StrongDM의 AI 팀, 코드를 보지 않고도 진지한 소프트웨어를 구축한다
Source: Hacker News
7 February 2026
지난 주에 나는 데모를 살짝 언급했습니다 — Dan Shapiro가 Dark Factory 수준의 AI 도입이라고 부른, 코딩 에이전트가 만든 코드를 인간이 전혀 검토하지 않는 상황을 구현한 팀의 데모였습니다. 그 팀은 StrongDM의 일원이며, 이제 막 Software Factories and the Agentic Moment 에서 그들이 어떻게 작업하고 있는지에 대한 첫 번째 공개 설명을 공유했습니다:
우리는 Software Factory를 구축했습니다: 사양 + 시나리오가 에이전트를 구동해 코드를 작성하고, 테스트 하네스를 실행하며, 인간 검토 없이 수렴하도록 하는 비대화형 개발 방식. […]
공안이나 만트라 형태
- 내가 왜 이걸 하고 있지? (암시: 모델이 대신 해야 함)
규칙 형태로
- 코드 인간에 의해 작성되어서는 안 된다
- 코드 인간에 의해 검토되어서는 안 된다
실용적인 형태
- 만약 인간 엔지니어당 오늘 $1,000 이상의 토큰을 사용하지 않았다면, 여러분의 소프트웨어 팩토리는 개선 여지가 있습니다.
나는 이 중 가장 흥미로운 것이 “코드는 인간에 의해 검토되지 않아야 한다.” 라는 점이라고 확신한다. 우리는 모두 LLM이 얼마나 비인간적인 실수를 저지를 수 있는지 알고 있는데, 이것이 어떻게 합리적인 전략이 될 수 있겠는가?
최근 많은 개발자들이 2025년 11월 전환점 을 인정하고 있다. 이때 Claude Opus 4.5와 GPT 5.2가 코딩 에이전트가 지시를 얼마나 신뢰성 있게 따르고 복잡한 코딩 작업을 수행할 수 있는지에 대한 관점을 바꾼 것으로 보였다. StrongDM의 AI 팀은 2025년 7월에 Claude Sonnet 3.5와 관련된 이전 전환점을 기반으로 설립되었다:
촉매제는 2024년 말에 관찰된 전환이었다: Claude 3.5의 두 번째 개정판(2024년 10월)과 함께, 장기 에이전트 코딩 워크플로우가 오류보다 정확성을 누적하기 시작했다.
2024년 12월까지 모델의 장기 코딩 성능은 Cursor의 YOLO mode 를 통해 명확히 드러났다.
그들의 새로운 팀은 “수동 코딩 소프트웨어 금지” 라는 규칙으로 시작했으며—2025년 7월에는 급진적인 접근이었지만, 2026년 1월 현재 경험 많은 개발자들 사이에서 상당히 많이 채택되고 있는 추세이다.
핵심 문제
직접 코드를 손으로 작성하지 않는다면, 어떻게 코드가 실제로 작동하는지 확인할 수 있을까요?
에이전트가 테스트를 작성하는 것은 그들이 부정행위를 하지 않고 assert true를 사용하지 않을 때만 도움이 됩니다.
이것은 현재 소프트웨어 개발에서 가장 중대한 질문처럼 보입니다: 코딩 에이전트가 구현과 테스트를 모두 작성하고 있는 상황에서, 생산하는 소프트웨어가 작동한다는 것을 어떻게 증명할 수 있을까? (내 이전 글인 소프트웨어가 작동함을 증명하기를 참고하세요.)
StrongDM’s answer: scenario testing
StrongDM은 scenario testing(Cem Kaner, 2003)에서 영감을 받았습니다. 그들이 설명하길:
우리는 scenario라는 단어를 엔드‑투‑엔드 “user story”를 나타내는 용어로 재정의했습니다. 이는 코드베이스 외부에 저장되는 경우가 많으며(모델 학습에서 “holdout” 세트와 유사), LLM이 직관적으로 이해하고 유연하게 검증할 수 있습니다.
우리가 개발하는 소프트웨어 대부분이 에이전시(주체성) 요소를 가지고 있기 때문에, 성공을 정의하던 불리언 방식(“테스트 스위트가 초록색”)에서 확률적이고 경험적인 방식으로 전환했습니다. 우리는 이 검증을 정량화하기 위해 satisfaction이라는 용어를 사용합니다: 모든 시나리오를 통해 관찰된 궤적 중, 어느 정도 비율이 사용자를 만족시킬 가능성이 있는가?
