SageMaker Unified Studio: 당신의 올인원 AWS 분석 플랫폼
Source: Dev.to
Overview
SageMaker Unified Studio(이후 SUS라고 약칭) 는 기존의 개별 AWS 분석 서비스에 익숙한 사용자에게는 다소 혼란스러울 수 있습니다—왜냐하면 이미 알고 있는 모든 서비스를 하나로 묶어 제공하기 때문입니다:
| Service | Purpose |
|---|---|
| S3 | 스토리지 |
| Lake Formation | 세밀한 권한 관리가 가능한 데이터 거버넌스 |
| Glue | Spark 워크로드 및 데이터 카탈로그 관리 |
| Redshift | 데이터 웨어하우스 |
| Athena | 즉석 SQL 쿼리 |
| SageMaker Notebook | Python 스크립트 실행 또는 Glue Interactive Sessions 연결 |
| Bedrock | 생성형 및 에이전트형 AI 컴포넌트 |
| Amazon Q | AI 지원 코드 생성 (SQL 및 Python) |
| DataZone | 비즈니스 카탈로그, 프로젝트 관리, 도메인 간 데이터 공유 |
| EMR | Spark 기반 대규모 데이터 처리 |
이러한 구성 요소들은 데이터, 컴퓨팅 및 보안에 대한 운영 및 거버넌스 오버헤드를 추가하며, 종종 서로 독립된 사일로 형태로 존재합니다.
왜 레이크하우스 아키텍처인가?
문제
왜 레이크하우스 아키텍처에 대해 이야기하고 있는지 궁금할 수도 있습니다. 이는 여러분이 겪어봤을 큰 고통점을 해결해 줍니다.
우리가 모두 겪어온 전통적인 혼란
시나리오 1 – 데이터 레이크 접근법
- 모든 데이터를 S3에 덤프 (저렴한 스토리지 ✅)
- 분석을 실행해야 함…
- 성능이 끔찍함 ❌
- ACID 트랜잭션 없음 ❌
- 데이터 품질 보장? 행운을 빕니다! ❌
결과: 실제 분석을 위해 데이터를 Redshift로 복사.
시나리오 2 – 데이터 웨어하우스 접근법
- 모든 것을 Redshift에 로드 (우수한 성능 ✅)
- 스토리지 비용 급증 💸
- 반구조화 데이터 처리 어려움 ❌
- ML 팀은 어쨌든 S3에 원시 데이터를 원함 ❌
결과: 중복 데이터를 가지고 S3와 Redshift를 모두 유지.
실제 문제들
| 문제 | 영향 |
|---|---|
| 데이터 중복 | 동일한 데이터를 여러 번 비용을 지불 |
| 복잡한 ETL 파이프라인 | 시스템 간 데이터 이동 |
| 다중 권한 모델 | 서비스 전반의 보안 관리 |
| 일관성 없는 데이터 | 신뢰 문제 |
| 느린 인사이트 도출 시간 | 오버헤드 지연 |
| 높은 운영 비용 | 중복 인프라 |
익숙한가요? 바로 이것이 SageMaker Unified Studio가 레이크하우스 아키텍처 구현을 위한 통합 플랫폼을 제공하는 이유입니다.
솔루션: 레이크하우스 아키텍처
Lakehouse architecture는 두 세계의 장점을 결합합니다:
Data Lake + Data Warehouse = Lakehouse
“데이터 레이크하우스는 데이터 레이크의 확장성 및 비용 효율성과 데이터 웨어하우스의 성능 및 신뢰성을 통합하는 아키텍처입니다. 이 접근 방식은 다양한 데이터 유형을 저장하면서 분석 워크로드에 대한 쿼리 성능을 유지하는 전통적인 트레이드오프를 없애줍니다.” — AWS 문서
주요 장점
- ✅ 트랜잭션 일관성 – 신뢰할 수 있는 동시 작업을 위한 ACID 준수
- ✅ 스키마 관리 – 기존 쿼리를 깨뜨리지 않는 유연한 스키마 진화
- ✅ 컴퓨트‑스토리지 분리 – 처리와 저장 리소스를 독립적으로 확장
- ✅ 오픈 표준 – Apache Iceberg 테이블 포맷과 호환
- ✅ 단일 진실 소스 – 데이터 사일로와 중복 저장 비용 제거
- ✅ 실시간 및 배치 처리 – 스트리밍과 히스토리 분석 지원
- ✅ 직접 파일 접근 – SQL 쿼리와 프로그래밍 방식 데이터 접근 모두 가능
- ✅ 통합 거버넌스 – 모든 데이터 유형에 걸친 일관된 보안 및 컴플라이언스
이러한 아키텍처 접근 방식은 SageMaker Unified Studio가 일반적인 복잡성 없이 구현하도록 도와줍니다.
