RLAAS (Rate Limiting As A Service): 현대 시스템 전반의 Rate Limiting
I’m happy to translate the article for you, but I don’t have access to the content at the link you provided. Could you please paste the text you’d like translated (excluding any code blocks or URLs you want to keep unchanged)? Once I have the material, I’ll translate it into Korean while preserving the original formatting and markdown.
아무도 말하지 않는 문제
모든 엔지니어링 팀은 레이트 리밋이 필요하다는 것을 알고 있지만, 대부분의 솔루션은 한 층—API 게이트웨이만 보호합니다.
다른 모든 것은 어떻게 되나요?
| 문제점 | 설명 |
|---|---|
| 로그 홍수 | 버그가 수백만 개의 오류 로그를 관측 스택에 전송합니다. 비용이 급증하고, 대시보드가 깨지며, 온콜 엔지니어는 소음에 빠집니다. |
| 메트릭 폭풍 | 배포 중에 대화가 많은 서비스가 정상적인 Datadog 메트릭의 50배를 방출합니다. 청구서가 하룻밤 사이에 세 배가 됩니다. |
| 카프카 연쇄 | 느린 컨슈머가 뒤처집니다. 재시도가 쌓이고, 하나의 서비스가 전체 이벤트 파이프라인을 다운시킬 수 있습니다. |
| 사이드카 사각지대 | 메시 내부 서비스 간 트래픽이 게이트웨이에 도달하지 않으므로, 그곳에서 제한을 적용하는 것이 없습니다. |
| 복사‑붙여넣기 레이트 리밋 | 각 팀이 자체 서비스에 스로틀링 로직을 다시 구현하고, 각각의 버그와 엣지 케이스를 가지고, 공유 정책이 없습니다. |
근본 원인은 모든 경우에 동일합니다: 레이트 리밋이 플랫폼 기능이 아니라 게이트웨이 기능으로 취급됩니다.
이것이 제가 해결하고자 하는 부분입니다.
Introducing RLAAS
RLAAS는 Go로 작성된 오픈‑소스, 정책‑기반 플랫폼입니다. 하나의 통합 엔진을 사용해 HTTP, gRPC, 텔레메트리, 이벤트, 사이드카 등 여러 도메인에 걸쳐 일관된 속도 제한 결정을 적용합니다.
분산된 서비스별 스로틀링 코드를 작성하는 대신, 정책을 한 번 정의하고 모든 곳에서 적용합니다.
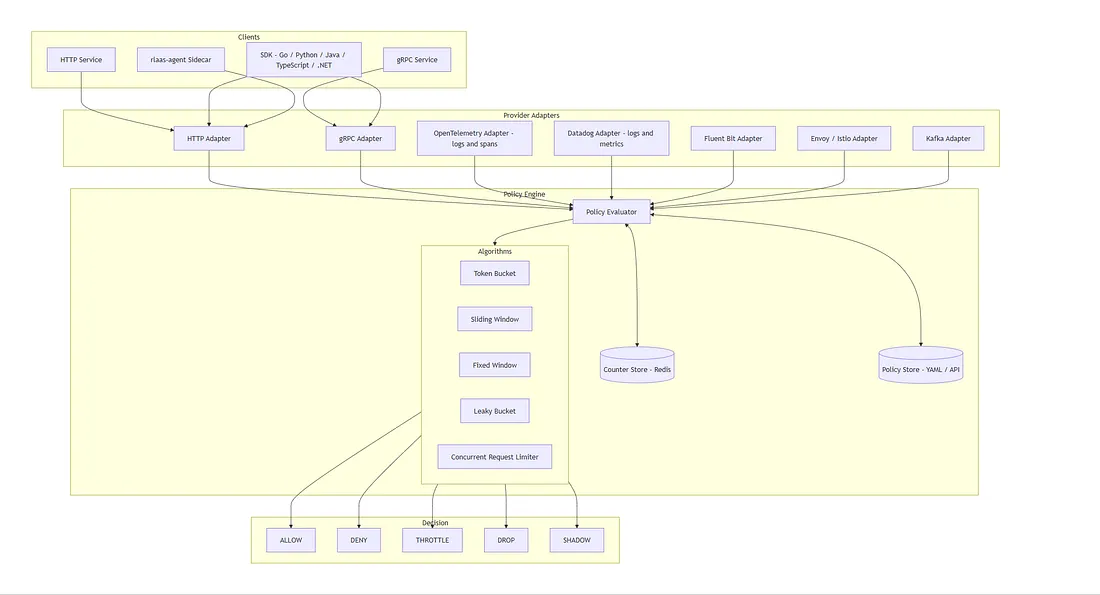
핵심 아이디어: 하나의 정책 엔진, 다중 제공자, 다중 배포 모델.
