Show HN: Steerling-8B, 생성하는 모든 토큰을 설명할 수 있는 language model
Source: Hacker News
작성자: Guide Labs Team
게시일: 2026년 2월 23일
우리는 Steerling‑8B를 출시합니다. 이는 생성하는 모든 토큰을 입력 컨텍스트, 인간이 이해할 수 있는 개념, 그리고 학습 데이터와 연결할 수 있는 최초의 해석 가능한 모델입니다.
- 학습 데이터: 1.35 trillion tokens
- 성능: 2–7 × 더 많은 데이터로 학습된 모델과 비교 가능
Key capabilities
- Concept steering at inference: 재학습 없이 특정 개념을 억제하거나 증폭합니다.
- Training‑data provenance: 생성된 텍스트 조각에 대한 원본 데이터를 검색합니다.
- Inference‑time alignment: 개념을 직접 제어하여 수천 개의 안전 학습 예시를 명시적인 개념 수준 스티어링으로 대체합니다.
모델 개요
처음으로 80억 파라미터 규모의 언어 모델이 생성하는 모든 토큰을 세 가지 핵심 방식으로 설명할 수 있게 되었습니다. 구체적으로, Steerling이 생성하는 출력 토큰 그룹에 대해 우리는 해당 토큰들을 다음과 같이 추적할 수 있습니다:
- [입력 컨텍스트] – 프롬프트 토큰
- [개념] – 모델 표현 안에서 인간이 이해할 수 있는 주제
- [학습 데이터] – 출력을 유도한 학습 데이터
아티팩트
우리는 1.35 T 토큰으로 학습된 기본 모델의 가중치와 모델과 상호작용하고 탐색할 수 있는 부수 코드를 공개합니다.
Steerling‑8B 작동 예시
아래에서는 Steerling‑8B가 다양한 카테고리의 프롬프트에서 텍스트를 생성하는 모습을 보여줍니다. 예시를 선택한 뒤 출력된 텍스트에서 강조된 청크를 클릭하면, 아래 패널이 업데이트됩니다:
- 입력‑특성 기여도: 해당 청크에 강하게 영향을 미친 입력 프롬프트의 토큰들.
- 개념 기여도: 모델이 해당 청크를 생성하기 위해 거친 개념들의 순위 목록—톤(예: 분석적, 임상적)과 내용(예: 유전‑변형 방법론) 모두 포함.
- 학습‑데이터 기여도: 해당 청크에 포함된 개념들이 학습 소스(ArXiv, Wikipedia, FLAN 등) 전반에 어떻게 분포되어 있는지, 모델 지식의 출처를 보여줍니다.
탐색기 로드 중…
Source: https://www.guidelabs.ai/post/block-causal-diffusion-language-model/
모델 아키텍처
Steerling은 causal discrete diffusion model 백본 위에 구축되었으며, 이를 통해 다중 토큰 구간 전체에 걸쳐 생성을 조정할 수 있습니다. 다음 토큰만을 조정하는 것이 아니라 말이죠.
핵심 설계 선택은 모델의 임베딩을 세 가지 명시적인 경로로 분해하는 것입니다:
- ~33 K개의 감독된 “알려진” 개념 – 학습 중에 제공된 큐레이션된 개념.
- ~100 K개의 “발견된” 개념 – 모델이 자율적으로 학습한 패턴.
- 잔차(Residual) – 앞의 두 경로가 포괄하지 못한 나머지 정보를 포착.
그 후 우리는 훈련 손실 함수를 통해 모델이 성능을 희생하지 않으면서 개념을 통해 신호를 전달하도록 제약합니다. 개념들은 선형 경로를 통해 로짓에 입력되므로, 모든 예측은 정확히 개념별 기여도로 분해되며, 추론 시 재학습 없이도 해당 기여도를 편집할 수 있습니다.
전체 아키텍처, 훈련 목표 및 스케일링 분석에 대해서는 Scaling Interpretable Models to 8B 를 참고하세요.
