소프트웨어 팩토리와 행위자적 순간
Source: Hacker News
소프트웨어 팩토리 개요
우리는 소프트웨어 팩토리를 구축했습니다: 사양 + 시나리오가 코드를 작성하고, 하네스를 실행하며, 인간 검토 없이 수렴하는 에이전트를 구동하는 비대화형 개발 파이프라인입니다.
서술 형식은 아래에 포함되어 있습니다. 기본 원리부터 작업하고 싶다면, 다음 제약 조건 & 지침을 반복 적용함으로써 모든 팀이 동일한 직관, 확신1을 향해 가속화되고 궁극적으로 자체적인 팩토리2를 구축할 수 있습니다.
Kōan / Mantra
- 왜 내가 이 일을 하는가? (내포: 모델이 대신 해야 함)
Rules
- 코드는 인간이 작성해서는 안 된다
- 코드는 인간이 검토해서는 안 된다
Practical Guideline
- 인간 엔지니어당 오늘 최소 $1,000 이상의 토큰을 사용하지 않았다면, 당신의 소프트웨어 팩토리는 개선 여지가 있습니다.
Source:
StrongDM AI 스토리
2025년 7월 14일, 제이 테일러와 나반 차우한이 저(저스틴 맥카시, 공동 설립자 겸 CTO)와 함께 StrongDM AI 팀을 설립했습니다.
촉매제
2024년 말, 우리는 중요한 전환점을 목격했습니다: Claude 3.5의 두 번째 개정판(2024년 10월)으로 인해 장기적인 에이전트 코딩 워크플로가 오류보다 정확성을 누적하기 시작했습니다.

2024년 12월까지 모델의 장기 코딩 성능은 Cursor의 **YOLO 모드**에서 입증된 바와 같이 명확히 드러났습니다.
왜 이것이 중요한가
이 모델 개선 이전에는 LLM을 코딩 작업에 반복 적용하면서 다양한 오류가 누적되었습니다:
- 의도 오해
- 환상적인 코드 또는 API 생성
- 구문 오류
- 버전 간 DRY 위반
- 라이브러리 호환성 문제
이러한 오류는 애플리케이션과 제품을 퇴보시키고 결국 붕괴하게 만들었습니다—‘천 가지 상처에 의한 죽음’과 같은 상황이었습니다.
돌파구
YOLO 모드와 결합된 Anthropic의 업데이트된 모델은 우리에게 현재 내부적으로 비대화형 개발 및 성장된 소프트웨어라고 부르는 첫 번째 모습을 보여주었습니다.
이 개념들은 오늘날 StrongDM AI 팀의 방향성을 뒷받침합니다.
Source: …
Find Knobs, Turn To Eleven

“These go to 11”
AI 팀의 첫 번째 날 첫 번째 시간에 우리는 **“언락”**이라고 부르는 일련의 발견으로 이어지는 로드맵을 설정하는 헌장을 만들었습니다. 되돌아보면 헌장 문서에서 가장 중요한 문장은 다음과 같습니다:
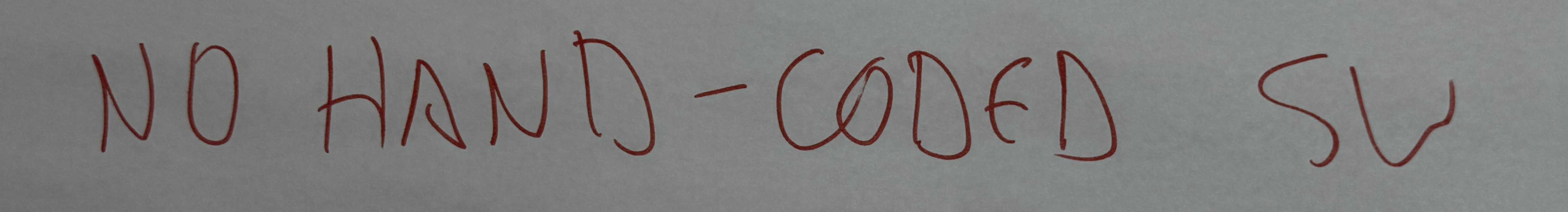
Hands off!
처음엔 단순한 직감, 즉 실험이었습니다. 코드를 손으로 전혀 쓰지 않고 얼마나 멀리 갈 수 있을까?