오늘 지원하는 알고리즘
RLAAS는 하나의 알고리즘에 국한되지 않습니다. 각 정책은 트래픽 패턴에 맞는 알고리즘을 독립적으로 선택합니다:
- Token Bucket – 버킷이 고정된 비율로 토큰을 재충전합니다. 요청이 토큰을 소모하고, 토큰이 없으면 요청이 제한됩니다. 하드 블로킹 없이 버스트 트래픽을 부드럽게 만들고 싶을 때 적합합니다. 예시: 짧은 버스트를 허용하면서 분당 최대 100개의 API 호출을 허용합니다.
- Sliding Window – 연속적으로 구르는 시간 창 전체에 걸쳐 요청을 추적합니다. 고정 창 경계에 걸쳐 두 배의 제한을 초과하는 “경계 스파이크” 문제를 제거합니다. 사용자별·테넌트별 할당량을 정확히 강제하고자 할 때 최적입니다.
- Fixed Window – 하드 타임 슬롯(예: 0–60 초) 내에서 요청을 카운트합니다. 간단하고 비용이 저렴하며 예측 가능합니다. 정밀도보다 거친 제한이 더 중요한 경우에 적합합니다.
- Leaky Bucket – 입력이 얼마나 버스트하든 관계없이 일정하고 엄격한 출력 비율을 강제합니다. 전체 볼륨이 제한 내에 있더라도 스파이크를 처리할 수 없는 다운스트림 서비스를 보호하는 데 유용합니다.
- Concurrent Request Limiter – 언제든지 진행 중인 요청 수를 제한합니다. 병렬 호출자에 의해 느린 업스트림 종속성이 과부하되는 것을 방지하는 데 필수적입니다.
단일 RLAAS 배포는 서로 다른 정책 및 리소스에 대해 모든 알고리즘을 동시에 실행할 수 있습니다.
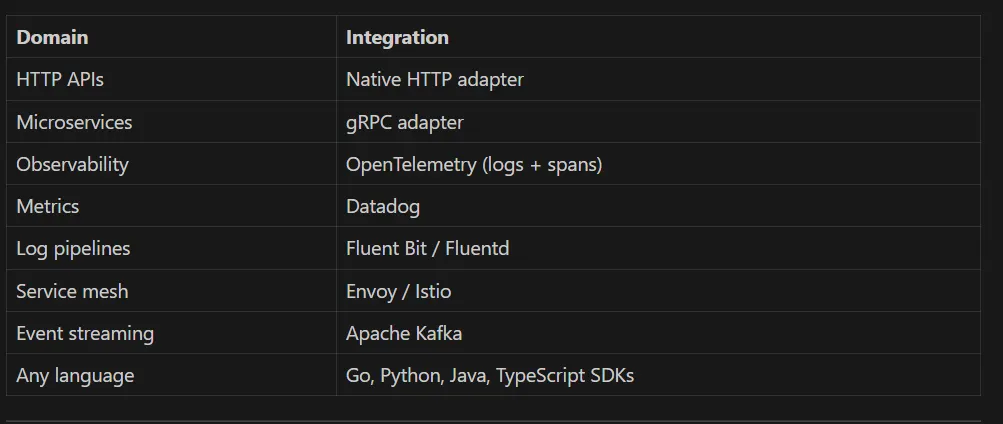
RLAAS가 통합되는 대상
정책 엔진 하나, 다양한 통합 포인트:
결정 — 허용 또는 거부 그 이상
대부분의 레이트 리미터는 두 가지 답변을 반환합니다: pass 또는 reject. RLAAS는 다섯 가지를 반환합니다:
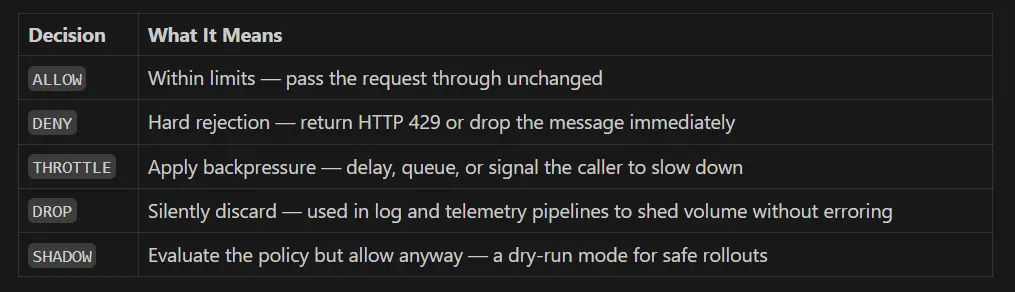
Shadow mode는 롤아웃 중에 특히 강력합니다. 적용을 활성화하기 전에 실제로 제한되었을 상황을 정확히 관찰할 수 있어—놀라움도, 사고도 없습니다.
각 정책은 자체 행동을 선언하므로, 하나의 정책은 남용하는 호출자를 DENY 할 수 있고, 다른 정책은 잡음이 많은 텔레메트리를 DROP 할 수 있으며, 세 번째 정책은 팀이 임계값을 검증하는 동안 SHADOW 모드로 실행됩니다.
배포 방법 세 가지