성능
비교 가능한 모델들보다 훨씬 적은 연산 자원으로 학습했음에도 불구하고 Steerling‑8B는 표준 벤치마크 전반에서 경쟁력 있는 결과를 달성합니다.
평균 성능 vs. 학습 FLOPs
아래 산점도는 로그 스케일의 대략적인 학습 FLOPs에 대해 7개 벤치마크 평균 성능을 표시합니다. 수직선은 Steerling의 연산 예산 배수를 나타냅니다.
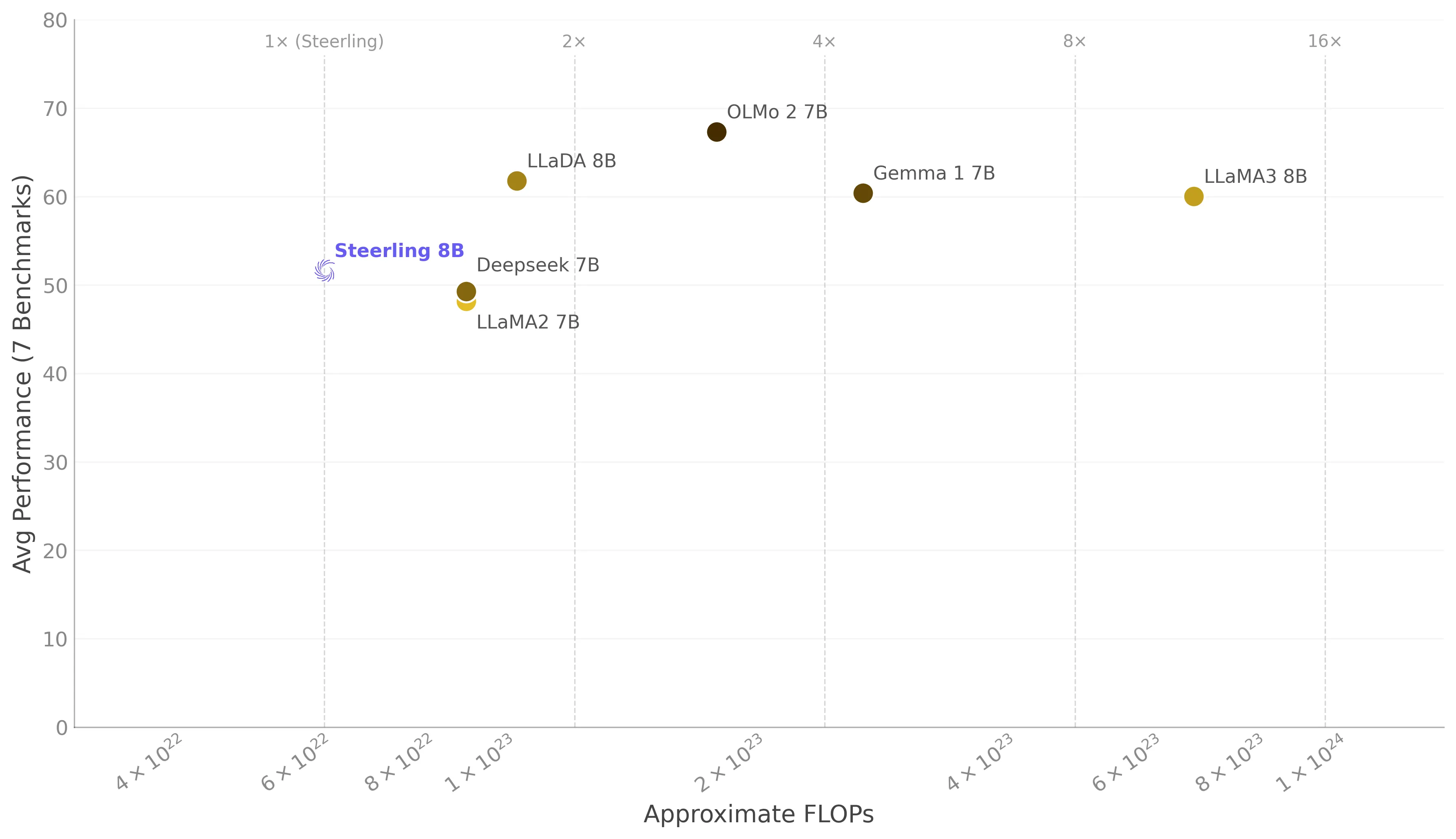
Steerling은 더 적은 FLOPs를 사용하면서도 전체 평균에서 LLaMA2‑7B와 DeepSeek‑7B 모두를 능가하며, 2–10배 더 많은 연산으로 학습된 모델들의 범위 안에 머무릅니다.
