Spinlocks vs. Mutexes: 언제 스핀하고 언제 슬립할까
발행: (2025년 12월 8일 오전 09:38 GMT+9)
5 분 소요
원문: Hacker News
Source: Hacker News
소개
perf top에서 pthread_mutex_lock이 60 % CPU 시간을 차지하고 있는 모습을 보고 있습니다. 레이턴시는 끔찍합니다. 누군가 “그냥 스핀락을 써라”고 제안하자, 16코어 서버가 아무 일도 하지 않으면서 100 %에 달합니다. 이것이 동기화 원시(primitives) 함정입니다: 엔지니어들은 각 원시가 언제 의미가 있는지 이해하지 못해 잘못된 선택을 하는 경우가 많습니다.
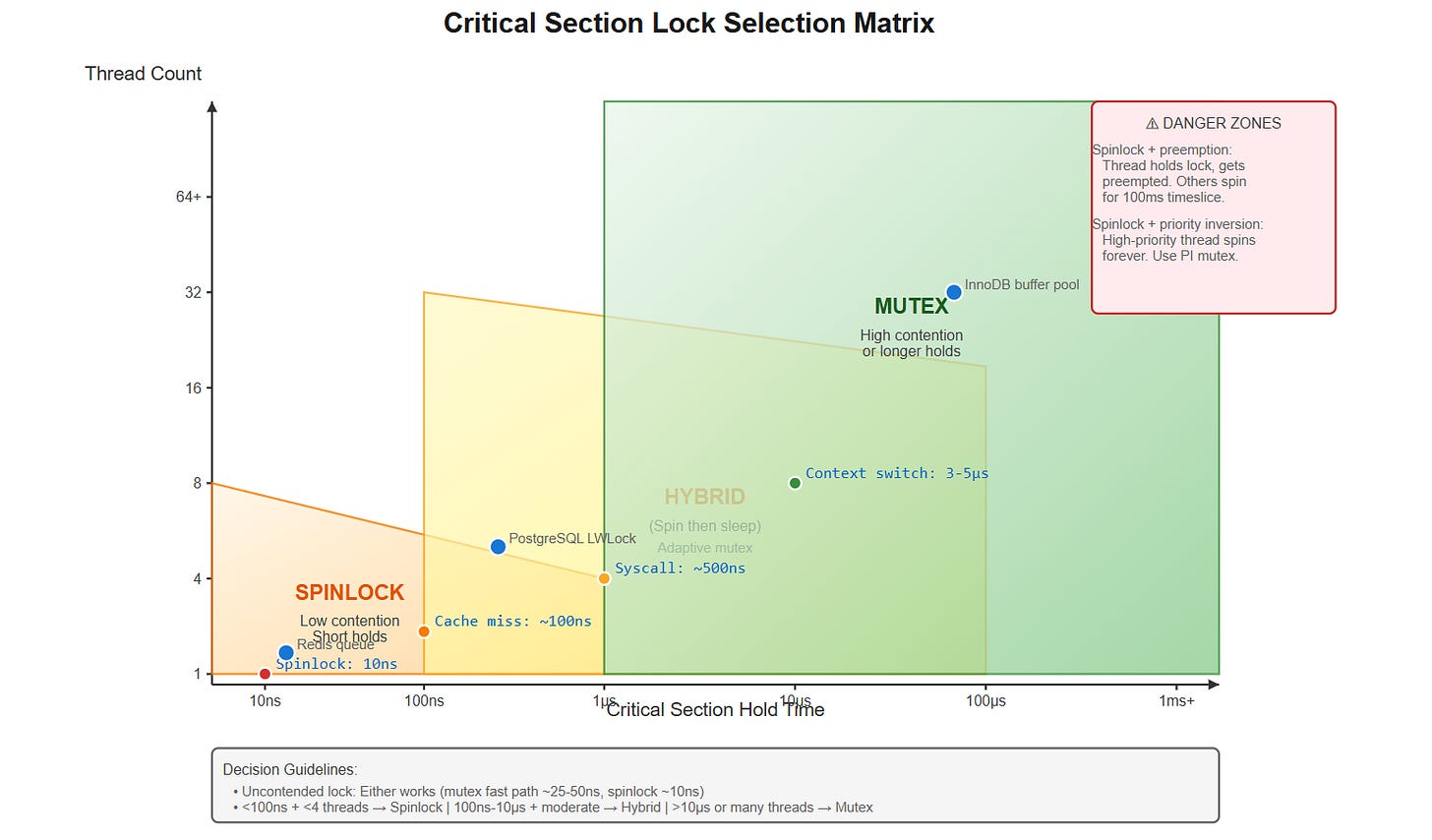
스핀락 vs. 뮤텍스
| 속성 | 뮤텍스 | 스핀락 |
|---|---|---|
| 동작 | 경쟁이 발생하면 잠듭니다. | 사용자 공간에서 바쁘게 대기(스핀)합니다. |
| 경쟁이 없을 때 비용 | 25–50 ns (fast path) | 하나의 원자적 LOCK CMPXCHG (≈40–80 ns). |
| 경쟁이 있을 때 비용 | 시스템 콜 (futex(FUTEX_WAIT)) ≈ 500 ns + 컨텍스트 스위치 (3–5 µs). | 루프를 도는 동안 CPU 100 % 사용; 실패 시마다 캐시 라인이 코어 사이를 오가며 비용이 발생합니다. |
| 선점 가능한 컨텍스트 | 안전 – 스레드가 디스패치 해제될 수 있음. | 위험 – 락 보유자가 선점되면 다른 스레드가 전체 타임슬라이스를 낭비합니다. |
| 우선순위 역전 | 우선순위 상속(PI) 뮤텍스로 해결 가능. | 해결 불가 – 낮은 우선순위 보유자가 실행되지 않으면 높은 우선순위 스레드가 영원히 스핀할 수 있습니다. |
| 잘못된 공유(False sharing) | 동일한 문제 – 모든 원자 연산이 캐시 라인을 무효화합니다. | 동일한 문제 – 락을 정렬하기 위해 추가적인 주의가 필요합니다. |
언제 어떤 원시를 사용할까
| 임계 구역 지속 시간 | 경쟁 수준 | 권장 원시 |
|---|---|---|
| ** 10 µs** 이상 또는 높은 경쟁 | 높음 | 일반 뮤텍스 – 스케줄러가 슬립/웨이크를 처리하도록 함. |
