AI 코딩 에이전트를 사용할 때 대부분의 개발자들이 놓치는 #1 스킬
I’m happy to translate the article for you, but I’ll need the full text you’d like translated. Could you please paste the content (or the portion you want translated) here? I’ll keep the source line and all formatting exactly as you requested.
AI 코딩 에이전트에 대한 논쟁
AI 코딩 에이전트에 대한 논쟁은 가장 중요한 요소를 놓치고 있습니다. 이는 프롬프트 엔지니어링에 관한 것이 아니라 컨텍스트 윈도우를 이해하는 것에 관한 문제입니다.
개발자들은 양분됩니다:
- 한쪽은 “코딩 에이전트는 별로다.” 라고 주장합니다.
- 다른 쪽은 “당신이 잘못 사용하고 있는 거야; 이것은 스킬 문제다.” 라고 주장합니다.
두 관점 모두 일부분은 사실이지만, 가장 흔한 스킬 문제는 프롬프트 엔지니어링이 아니라 도구의 주요 제약을 근본적으로 오해하는 것입니다.
제가 개발자들에게서 가장 자주 보는 스킬 문제는, 컨텍스트 윈도우에 대해 충분히 생각하지 않는 것입니다.
컨텍스트 윈도우란?
컨텍스트 윈도우는 LLM이 단일 세션에서 처리하는 입력 토큰과 출력 토큰의 전체 집합을 말합니다. 모델의 작업 메모리라고 생각하면 됩니다—응답을 생성할 때 모델이 볼 수 있고 고려할 수 있는 모든 내용입니다.
포함되는 항목:
- 입력 토큰 – 시스템 프롬프트, 지시 사항, 사용자 메시지 등.
- 출력 토큰 – 어시스턴트가 생성한 응답.
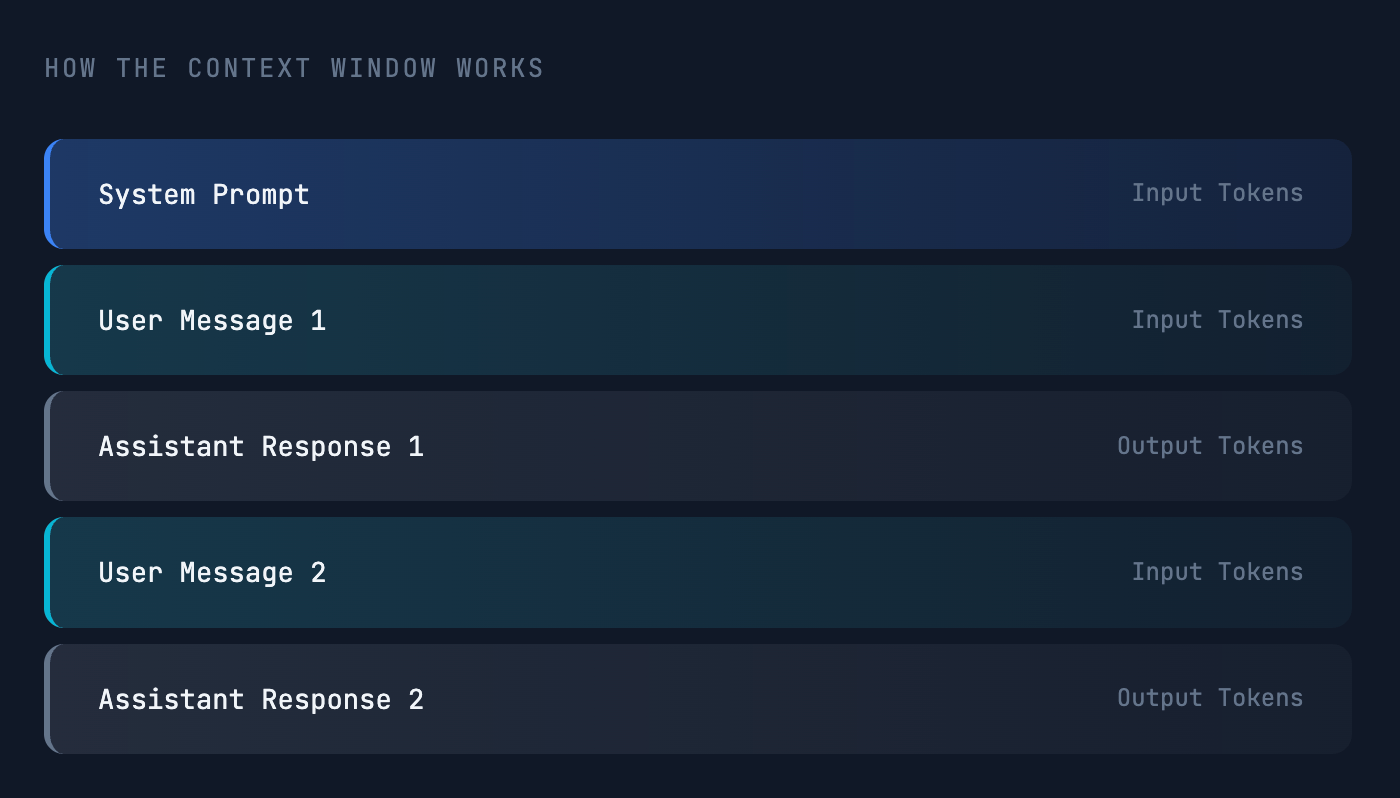
대화가 길어지면 토큰 수가 늘어납니다. 결국 모델 제공자가 설정한 한도에 도달하게 됩니다. 이는 대화가 너무 길어 또는 단일 입력이 매우 큰 경우(예: 방대한 문서 업로드) 발생할 수 있습니다. 한도를 초과하면 오류가 발생하고 생성이 즉시 중단됩니다.
