파트 8: Databricks Pipeline & Dashboard
발행: (2026년 1월 2일 오후 08:00 GMT+9)
3 분 소요
원문: Dev.to
Source: Dev.to
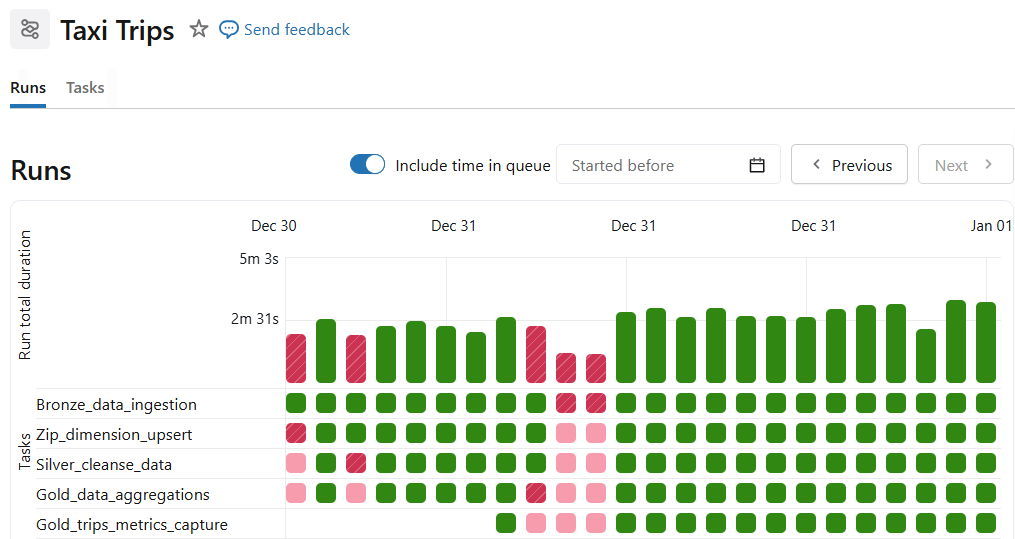
파이프라인 생성
Databricks 워크플로우는 이 블로그 시리즈에서 논의된 각 파트를 처리하는 작업으로 구성됩니다. 전체 파이프라인은 데이터를 점진적으로 스트리밍하고 처리하도록 오케스트레이션됩니다.
- Bronze 수집
- ZIP 차원 구축
- Silver 정제
- Gold 집계 (두 테이블 모두)
종속성은 순서를 자동으로 강제합니다. 또한 간단한 cron 표현식으로 파이프라인을 스케줄링할 수 있습니다.

대시보드 생성
Gold 테이블에 대한 쿼리는 Databricks 대시보드에 데이터를 공급합니다. Databricks 워크플로우에서 자체 대시보드를 만들고 사용자 정의 쿼리를 추가하여 비즈니스 인사이트를 시각적으로 표현하세요.
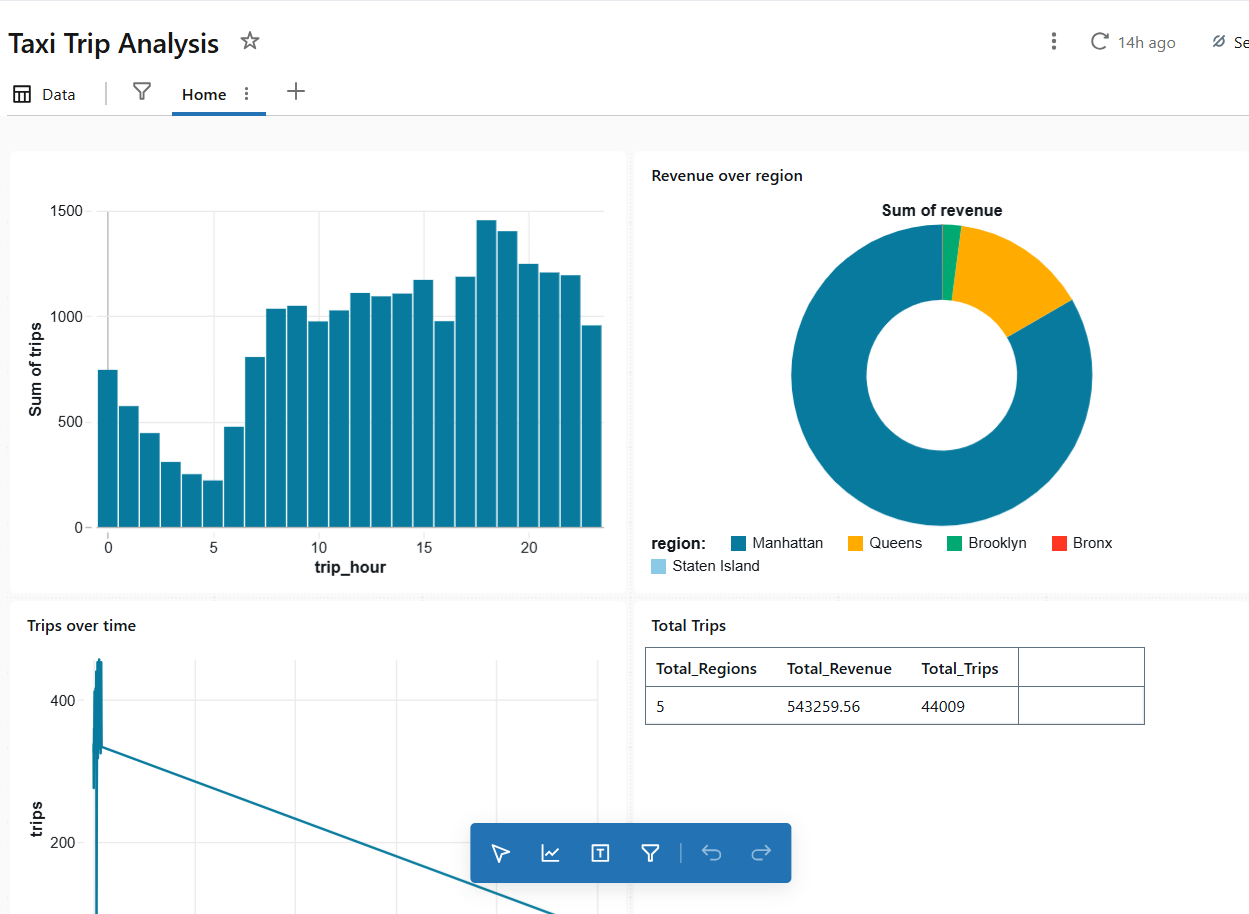
예시 쿼리