작업 카테고리별 그룹 평균 성능
아래 막대 차트는 General과 Math 작업 카테고리의 그룹 평균 점수를 비교합니다.

Steerling의 성능은 일반적인 질문 응답부터 추론 및 수학을 강조하는 작업에 이르기까지 다양한 벤치마크에 걸쳐 나타납니다.
Source: https://www.guidelabs.ai/post/scaling-interpretable-models-8b/
해석 가능성
이전 업데이트에서 우리는 모델 표현이 얼마나 해석 가능한지 평가하는 여러 방법을 공유했습니다. 여기서는 모델이 개념을 어떻게 활용하는지에 대한 통찰을 제공하는 또 다른 지표를 추가합니다.
개념‑모듈 기여도
- 보유‑검증 세트에서 > 84 %의 토큰‑레벨 기여도가 개념 모듈에서 나옵니다.
- 이는 모델이 예측을 할 때 잔차 경로에만 의존하는 것이 아니라는 것을 보여줍니다.
왜 중요한가:
예측이 실제로 개념을 통해 흐른다면, 추론 시점에 해당 개념을 편집함으로써 모델의 행동을 변화시킬 수 있습니다. 반대로 “실제 작업”이 다른 곳에서 이루어지고 있다면 개념을 바꾸어도 부수적인 채널만 살짝 움직이는 수준에 그칩니다.

보유‑검증 세트에서 Steerling‑8B의 토큰‑레벨 로짓 분포.
잔차‑경로 제거 실험
유용한 검증 방법으로 잔차 경로를 완전히 제거해 볼 수 있습니다:
- 여러 LM‑Harness 과제에서 잔차를 없애면 성능에 미치는 영향이 작았습니다.
- 이는 모델의 예측 신호가 일반적인 “기타 모든 것” 채널보다 개념을 통해 전달되는 비중이 크다는 것을 시사합니다.

잔차 부분을 포함했을 때와 제외했을 때 다양한 벤치마크에서 모델 성능 변화.
개념 탐지
- Steerling은 보유‑검증 데이터셋에서 96.2 % AUC로 텍스트 내 알려진 개념을 탐지할 수 있습니다.
모든 수치는 Steerling‑8B 모델에 대한 실험 결과입니다.
What this unlocks
앞으로 몇 주 안에, 우리는 각각의 기능에 대한 심층 분석을 공개할 예정입니다:
- Concept steering – 개입을 통한 정밀 제어.
- Concept discovery – Steerling이 우리가 가르치지 않은 것을 무엇을 배웠을까? 발견된 개념 공간을 열어 놀라운 구조를 보여줄 것입니다.
- Alignment without fine‑tuning – 수천 개의 안전 교육 예시를 소수의 개념 수준 개입으로 대체합니다.
- Memorization & training‑data valuation – 모든 생성 결과를 그것을 만든 학습 데이터로 추적하고 개별 데이터 소스에 가치를 부여합니다.
- The case for inherent interpretability – 처음부터 해석 가능성을 설계했을 때 얻는 이점과 나중에 추가했을 때 놓치는 점을 논의합니다.
우리는 앞으로의 포스트에서 각 항목을 자세히 다루며, 정량적 평가와 배포 중심 사례 연구를 제공할 것입니다.