATE TABLE IF NOT EXISTS event(id BLOB PRIMARY KEY, data BLOB) WITHOUT ROWID"])
(dotimes [_ 10]
(time
(d/with-write-tx [db writer]
(dotimes [_ 1000000]
(d/q db ["INSERT INTO event (id, data) values (?, ?)"
(random-uuid7-bytes) data])))))결과:
total rowstime in ms1000000013722000000012803000000013654000000012505000000012566000000012707000000012468000000012579000000012451000000001258
기준선에 가까운 수치로 돌아왔습니다. 기본키가 int(8바이트)인 경우보다 약간 느리지만, 16바이트 UUID 블롭 기본키가 차지하는 공간이 더 크기 때문입니다.
결론
이 글이 SQLite에서 UUID 기본키를 사용할 때 발생할 수 있는 함정들을 이해하고, 이를 어떻게 다루어야 할지에 대한 감을 잡는 데 도움이 되었길 바랍니다.
전체 벤치마크 코드는 여기에서 확인할 수 있습니다.
이 글이 마음에 드셨다면, SQLite로 100,000 TPS 달성하기도 읽어보세요.
추가 읽을거리
감사: 초안에 피드백을 제공해준 Datastar Discord 모든 분들께.