AI 기반 대화를 10K에서 100K로 확장하면서 실시간 일관성 유지
Source: Salesforce Engineering
작성자: Ashima Kochar와 Deepak Mali.
팀의 미션은 무엇이며, Conversation Storage Service (CSS)가 Service Cloud의 AI‑구동 고객 참여를 어떻게 지원하나요?
CSS는 단순한 저장 시스템이 아니라 대화 컨텍스트의 진실된 원본이며, 이는 실시간 AI 시스템(예: 감정 분석, 에이전트 지원, 관리자 인사이트)을 직접 구동합니다. CSS는 확장 가능하고 신뢰할 수 있는 기반을 제공하여 디지털 채널 전반에 걸친 상호작용을 영구적으로 보관하고 거의 실시간에 가깝게 검색할 수 있게 합니다.
CSS를 구축하는 팀은 Service Cloud 내에서 AI‑구동 참여를 가능하게 하는 대화 데이터를 위한 확장 가능하고 신뢰할 수 있는 기반을 만들고 있습니다. 이 플랫폼은 디지털 채널 전반의 모든 상호작용을 지속적으로 보관하면서, 데이터가 하위 시스템에 거의 즉시 제공되도록 보장합니다.
유기적인 데이터 성장과 Agentforce 및 CcaaS 채택이 확대됨에 따라, 워크로드는 동시 대화 50 000건을 지원해야 하며 피크 시에는 100 000건을 목표로 해야 합니다. 이러한 상호작용은 더 큰 페이로드, 더 긴 스레드, 그리고 실시간 접근성에 대한 높은 기대치를 동반합니다.
이 규모는 **Unified Agentic Communication Platform (UACP)**의 기반을 이루며, 채널과 에이전트 전반에 걸쳐 일관되고 순서가 보장된 컨텍스트를 가진 통합 대화를 가능하게 합니다. CSS는 고처리량 수집과 저지연 검색에 중점을 두어 Data 360, Core, AI 파이프라인에 정확한 데이터를 제공하고, 인간 에이전트와 AI 에이전트 모두가 완전하고 최신의 상호작용 뷰를 기반으로 작동하도록 보장합니다.
What constraints emerged as CSS scaled to support high‑volume conversational workloads across distributed systems?
- CSS는 10 000개 이상의 동시 대화 한도를 초과하면서 제한에 부딪혔습니다. 이는 Postgres- 기반 시스템이 활동이 많은 테넌트의 급증 트래픽을 감당하지 못했기 때문입니다. 이러한 급증은 핫스팟을 만들고 플랫폼 전체의 쓰기 성능을 저하시켰습니다.
- 이를 해결하기 위해 팀은 수평 확장된 No‑SQL DB로 전환하여, 인제스트 속도가 증가함에 따라 테넌트 수준에서 애플리케이션 레이어의 이벤트를 버퍼링하고 배치 처리하도록 했습니다.
- 또한 대화 수준 파티셔닝을 적용한 Kafka를 도입해 부하를 보다 고르게 분산시켰으며, 스토리지에 도달하기 전에 스파이크를 완화했습니다.
이 전환에도 트레이드오프가 있었습니다. 비동기 처리로 인해 쓰기와 읽기 사이에 지연이 발생했으며, 이러한 read‑after‑write 간격이 에이전트 워크플로에 영향을 줄 수 있었습니다. 그래서 팀은 VegaCache를 추가해 최신 쓰기를 바로 제공하고 영속성이 따라잡히도록 했습니다.
이러한 변경으로 CSS는 처리량을 효과적으로 확장할 수 있게 되었습니다. 이제 시스템은 더 빠른 read‑after‑write 일관성을 유지하고 AI 기반 대화 워크로드에 대한 실시간 인사이트를 제공합니다.
