Show HN 제출이 세 배가 되었고 이제 대부분 같은 vibe-coded 모습을 공유합니다
Source: Hacker News
Hacker News를 탐색하면서 요즘 많은 Show HN 프로젝트들이 일종의 일반적이고 무미건조한 느낌을 가지고 있어, 순수히 AI가 만든 것이라는 직감을 받았습니다. 처음엔 정확히 무엇이 그런지 알 수 없었지만, 500개의 Show HN 페이지를 AI 디자인 패턴으로 점수 매겨 이 주관적인 느낌을 자동으로 정량화할 수 있을지 궁금해졌습니다.
Claude Code 덕분에 Show HN 프로젝트가 크게 증가했으며, 그 결과 HN 운영진은 새로운 계정에 대해 Show HN 제출을 제한해야 할 정도였습니다.
지난 몇 년간 Show HN 제출이 어떻게 증가했는지 살펴보면 다음과 같습니다:

이제 AI 디자인 패턴을 평가할 충분한 페이지가 확보되었습니다.
Source: …
AI 디자인 패턴
디자이너 한 명이 최근에 “왼쪽에 색이 들어간 테두리는 텍스트의 em‑dash만큼 AI‑생성 디자인을 나타내는 신호다”라고 말했어요. 그래서 저는 여러 페이지에서 그런 테두리를 눈에 띄게 보게 되었죠. 다른 디자이너들에게 물어보니, 흔히 보이는 AI 패턴은 대략 폰트, 색상, 레이아웃 특이점, 그리고 CSS 패턴으로 구분할 수 있었습니다.
폰트
- 모든 요소에 Inter 사용, 특히 가운데 정렬된 히어로 헤드라인
- LLM은 Space Grotesk, Instrument Serif, Geist 같은 특정 폰트 조합을 자주 사용
- 기본이 Inter인 히어로 안에서 강조 단어 하나에 Serif 이탤릭 적용
색상
- “VibeCode 퍼플”
- 중간 회색 본문 텍스트와 전체 대문자 섹션 라벨을 사용하는 영구 다크 모드
- 다크 테마에서 거의 기준에 못 미치는 본문 텍스트 대비
- 모든 요소에 그라디언트 적용
- 큰 색상 글로우와 색상 박스‑쉐도우
레이아웃 특이점
- 일반적인 산세리프로 설정된 가운데 정렬 히어로
- 히어로 H1 바로 위에 배치된 배지
- 카드 상단 또는 왼쪽 가장자리에 색상 테두리
- 아이콘이 위에 있는 동일한 형태의 피처 카드들
- “1, 2, 3” 순서 번호가 매겨진 단계 시퀀스
- 통계 배너 행
- 이모지 아이콘이 있는 사이드바 또는 내비게이션
- 전체 대문자 헤딩 및 섹션 라벨
CSS 패턴
shadcn/ui- 글래스모피즘
예시 스크린샷
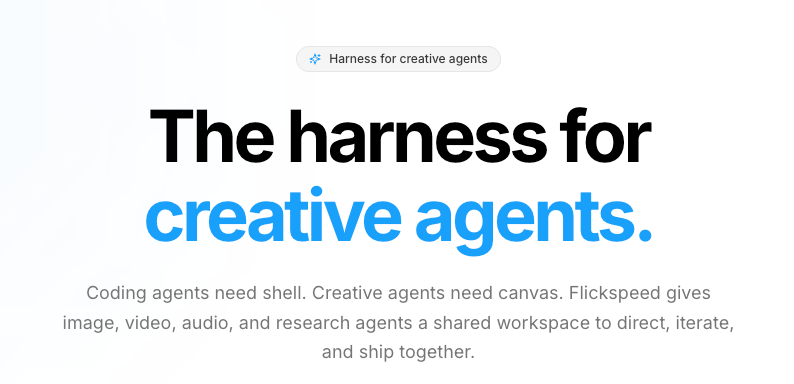
Inter 히어로 위에 배치된 배지.

같은 형태, 다른 페이지.