2025년 컨텍스트 윈도우
Model providers는 아키텍처와 비용에 따라 서로 다른 제한을 설정합니다. 제한은 수천 토큰에서 수백만 토큰까지 다양하지만 크다고 항상 좋은 것은 아닙니다.

Gemini는 정말 큰 컨텍스트 윈도우를 가지고 있지만, 보시다시피… 크다고 항상 좋은 것은 아닙니다.
The Paradox: More Context, Worse Performance
Counterintuitive truth: the more information you give a model, the worse it performs at retrieving specific details. This holds for all models, from the smallest to the largest.
Why infinite context doesn’t exist
-
Cost & Memory
LLM processing is expensive. Larger contexts consume significantly more memory per request, driving up both computational costs and latency. -
Performance Degradation
An LLM’s attention is not distributed evenly across the context. Tokens at the very beginning and very end of a conversation have the most impact on the output. Tokens in the middle are often de‑prioritized or ignored entirely.
This is called the “Lost in the Middle” problem.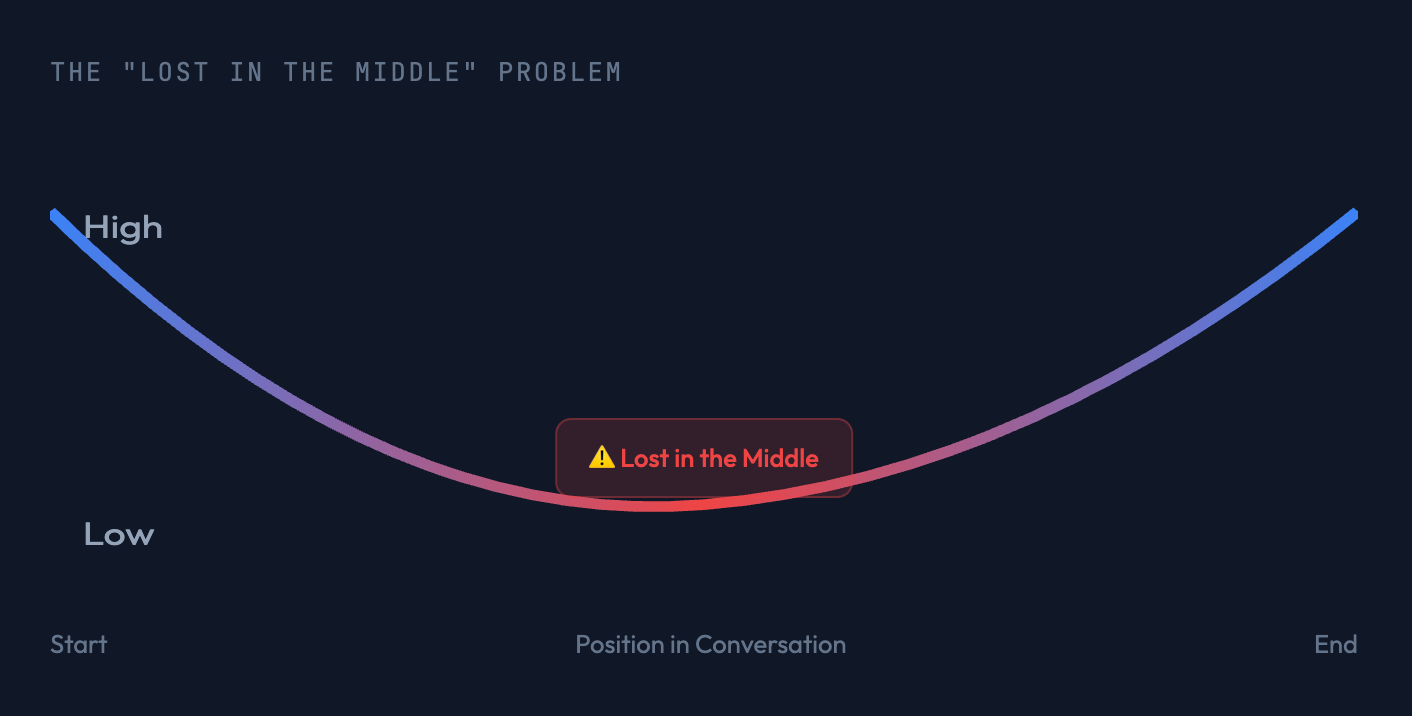
It isn’t a bug; it’s an emergent property of transformer architecture. It mirrors human cognitive biases:
- Primacy Bias – better recall for items at the beginning.