시나리오를 hold‑out 세트처럼 취급하는 것—소프트웨어를 평가하는 데 사용되지만 코딩 에이전트가 볼 수 있는 곳에 저장되지 않음—은 매우 흥미롭습니다. 이는 외부 QA 팀에 의한 공격적인 테스트를 모방하는 것으로, 전통적인 소프트웨어에서 품질을 보장하는 데 비용이 많이 들지만 매우 효과적인 방법입니다.
디지털 트윈 유니버스 (DTU)
데모에서 가장 강렬한 인상을 남긴 부분은 StrongDM이 제시한 디지털 트윈 유니버스 개념이었습니다.
그들이 만들고 있던 소프트웨어는 연결된 서비스 모음 전반에 걸쳐 사용자 권한을 관리하는 데 도움을 주었습니다. 이는 자체적으로도 주목할 만했습니다—보안 소프트웨어가 검증되지 않은 LLM 코드를 사용해 구축된다는 것은 상상하기 어려운 일입니다!
**[디지털 트윈 유니버스]**는 우리 소프트웨어가 의존하는 서드파티 서비스들의 행동 클론입니다. 우리는 Okta, Jira, Slack, Google Docs, Google Drive, 그리고 Google Sheets의 트윈을 구축하여 그들의 API, 엣지 케이스, 관찰 가능한 행동을 복제했습니다.
DTU를 통해 그들은 다음을 할 수 있습니다:
- 생산 한계를 훨씬 초과하는 규모와 속도로 검증
- 실 서비스에 대해 위험하거나 불가능한 실패 모드를 테스트
- 레이트 한도에 걸리거나 남용 탐지를 유발하거나 API 비용이 누적되지 않으면서 시간당 수천 개의 시나리오 실행
트윈을 만든 방법
- 대상 서비스(예: Okta)의 전체 공개 API 문서를 에이전트 하네스에 덤프합니다.
- 에이전트에게 해당 API를 모방하는 독립 실행형 Go 바이너리를 생성하도록 지시합니다.
- 필요에 따라 시뮬레이션을 완성하는 데 도움이 되는 간단한 UI를 추가합니다.
이제 레이트‑한도나 사용량 할당량에 얽매이지 않는 독립적인 서비스 클론을 보유하게 되면서, 시뮬레이션 테스트군이 마구 뛰어놀 수 있게 되었습니다. 그들의 시나리오 테스트는 새로운 시스템이 구축되는 동안 지속적으로 실행되는 에이전트 스크립트가 됩니다.
예시: Slack 트윈
아래 스크린샷은 DTU가 생성한 Slack‑유사 인터페이스를 보여줍니다. 테스트 과정이 어떻게 진행되는지, 다양한 시뮬레이션 시스템에 대한 접근이 필요해지는 시뮬레이션 Okta 사용자들의 스트림을 표시합니다.
[Image: “DTU Slack”이라는 제목의 Slack‑유사 인터페이스 스크린샷. 스레드 보기 (Thread — C4B9FBB97)와 “Focus first”, “Leave” 버튼이 보이며, 왼쪽 사이드바에는 #org‑general (182), #general (0) (shared×2), #it‑support (0), #channel‑0002 (0) (shared×2), #channel‑0003 (0)부터 #channel‑0020 (0)까지, #org‑finance (1) 및 “Start” 버튼이 있는 DM 섹션이 나열됩니다. 하단에 “Create” 버튼이 표시됩니다.]
(이미지 자리 표시자 – #를 실제 이미지 URL로 교체하세요.)
버튼은 사이드바 상단에 표시됩니다. 메인 스레드에는 Okta ID를 가진 사용자들(예: @okta-u-423438-00001, @okta-u-423438-00002 등)의 자동 소개 메시지가 약 9개 정도 표시되며, 모두 2025‑11‑12Z의 18:50:31부터 18:51:51 사이에 타임스탬프가 찍혀 있습니다.
각 메시지는 다음 형식을 따릅니다:
“안녕하세요 팀! 저는 **[이름]**이며, 일반 채널에서 직원으로 합류합니다.
핵심 기술: [허구의 기술 문구].
기여하게 되어 기대됩니다!”