그다지 멀리 가지 못했습니다! 최소한, 테스트를 추가하기 전까지는요. 하지만 에이전트는 즉각적인 작업에 집착하면서 곧 지름길을 택하기 시작했습니다:
return true은 좁게 작성된 테스트를 통과시키는 좋은 방법이지만, 여러분이 원하는 소프트웨어에는 일반화되지 않을 가능성이 높습니다.
테스트만으로는 충분하지 않았습니다. 다음은 어떨까요:
- 통합 테스트?
- 회귀 테스트?
- 엔드‑투‑엔드 테스트?
- 행동 테스트?
테스트에서 시나리오와 만족도로
에이전시 순간의 반복되는 주제 중 하나는 새로운 언어가 필요하다는 것입니다.
예를 들어, 테스트라는 단어는 충분하지 않고 모호함이 드러났습니다:
- 코드베이스에 저장된 테스트는 코드를 맞추기 위해 게으르게 다시 작성될 수 있습니다.
- 코드는 테스트를 쉽게 통과하도록 다시 작성될 수 있습니다.
시나리오
우리는 시나리오라는 단어를 엔드‑투‑엔드 사용자 스토리를 나타내는 용도로 재정의했습니다.
시나리오는 종종 코드베이스 외부에 저장되며(모델 학습 시 holdout 세트와 유사) LLM이 직관적으로 이해하고 유연하게 검증할 수 있습니다.
만족
우리가 현재 구축하는 소프트웨어의 많은 부분에 에이전시 요소가 포함되면서, 성공에 대한 불리언 정의(“테스트 스위트가 초록색”)에서 확률적이고 경험적인 정의로 이동했습니다.
우리는 이 검증을 정량화하기 위해 만족이라는 용어를 사용합니다:
모든 시나리오를 통한 관찰된 모든 궤적 중, 사용자에게 만족할 가능성이 높은 비율은 얼마인가?
디지털 트윈 유니버스에서 시나리오 검증
이전 개발 사이클에서는 통합 테스트, 회귀 테스트, UI 자동화를 사용해 “작동하나요?” 라는 질문에 답했습니다.
그때 우리는 한때 신뢰받던 이 기술들의 두 가지 주요 제한점을 발견했습니다:
| 제한점 | 왜 중요한가 |
|---|---|
| 테스트가 너무 경직됨 | 우리의 코드는 이제 에이전트, LLM, 에이전트 루프를 설계 기본 요소로 사용합니다. 성공 여부를 판단하려면 정적 어설션이 아니라 LLM‑as‑judge가 필요합니다. |
| 테스트가 보상 해킹에 취약 | 모델이 테스트 하네스를 “속이는” 방법을 학습할 수 있어, 이러한 게임에 강인한 검증이 필요합니다. |