SageMaker Unified Studio가 Lakehouse를 구현하는 방법
AWS 문서에 따르면:
“Amazon SageMaker의 lakehouse 아키텍처는 Amazon S3 데이터 레이크와 Amazon Redshift 데이터 웨어하우스의 데이터를 통합하여 한 곳에서 데이터를 작업할 수 있게 합니다.”
1. 단일 카탈로그를 통한 통합 데이터 접근
S3, Redshift, Aurora, DynamoDB 등 별도의 연결을 따로 관리할 필요 없이 하나의 통합 인터페이스를 제공합니다:
- AWS Glue Data Catalog – 모든 데이터를 검색하고 쿼리할 수 있는 단일 카탈로그.
- Apache Iceberg – 분석 엔진 간 상호 운용성을 제공하는 오픈 테이블 포맷.
- 다중 쿼리 엔진 (Athena, Redshift, EMR Spark) 모두 동일한 데이터를 중복 없이 접근 가능.
작동 방식:
“쿼리를 실행하면 AWS Lake Formation이 권한을 확인하고, 쿼리 엔진은 원본 저장 위치(Amazon S3 또는 Amazon Redshift)에서 직접 데이터를 처리합니다.”
결과: 데이터는 원래 위치에 그대로 유지됩니다—불필요한 이동이나 복제가 없습니다.
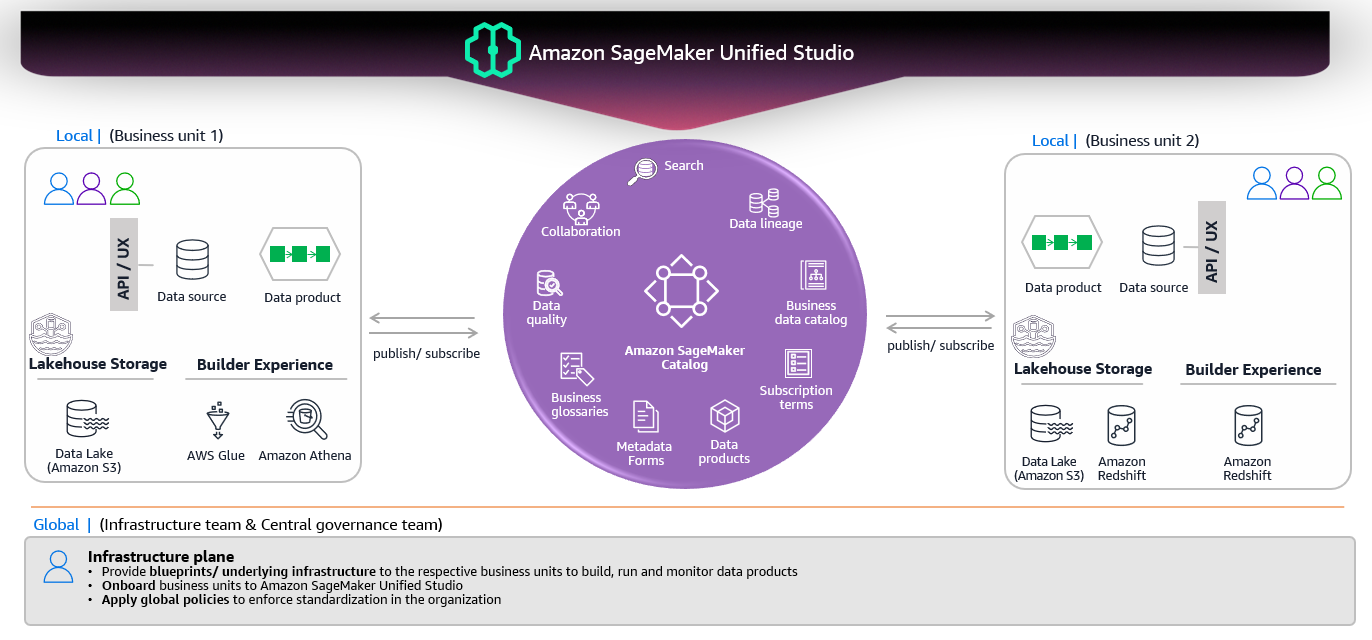
2. 두 가지 유형의 데이터 접근
| 유형 | 설명 |
|---|---|
| Managed Data Sources | • Amazon S3 데이터 레이크 – Apache Iceberg 지원이 내장된 S3 테이블 포함. • Amazon Redshift – Redshift 테이블에 직접 쿼리. |
| External Data Sources | • Amazon Aurora, DynamoDB, RDS 등 – 연합 쿼리 또는 커넥터를 통해 접근하며, 여전히 Lake Formation에 의해 관리됩니다. |
관리형 및 외부 소스 모두 단일 권한 모델(Lake Formation)로 관리되어 보안 및 규정 준수가 간소화됩니다.