모든 사용자는 빨강/주황색 “O” 아바타 아이콘을 가지고 있습니다.
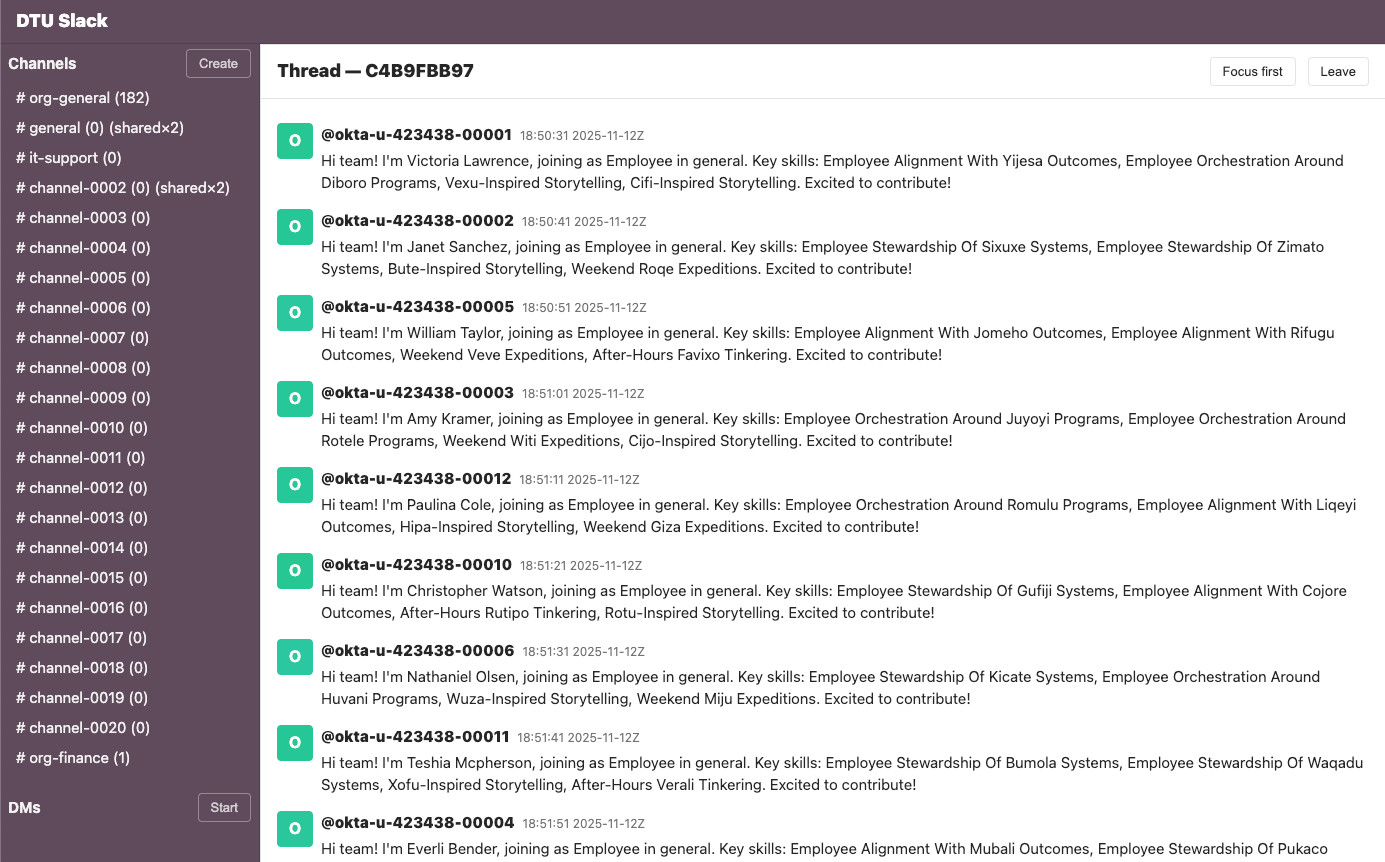
왜 중요한가
이처럼 Slack의 일부를 빠르게 유용한 클론으로 생성할 수 있는 능력은 새로운 세대 코딩‑에이전트 도구가 얼마나 파괴적일 수 있는지를 보여줍니다.