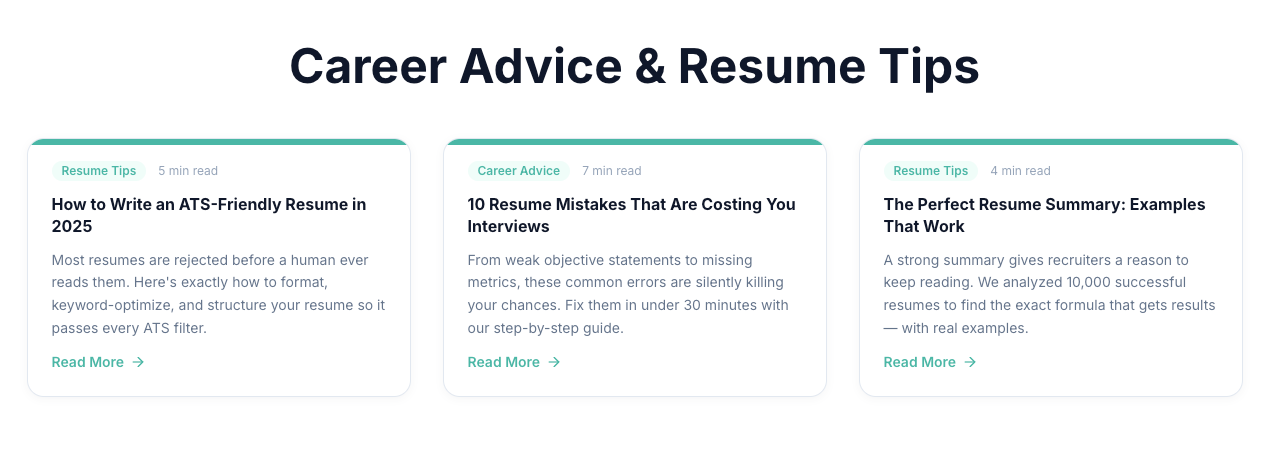
상단에 색상 테두리 스트립이 있는 카드.
![]()
아이콘이 위에 있는 피처 카드 그리드.
그라디언트 배경 + 글래스모피즘 카드.
Show HN 제출물에서 AI 디자인 감지
이러한 패턴을 체계적으로 점수화하기 위해 최신 Show HN 제출물 500개를 처리하고, 해당 랜딩 페이지를 위 목록과 비교하여 평가했습니다.
점수 매기기 방법
- 헤드리스 브라우저가 각 사이트를 로드합니다 (Playwright).
- 페이지 내 작은 스크립트가 DOM을 분석하고 계산된 스타일을 읽습니다.
- 모든 패턴은 결정론적인 CSS 또는 DOM 검사이며, 스크린샷은 찍지 않고 LLM이 판단하지 않습니다.
이 접근 방식은 불가피하게 오탐을 발생시키지만, 수동 QA에 따르면 오류율은 대략 5–10 % 정도입니다.
점수 매기기 코드를 오픈소스로 공개하여 실행을 재현(또는 개선)하고 싶다면 알려 주세요.
결과
- Heavy slop (5 + 패턴) – 105 사이트 – 21 %
- Mild (2–4 패턴) – 230 사이트 – 46 %
- Clean (0–1 패턴) – 165 사이트 – 33 %
이게 나쁜가요? 그렇지는 않습니다—그냥 영감이 부족한 것일 뿐입니다. 비즈니스 아이디어를 검증하는 일은 언제나 화려한 디자인과는 무관했으며, AI 시대 이전에도 모든 것이 Bootstrap처럼 보였습니다. 직접 디자인을 만드는 것과 LLM이 출력하는 기본값을 그대로 사용하는 것 사이에는 차이가 있습니다. 이는 CSS/HTML 템플릿을 사용할 때의 LLM 이전 시절과도 마찬가지입니다.
사람들은 결국 눈에 띄는 아름다운 디자인을 만들기 위해 다시 돌아올 것이라고 생각합니다. 반면, AI 에이전트가 웹의 주요 사용자가 되면 디자인이 얼마나 중요한지는 아직 불분명합니다.
이 게시물은 사람이 작성했으며, 점수 매기기와 분석은 AI의 도움을 받았습니다.