- Recency Bias – better recall for items at the end.
Just like humans, models do better with less, more focused information.
역설: 컨텍스트가 많을수록 성능이 나빠진다
직관에 반하는 진실: 모델에 정보를 많이 줄수록 구체적인 세부 정보를 찾아내는 성능이 오히려 떨어진다. 이는 가장 작은 모델부터 가장 큰 모델까지 모두 적용된다.
무한 컨텍스트가 존재하지 않는 이유
-
비용 및 메모리
LLM 처리에는 비용이 많이 든다. 컨텍스트가 커질수록 요청당 메모리 사용량이 크게 증가해 계산 비용과 지연 시간이 모두 상승한다. -
성능 저하
LLM의 어텐션은 컨텍스트 전체에 고르게 분배되지 않는다. 대화의 가장 처음과 가장 끝에 있는 토큰이 출력에 가장 큰 영향을 미친다. 중간에 위치한 토큰은 종종 우선순위가 낮아지거나 완전히 무시된다.
이를 “Lost in the Middle”(중간에 묻힌) 문제라고 부른다.이는 버그가 아니라 트랜스포머 아키텍처에서 자연스럽게 나타나는 특성이다. 인간의 인지 편향과도 유사하다:
- Primacy Bias(초기 편향) – 처음에 나온 항목을 더 잘 기억한다.
- Recency Bias(최근 편향) – 마지막에 나온 항목을 더 잘 기억한다.
인간과 마찬가지로, 모델도 적고 집중된 정보일 때 더 좋은 성능을 보인다.
사례 연구: 1,000만 토큰 윈도우는 모델이 활용하지 못하면 쓸모가 없다
Meta가 1,000만 토큰 컨텍스트 윈도우를 갖춘 모델을 발표했을 때, 이는 획기적인 발전처럼 보였습니다. 그러나 실제 테스트에서는 심각한 중간에 놓치는 문제들이 빠르게 드러났습니다. 모델에 방대한 양의 정보를 입력할 수는 있었지만, 그 정보를 효과적으로 검색하거나 활용하는 데 실패했습니다.
LLM을 평가할 때는 컨텍스트 윈도우의 크기만 보지 말고, 그 윈도우에서 정보를 얼마나 잘 검색해 내는지도 살펴보세요.
해결책: 컨텍스트를 가볍고 집중적으로 유지하기
짧은 컨텍스트 윈도우는 중간에 놓치는 문제를 덜 겪습니다. 더 나은 성능을 위한 핵심은 능동적인 관리입니다:
- 코딩 에이전트의 채팅 기록을 정기적으로 삭제하여 “메모리”를 새로 고치고 지시 사항이 높은 우선순위를 유지하도록 합니다.
- 이것이 결과를 개선하는 가장 효과적인 방법입니다.
Step 1 – 컨텍스트 사용량에 대한 완전한 투명성 확보
측정할 수 없는 것은 관리할 수 없습니다. 훌륭한 코딩 에이전트는 컨텍스트 창의 현재 상태를 검사할 수 있는 도구를 제공합니다. 예를 들어, Cursor에서는:

Step 2 – clear를 기본 동작으로 설정하기
새로운, 관련 없는 작업을 시작하거나(예: 남은 토큰이 50 k 미만일 때) 컨텍스트 사용량이 높아지면 대화 기록을 완전히 삭제하는 것이 최선의 방법입니다. 이렇게 하면 전체 컨텍스트 창이 비워져 빈 슬레이트를 제공하고 새로운 작업에 대한 최대 성능을 보장합니다.

Step 3 – 대화의 의도를 보존해야 할 때 compact 사용
compact는 상세 기록을 삭제하지만 LLM‑기반 요약을 생성하는 대안입니다. 이는 대화의 분위기 혹은 핵심 목표를 훨씬 작은 형태로 보존합니다.