대규모 SaaS 애플리케이션의 고충실도 클론을 만드는 것은 언제나 가능했지만, 경제적으로 실현 가능하지는 않았습니다. 여러 세대의 엔지니어가 CRM 전체를 메모리 내 복제본으로 테스트하고 싶어했지만, 이를 구축하자는 제안을 스스로 검열했습니다.
**기술 페이지**도 살펴볼 가치가 있습니다. Digital Twin Universe 외에도 다음과 같은 용어를 소개합니다:
- Gene Transfusion – 에이전트가 기존 시스템에서 패턴을 추출해 다른 곳에 재사용합니다.
- Semports – 코드를 한 언어에서 다른 언어로 직접 포팅합니다.
- Pyramid Summaries – 에이전트가 짧은 요약을 빠르게 열거하고 필요에 따라 더 상세한 정보를 확대해서 볼 수 있도록 여러 수준의 요약을 제공합니다.
StrongDM AI 릴리스
Attractor
- Repository: github.com/strongdm/attractor
- Description: 그들의 소프트웨어 팩토리 핵심에 있는 비대화형 코딩 에이전트.
- Note: 이 저장소에는 코드가 없으며, 사양을 상세히 설명하는 마크다운 파일 3개와, 해당 사양을 원하는 코딩 에이전트에 입력하라는 README 메모만 포함되어 있습니다.
CXDB
- Repository: github.com/strongdm/cxdb
- Description: 보다 전통적인 릴리스이며:
- Rust 16 000줄
- Go 9 500줄
- TypeScript 6 700줄
- Function: 그들의 “AI 컨텍스트 스토어” – 대화 기록과 도구 출력물을 불변 DAG에 저장하는 시스템.
- Comparison: 내 LLM 도구의 SQLite 로깅 메커니즘과 유사하지만 훨씬 더 정교합니다. 이 중에서 몇 가지 아이디어를 유전자 전이 해야 할 수도 있겠네요!
미래를 엿보다?
저는 10월에 초대된 소규모 그룹의 일원으로 StrongDM AI 팀을 방문했습니다.
- 팀: Justin McCarthy, Jay Taylor, 그리고 Navan Chauhan (3개월 전에 결성됨).
- 데모: 코딩‑에이전트 하네스의 작동 데모, 반 다스 서비스의 Digital Twin Universe 복제본, 그리고 시나리오를 실행하는 시뮬레이션 테스트 에이전트 무리.
- 시점: 이는 에이전트 기반 코딩을 크게 신뢰할 수 있게 만든 Opus 4.5 / GPT 5.2 릴리즈 이전에 있었으며 (그 데모들보다 한 달 뒤에 출시됨).
이는 엔지니어가 코드를 작성하는 것에서 코드를 작성하는 시스템을 구축하고 반‑모니터링하는 단계로 이동하는, 소프트웨어 개발의 한 가능한 미래, 즉 다크 팩토리를 엿보는 느낌이었습니다.
기다려라, 엔지니어당 하루 $1,000 ?
첫 번째 공개 버전에서 이 부분을 대충 넘겼지만, 진지하게 다룰 가치가 있습니다.
- 비용 영향: 이러한 패턴이 실제로 엔지니어당 월 $20 000을 예산에 추가한다면, 저에게는 그다지 매력적이지 않게 됩니다.
- 비즈니스 모델 질문: 그 시점에서 문제는 이렇게 소프트웨어를 개발하는 막대한 오버헤드를 감당할 만큼 충분히 수익성 있는 제품 라인을 만들 수 있느냐가 됩니다.
- 경쟁 위험: 경쟁자는 몇 시간의 코딩‑에이전트 작업만으로도 여러분의 최신 기능을 복제할 수 있습니다.
이 패턴들을 훨씬 적은 비용으로 활용할 수 있기를 바랍니다. 저는 개인적으로 월 $200 Claude Max 플랜이 다양한 에이전트 패턴을 실험하기에 충분한 여유를 제공한다는 것을 확인했지만, 24시간 내내 QA 테스터 무리를 운영하고 있는 것은 아닙니다!
요점
- StrongDM에서 배울 점이 많으며, 토큰 비용에 수천 달러를 쓰지 않을 팀과 개인에게도 유용합니다.
- 나는 특히 에이전트가 만든 코드를 모든 라인을 검토하지 않고도 작동함을 증명하기 위해 필요한 것이 무엇인지에 관심이 있습니다.