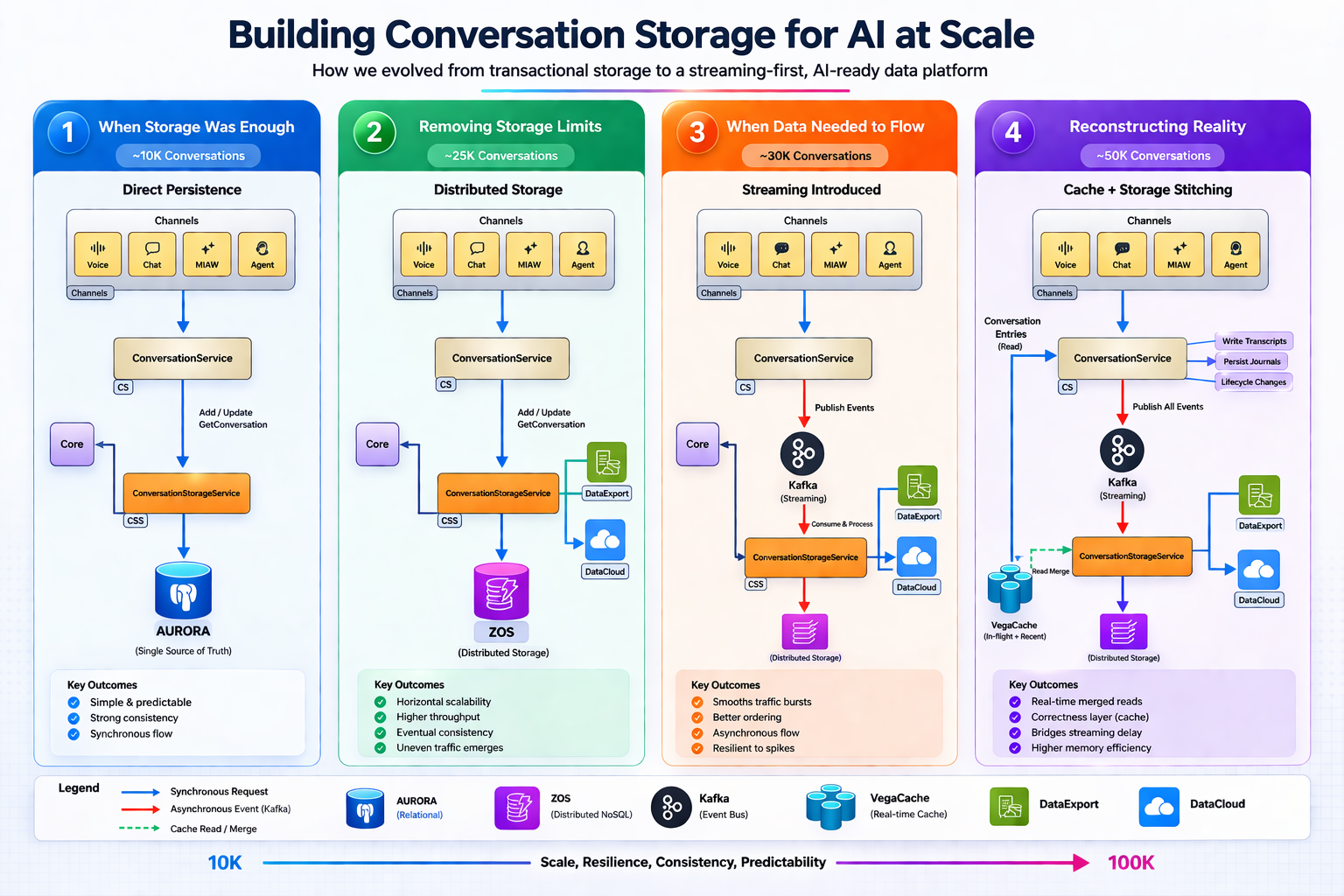
10 K에서 50 K, 그리고 100 K 동시 대화로 이동하면서 CSS 아키텍처에 영향을 미친 규모 압력은 무엇인가요?
대화 플랫폼은 UACP 북스타와 CSS 목표를 달성하기 위해 아키텍처 진화를 겪었습니다. 각 규모 전환점마다 특정 제한 사항이 드러났으며, 이는 이후 설계 결정에 영향을 주었습니다.
| 규모(동시) | 주요 과제 | 아키텍처 대응 |
|---|---|---|
| ~10 000 | 트랜잭션 시스템이 잘 작동함 | 기본 설계 |
| ~25 000 | 트래픽 불균형—특정 테넌트가 과도한 부하를 생성함 | 분산 스토리지로 전환 |
| ~30 000 | 인제스트 안정화 필요 | 버퍼링 및 배치 처리를 위해 Kafka 추가 |
| ~50 000 | 비동기 파이프라인 지연이 실시간 워크플로에 영향 | 읽기‑쓰기 일관성을 위해 VegaCache 도입 |
| ~100 000 (목표) | 추가 지연 및 진실 소스 문제 | curated Kafka로 전환 – 대화 스트림을 순차적인 진실 소스로 만들고 여러 스토리지 계층에 대한 의존성을 감소 |
AI 기반 대화 작업량이 증가하면서 어떤 복잡성이 나타났나요? (볼륨, 페이로드 크기, 실시간 기대치)
AI 기반 대화 작업량은 데이터의 양과 복잡성을 크게 증가시켰습니다. 현대의 상호작용은 이제 다음을 포함합니다:
- 더 긴 대화와 더 큰 페이로드(예: 대화형 이메일, 음성 전사, AI 생성 응답).