이것은 의도 중 일부를 보존합니다… 마치 이 대화만을 위한 미니 규칙 파일과 같습니다.
Note: 요약을 생성하는 데는 시간이 걸리며 토큰을 소비합니다.
경고의 말씀: 숨겨진 컨텍스트가 성능을 방해할 수 있습니다
숨겨진 컨텍스트를 대량으로 추가하는 도구와 설정에 대해 매우 조심하십시오. 이는 처음부터 창을 부풀려 실제 대화가 두려운 중간으로 밀려나게 합니다.
흔히 문제를 일으키는 요소들
- LSP/MCP 서버 – 시스템 프롬프트에 방대한 도구 세트를 주입할 수 있습니다.
- 대형 규칙 파일 – Cursor나 Claude Code와 같은 도구에서 과도하게 복잡하거나 많은 사용자 정의 규칙.
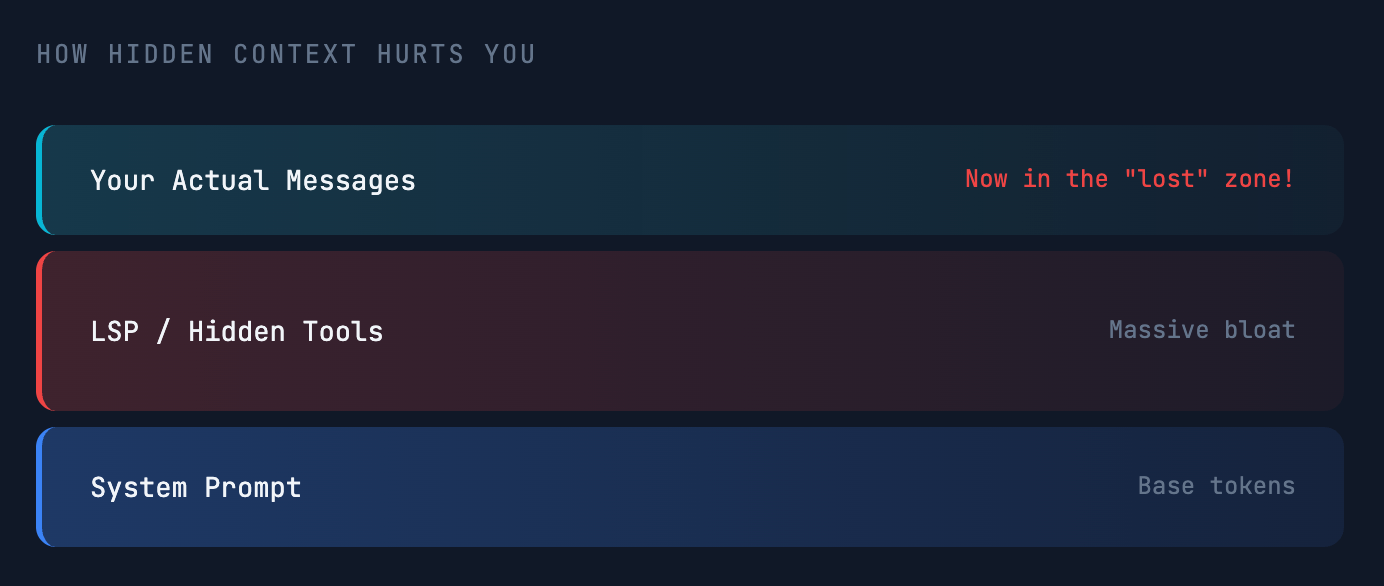
숨겨진 도구가 대부분의 컨텍스트를 차지하면 실제 메시지는 중간에서 길을 잃은 영역에 배치되며, 바로 모델이 가장 적게 주의를 기울이는 곳입니다.
핵심 요점
- 컨텍스트 윈도우는 모델의 전체 메모리(입력 + 출력)이다. 대화가 길어지면 빠르게 채워지고 성능이 저하된다.
- 모든 모델은 하드코딩된 한계가 있으며 중간 손실 주의력 감소 문제를 겪는다. 백만 토큰 윈도우조차도 이 문제에서 자유롭지 않다.
- 더 가볍고 집중된 컨텍스트가 일관되게 더 나은 성능을 제공한다. 초기에 명확히, 자주 명확히.
새로운 사고방식
컨텍스트에 무엇이 들어 있는지에 대해 건전한 편집증을 키우세요. clear와 compact 같은 도구를 사용해 적극적으로 관리하십시오. 이 능력은 AI와의 좌절스러운 상호작용을 생산적인 파트너십으로 구분해 줍니다.
컨텍스트 윈도우를 마스터하는 것이 훌륭한 결과를 얻는 열쇠입니다.