| 실시간 요구사항 | 어느 수준이든 | PREEMPT_RT 커널에서 우선순위 상속 뮤텍스. |
프로파일링 팁
CPU vs. 컨텍스트 스위치 – 다음 명령 실행:
perf stat -e context-switches,cache-misses- CPU 사용량은 낮지만 컨텍스트 스위치가 많으면 → 뮤텍스 오버헤드가 지배적일 수 있습니다.
- CPU 100 %에 캐시 미스가 많으면 → 락 경쟁 / 잘못된 공유 가능성.
시스템 콜 횟수 –
strace -c로futex()호출을 셉니다. 초당 수백만 건이면 경쟁이 심한 락이며, 샤딩이나 락‑프리 기법을 고려할 수 있습니다.자발적 vs. 비자발적 스위치 –
/proc/<pid>/status를 확인합니다. 스핀락을 보유한 상태에서 비자발적 스위치가 발생하면 선점 문제를 나타냅니다.
실제 사례
Redis – 작은 작업 큐(임계 구역)에서 스핀락을 사용합니다.
#include <pthread.h> #include <stdatomic.h> #define NUM_THREADS 4 #define ITERATIONS 1000000 #define HOLD_TIME_NS 100 // simulated work typedef struct { atomic_int lock; long counter; } spinlock_t; static void spinlock_acquire(spinlock_t *s) { int expected; do { expected = 0; } while (!atomic_compare_exchange_weak(&s->lock, &expected, 1)); } static void spinlock_release(spinlock_t *s) { atomic_store(&s->lock, 0); } static void *worker_thread(void *arg) { spinlock_t *s = (spinlock_t *)arg; for (long i = 0; i < ITERATIONS; i++) { spinlock_acquire(s); s->counter++; /* Simulate ~100 ns of work */ for (volatile int j = 0; j < HOLD_TIME_NS; j++) { // busy‑wait } spinlock_release(s); } return NULL; }
삽화