3. Compute‑Storage 분리
- 스토리지 – S3(또는 Redshift)에 그대로 유지되며 복제되지 않습니다.
- 컴퓨트 – Athena, EMR Spark, Redshift Serverless, SageMaker Processing 작업 등을 필요에 따라 즉시 실행하여 스토리지와 독립적으로 확장할 수 있습니다.
4. 통합 거버넌스
- Lake Formation은 데이터가 어디에 있든 관계없이 세밀한 접근 제어를 적용합니다.
- DataZone은 비즈니스 수준 카탈로그와 프로젝트 수준 권한을 제공하여 올바른 팀이 올바른 데이터를 볼 수 있게 합니다.
5. 엔드‑투‑엔드 워크플로우 (단순화)
- Ingest – 원시 데이터를 S3에 저장하거나 Delta/Iceberg 테이블로 스트리밍합니다.
- Register – Glue Data Catalog에 테이블을 등록합니다(자동으로 Iceberg 메타데이터를 인식).
- Set – 사용자, 그룹, 역할에 대한 Lake Formation 권한을 설정합니다.
- Query – Athena, Redshift, Spark 등을 통해 쿼리합니다—데이터 이동을 위한 ETL이 필요 없습니다.
- Consume – 결과를 SageMaker 노트북, SageMaker Studio 또는 하위 ML 파이프라인에서 활용합니다.
Takeaway
- SageMaker Unified Studio는 전통적으로 별도의 데이터 레이크와 웨어하우스를 유지하도록 강요하던 사일로를 제거합니다.
- Lake Formation, Glue Data Catalog, 그리고 Apache Iceberg를 활용함으로써 SUS는 진정한 lakehouse—단일 진실 소스, ACID‑준수, 그리고 일관된 거버넌스를 제공합니다.
- 그 결과 비용 절감, 운영 간소화, 인사이트 도출 시간 단축, 그리고 분석 워크로드 전반에 걸친 일관된 보안을 얻을 수 있습니다.
Additional Capabilities
- Redshift warehouse tables – Redshift Spectrum을 통해 Iceberg 테이블로 접근 가능
- Zero‑ETL destinations – 다음 소스로부터 거의 실시간 데이터 복제 제공:
- SaaS 소스 (Salesforce, SAP, Zendesk)
- 운영 데이터베이스 (Amazon Aurora, Amazon RDS for MySQL)
- NoSQL 데이터베이스 (Amazon DynamoDB)
Federated Data Sources (Query in‑place without moving data)
- 운영 데이터베이스 (PostgreSQL, MySQL, Microsoft SQL Server)
- AWS‑관리형 데이터베이스 (Amazon Aurora, Amazon RDS, Amazon DynamoDB, Amazon DocumentDB)
- 타사 데이터 웨어하우스 (Snowflake, Google BigQuery)
SUS에서 연합 소스를 연결하면 AWS가 자동으로 필요한 인프라 구성 요소(AWS Glue 연결, Lambda 함수)를 프로비저닝하여 쿼리 엔진과 연합 데이터 소스 간의 브리지 역할을 수행합니다.
Centralized Governance with Lake Formation
하나의 권한 모델(AWS Lake Formation)로 다음 전반에 걸쳐 접근 제어를 일관되게 적용합니다:
- S3 데이터 레이크
- Redshift 데이터 웨어하우스
- 연합 소스
- 모든 쿼리 엔진(Athena, Redshift Query Editor v2, EMR, Glue)
Fine‑grained control을 테이블, 컬럼, 행, 셀 수준에서 제공—한 번 정의하면 모든 곳에서 적용됩니다.
Project‑Based Organization with DataZone
Amazon DataZone은 SUS의 프로젝트 및 도메인 관리를 지원합니다:
- Business catalog – 데이터 탐색 및 데이터‑제품 게시
- Project boundaries – 협업 및 권한 관리
- Cross‑domain data sharing – 팀 간 거버넌스된 데이터 접근 공유
- Domain management – 다수 프로젝트 조직화
Architecture Components
| Component | Description |
|---|---|
| Lakehouse Architecture | 아키텍처 패턴/접근 방식(제품이 아님) |
| SageMaker Unified Studio | Lakehouse 아키텍처를 구현하는 통합 플랫폼 |
| Athena, Redshift, Spark (EMR) | 쿼리/컴퓨팅 엔진으로, 여러분의 쿼리를 처리합니다 |
| Glue Data Catalog | 통합 메타데이터 카탈로그(메타데이터에 대한 단일 진실 원본) |
| Lake Formation | 세분화된 권한을 제공하는 거버넌스 레이어 |
| DataZone | 비즈니스 카탈로그 및 프로젝트 관리 레이어 |
| Apache Iceberg | 엔진 간 상호 운용성을 가능하게 하는 오픈 테이블 포맷 |
이제 SUS가 Lakehouse 아키텍처를 어떻게 구현하는지 이해했으니, 워크플로우를 어떻게 조직하는지 살펴보겠습니다.