- Embedded SDK – 라이브러리를 서비스에 직접 임포트합니다. 네트워크 홉이 없으며 완전한 제어가 가능합니다. Go, Python, Java, 그리고 TypeScript에서 동작합니다.
- Centralized Service –
rlaas-server를 공유 마이크로서비스로 배포합니다. 모든 서비스가 gRPC 또는 HTTP를 통해 호출해 허용/거부 결정을 받습니다. 정책을 한 곳에서 관리할 수 있습니다. - Sidecar / Agent –
rlaas-agent를 워크로드 옆에 사이드카로 실행합니다. 코드 변경이 필요 없습니다. 인프라 수준에서 트래픽을 가로채며, Kubernetes, 서비스 메쉬, 베어‑메탈 환경 모두에서 동작합니다.
정책 작동 방식
정책은 선언적이며 버전‑관리됩니다. 정책이 적용되는 대상, 사용할 알고리즘, 제한, 시간 창, 그리고 제한에 도달했을 때 수행할 작업을 정의합니다.
{
"id": "nw-payments-logs",
"org_id": "northwind",
"resource": "payments.logs",
"algorithm": "sliding_window",
"limit": 5000,
"window_seconds": 60,
"action": "drop"
}코드 변경 없음. 재배포 없음. 정책 업데이트는 즉시 적용됩니다.
왜 오픈소스인가?
Rate‑limiting 로직은 여러분의 경쟁 우위가 아닙니다. 이는 인프라스트럭처 — 투명하고, 감사 가능하며, 커뮤니티‑주도적인 공유·재사용 가능한 기능이어야 합니다. RLAAS를 오픈‑소싱하면 팀들이 견고하고 실전 검증된 솔루션에 협업할 수 있으며, 각 서비스는 핵심 비즈니스 로직에 집중할 수 있습니다.
RLAAS – Reinforcement Learning as a Service
로드 밸런서나 메시지 큐가 인프라인 것처럼, RLAAS도 각 마이크로서비스 안에서 수작업으로 구현하기보다 공유 가능하고, 조합 가능하며, 정책 기반이어야 합니다.
RLAAS는 MIT‑licensed. 모든 알고리즘, 모든 어댑터, 그리고 모든 SDK는 오픈 소스이며 확장 가능하도록 설계되었습니다.
Try It
Docs:
GitHub:
이것이 여러분이 겪고 있는 문제를 해결한다면, 자유롭게 다음을 해보세요:
- Open an issue
- Contribute an adapter
- Share it with your team