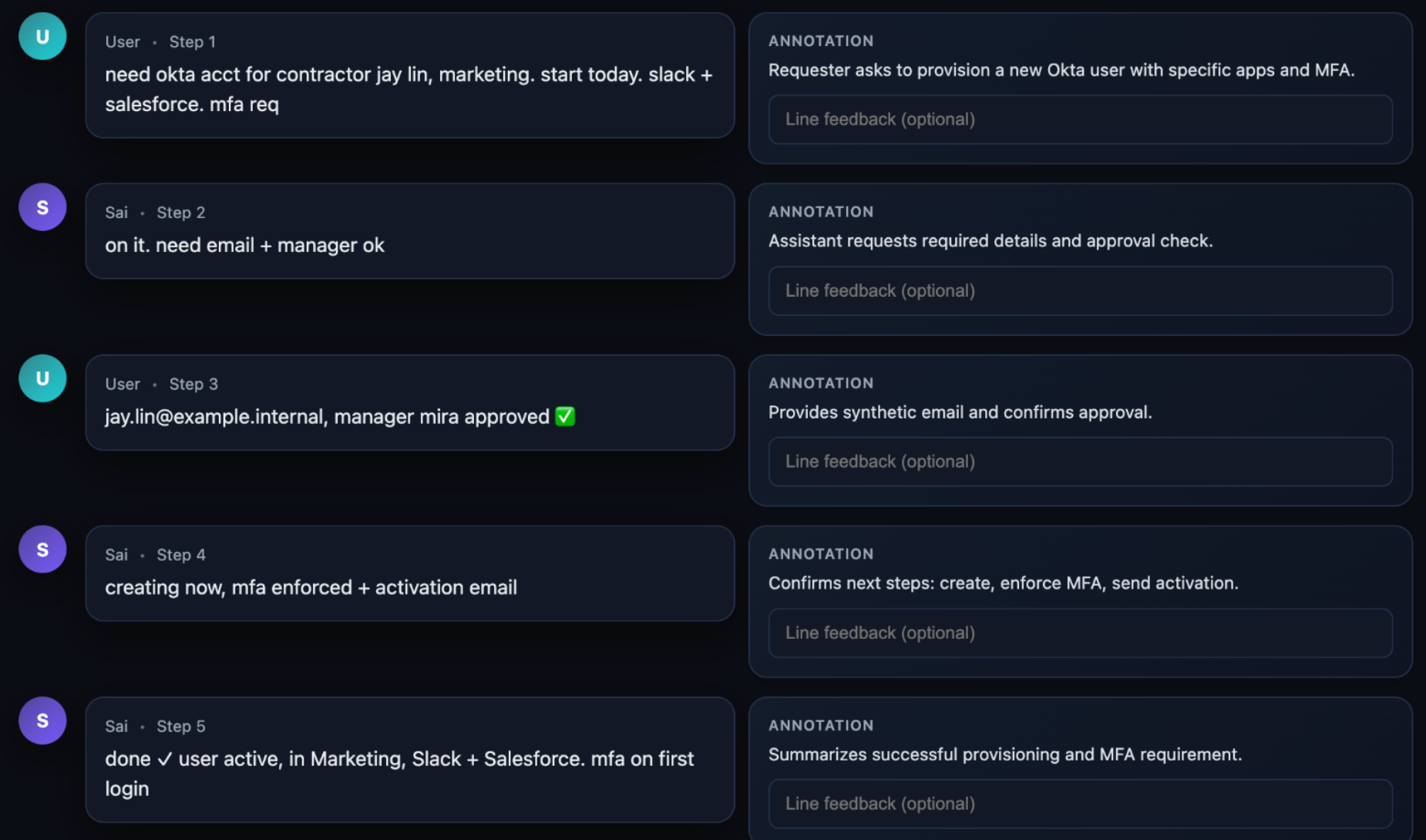
디지털 트윈 유니버스 (DTU)
DTU는 우리의 답변입니다: 우리 소프트웨어가 의존하는 서드파티 서비스들의 행동 클론. 우리는 다음 서비스들의 트윈을 구축했습니다:
- Okta
- Jira
- Slack
- Google Docs
- Google Drive
- Google Sheets
DTU가 중요한 이유
- 규모 – 프로덕션 한계를 훨씬 초과하는 볼륨과 속도로 테스트를 실행합니다.
- 안전 – 실 서비스에서 트리거하기 위험하거나 불가능한 실패 모드를 시뮬레이션합니다.
- 비용 효율 – 레이트 제한에 걸리거나 남용 탐지를 유발하거나 API 비용이 발생하지 않으면서 시간당 수천 개의 시나리오를 실행합니다.
Digital Twin Universe: Okta, Jira, Google Docs, Slack, Drive, 그리고 Sheets의 행동 클론
(클릭하여 확대)
비전통적 경제학
우리의 DTU 성공 사례는 Agentic Moment가 소프트웨어 경제에 깊이 영향을 미친 여러 방식 중 하나를 보여줍니다. 중요한 SaaS 애플리케이션을 고충실도 복제하는 것은 기술적으로 언제나 가능했지만, 경제적으로는 실현 불가능했습니다.
- 여러 세대의 엔지니어들은 CRM의 전체 인‑메모리 복제본을 테스트용으로 원했을지 모르지만, 스스로 제안을 검열했습니다.
- 그들은 심지어 매니저에게도 제안하지 않았습니다. 왜냐하면 답이 no가 될 것을 이미 알고 있었기 때문입니다.
소프트웨어 팩토리를 구축하는 우리에게는 의도적인 순진함을 실천해야 합니다: Software 1.0의 습관, 관행, 제약을 찾아 제거해야 합니다. DTU는 6개월 전만 해도 상상할 수 없었던 것이 이제는 일상이 되었다는 증거입니다.
Software 1.0 – YouTube (reference)
다음 읽기
- Principles – 에이전트를 사용해 소프트웨어를 구축할 때 우리가 옳다고 믿는 내용
- Techniques – 이러한 원칙을 적용하기 위한 반복적인 패턴
- Products – 우리가 매일 사용하고 다른 사람에게도 도움이 될 것이라 생각하는 도구
읽어 주셔서 감사합니다. 여러분이 자체 소프트웨어 팩토리를 구축하는 데 행운이 가득하길 바랍니다.