The Three Core Sections of SUS
With lakehouse architecture providing unified data access, SUS organizes your workflow into three intuitive sections:
A. Discover
Your starting point for data exploration:
- Data Catalog (powered by AWS Glue Data Catalog) – discover all available data across lakes, warehouses, and federated sources
- Business Catalog (powered by DataZone) – find published data products and datasets shared across domains
- Bedrock Playground – experiment with generative AI models and prompts
This is where you explore what data is available across all your sources—all unified through the single catalog.
B. Build
This is where the action happens. SUS provides access to multiple analytical and ML tools:
Query Editors
- Amazon Athena Query Editor – serverless SQL queries across S3 and federated sources
- Amazon Redshift Query Editor v2 – high‑performance queries on warehouse data
Notebooks & Development
- JupyterLab Notebooks – data science, ML development, and programmatic data access
- SageMaker Training – building and training ML models
- SageMaker Inference – deploying models
Data Processing
- AWS Glue Visual ETL – no‑code/low‑code data transformations
- Amazon EMR – big‑data processing with Apache Spark
Orchestration
- Amazon MWAA (Airflow) – workflow orchestration and scheduling
AI Assistance
- Amazon Q Developer – AI‑assisted SQL and Python code generation
All these tools access your unified data seamlessly through different query engines, without requiring data movement.
C. Govern
Making your curated and valuable data consumable for other consumers:
- Publish data products to the business catalog
- Share datasets across projects and domains
- Enforce permissions consistently through Lake Formation
- Track data lineage and usage
- Manage data quality and compliance
Lake Formation ensures consistent permissions across all access patterns and query engines, while DataZone manages the business metadata and sharing workflows.
아키텍처 이해

다양한 녹색 상자는 SageMaker Unified Studio의 개념과 이들이 어떻게 연결되는지를 나타냅니다:
| 출발 | 도착 | 관계 | 카디널리티 | 의미 |
|---|---|---|---|---|
| 도메인 | 도메인 단위 | 포함 | 1 : M | 조직 구조 |
| 도메인 | 프로젝트 | 구성 | 1 : M | 프로젝트는 도메인에 속함 |
| 프로젝트 | 사용자 | 구성원 포함 | M : M | 사용자는 프로젝트에서 작업함 |
| 프로젝트 | 데이터 | 포함 | 1 : M | 프로젝트는 데이터 소스에 접근 |
| 사용자 | 자산 | 데이터를 통해 관리 | M : M | 사용자는 자산을 생성·관리 |
| 데이터 | 자산 | 게시됨 | M : M | 데이터가 자산으로 정리됨 |
녹색 상자들은 DataZone 기반 조직 프레임워크를 나타내며, 다음을 제공합니다:
- ✅ 구조 – 도메인, 도메인 단위
- ✅ 협업 – 프로젝트, 사용자
- ✅ 데이터 관리 – 데이터, 자산
- ✅ 거버넌스 – 권한이 모든 여섯 요소를 통해 흐름
이것은 SageMaker Unified Studio에서 레이크하우스 아키텍처 구현을 가능하게 하는 기반입니다!
요약
SUS는 통합 카탈로그를 중심으로 레이크, 웨어하우스 및 연합 소스에서 데이터를 액세스하는 다중 쿼리 엔진과 함께 레이크하우스 아키텍처를 구현하는 플랫폼 레이어를 제공합니다—모두 Lake Formation을 통해 일관되게 관리되고 DataZone을 통해 조직됩니다.
🚀 직접 해보기
실습 경험을 원하시나요? AWS에서는 이 게시물에서 다룬 모든 내용을 포함한 실용적인 워크숍을 제공합니다:
👉 SageMaker Unified Studio 워크숍
이 워크숍은 다양한 데이터 전문가들이 실제 비즈니스 과제를 해결하는 관점에서 실제 시나리오를 시뮬레이션합니다. 초기 데이터 분석부터 GenAI 기반 맞춤형 학생 참여 솔루션 배포까지 전체 과정을 단계별로 진행하게 됩니다.
워크숍을 읽고 스크린샷을 따라가며 SUS와 워크숍 구현을 이해하세요.
## 💬 Feedback Welcome
**What did you think?**
- ✅ Helpful sections?
- 🤔 Confusing parts?
- 💡 Topics for the next post?
**Have you tried SageMaker Unified Studio?** Share your experience in the comments!