- 인간 에이전트와 자동화 시스템 모두를 위한 실시간에 가까운 접근 요구 사항으로, 낮은 지연 시간과 일관된 검색이 필수적입니다.
이러한 과제를 해결하기 위해 CSS는 여러 데이터 효율성 및 접근성 최적화를 도입했습니다:
- 압축 – 대용량 페이로드에 대한 저장 공간과 네트워크 대역폭을 감소시킵니다.
- 페이지네이션 – 긴 대화를 관리 가능한 세그먼트로 가져옵니다.
- VegaCache – 비동기 스트리밍으로 인한 지연을 가리고, 최신 업데이트를 즉시 확인할 수 있게 합니다.
이러한 개선을 통해 CSS는 동시 100 000개 대화라는 플랫폼 전체 목표를 지원하며, AI 기반 에이전트와 인간 사용자가 각 상호작용에 대해 완전하고 최신의 뷰를 유지하도록 합니다.
Vice Cloud Modernized Platform (SCRT2) Components
- CS는 고처리량 수집을 가능하게 합니다.
- Ajna는 흐름을 안정화합니다.
- ZOS는 스토리지를 확장합니다.
- VegaCache는 실시간 가시성을 유지합니다.
이들이 함께 지연 시간이나 일관성을 해치지 않으면서 예측 가능한 확장을 보장합니다.
실시간 대화 이벤트를 대규모로 수집할 때 CSS 스트리밍 파이프라인에서 어떤 제한 사항이 나타났나요?
- 소비자 지연이 수집량이 분당 30,000 이벤트를 초과할 때 주요 과제로 떠올랐습니다.
- 과부하가 발생하면 이벤트가 큐에 쌓여 데이터 영속화가 지연되고, 정보 접근에 공백이 생깁니다.
- 이러한 지연은 즉시 데이터를 필요로 하는 에이전트 작업 및 AI 시스템을 방해할 수 있습니다.
도입된 완화 방안
- VegaCache가 최신 쓰기를 즉시 제공하여 스트리밍 지연을 가립니다.
- 대화 파티셔닝, 배치 처리, 역압(Back‑pressure) 제어를 통해 핫스팟을 감소시키고 데이터 흐름을 안정화합니다.
이 업데이트들은 트래픽 급증을 처리하면서 AI 워크로드의 일관성을 유지하도록 파이프라인을 돕습니다. UACP의 일환으로, 이 스트리밍 파이프라인은 **Unified Communication Services (UCP)**의 핵심이며, 여러 채널의 메시지를 하나의 대화 흐름으로 통합하면서 대규모에서도 일관된 수집을 보장합니다.
CSS 데이터를 Data 360, Core 보고, AI 파이프라인 등 하위 시스템에 신뢰성 있게 제공하기 위해 어떤 통합 제약을 겪었나요?
- 다양한 하위 시스템 포맷 때문에 스키마 매핑 및 데이터 변환에 어려움이 있었습니다.
- 모든 상호작용 유형에 대해 데이터 레이크 객체와 데이터 모델 객체를 정의하는 것이 통합을 느리고 무겁게 만들었습니다.
해결책
- 새로운 데이터 유형 추가를 간소화하고 수동 스키마 작업을 없애는 메타데이터 기반 통합 레이어를 구축했습니다.
- CSS는 S3를 통한 대량 내보내기도 지원하여 대규모 분석에 활용할 수 있습니다.
이를 통해 CSS는 단순 저장 시스템을 넘어 데이터 배포 레이어 역할을 수행하며, 운영, 분석, AI 워크로드를 동시에 지원합니다.
자세히 알아보기
- 연결을 유지하세요 — 우리의 Talent Community에 참여하세요!
- 우리의 Technology and Product 팀을 확인하고 참여 방법을 알아보세요.