피크 시간을 얻으려면 다음 쿼리를 데이터 소스(SQL)로 추가하고 대시보드에 타일을 생성합니다:
SELECT
trip_hour,
SUM(total_trips) AS trips
FROM nyc_taxi.gold.taxi_trip_metrics
GROUP BY trip_hour;결과는 다음과 같이 표시됩니다:
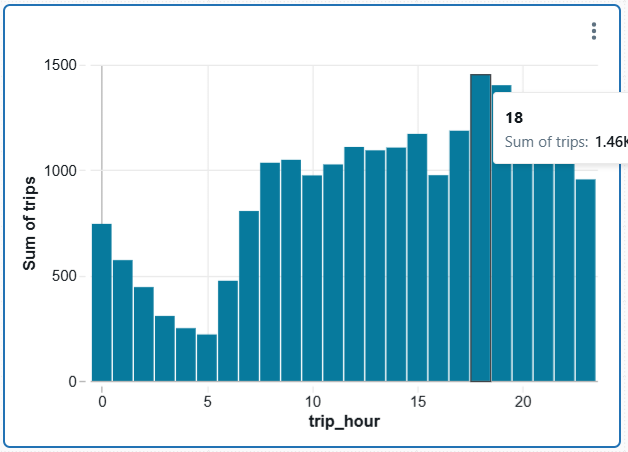
대시보드에 타일을 계속 추가하여 풍부하게 만들 수 있습니다. 대시보드는 다음 상황에서 자동으로 업데이트됩니다:
- 새로운 파일이 도착할 때
- 작업이 다시 실행될 때
- 워터마크 내에서 늦게 들어온 데이터가 처리될 때
새로운 데이터 도착을 시뮬레이션하려면 DBFS 입력 파일 소스에 추가 데이터를 넣으세요.

tpep_pickup_datetime을 실험해 보면 워터마크가 늦은 데이터를 처리하는 모습을 확인할 수 있습니다.
재처리 전략
상태를 초기화하고 모든 데이터를 다시 처리해야 할 경우:
- 테이블 또는 스키마를 삭제합니다.
- 체크포인트를 삭제합니다.
- 워크플로우를 다시 실행합니다.
소스 코드는 참고용으로 GitHub 저장소에서 확인할 수 있습니다.