파트 3: Databricks Sample Datasets를 사용한 실시간 스트리밍 데이터 시뮬레이션
발행: (2026년 1월 2일 오후 07:48 GMT+9)
2 분 소요
원문: Dev.to
Source: Dev.to
데이터셋 개요
우리는 기본적으로 Databricks에 제공되는 Databricks NYC Taxi 샘플 데이터셋을 사용합니다.
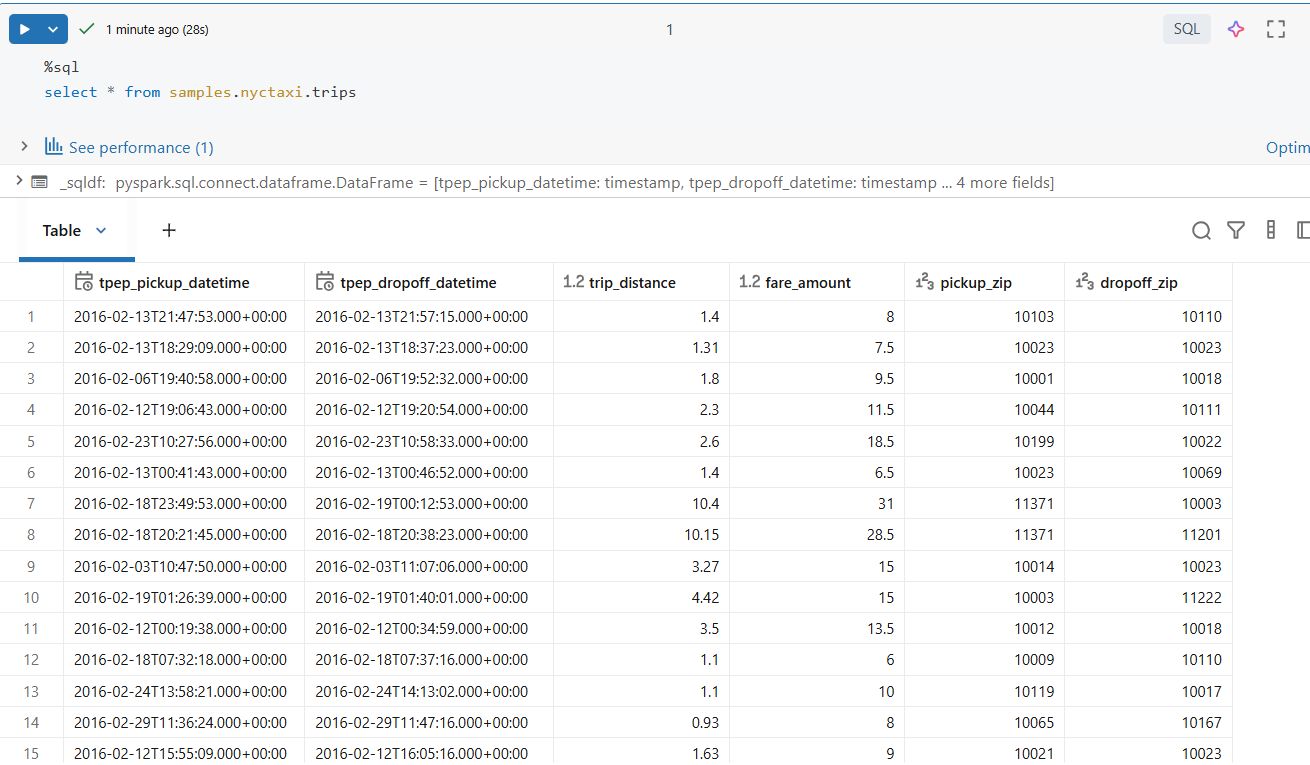
이 데이터셋이 이상적인 이유는 다음과 같습니다:
- 이벤트 타임스탬프 (
tpep_pickup_datetime) - 수치형 측정값 (
fare_amount,trip_distance) - 위치 속성 (
pickup_zip,dropoff_zip) - 성능 및 셔플 동작을 관찰할 수 있을 만큼 충분한 데이터 양
데이터셋은 정적이지만, 이를 스트리밍 소스로 변환할 것입니다.
정적 데이터를 스트리밍 소스로 변환하기
단계 1: 샘플 데이터셋 읽기
df = spark.table("samples.nyctaxi.trips")이 시점에서 데이터는 일반 배치 DataFrame입니다.
단계 2: 데이터를 JSON 파일로 저장하기
스트리밍 입력을 시뮬레이션하기 위해 데이터셋을 JSON 파일로 디렉터리에 저장합니다:
(
df.write
.mode("overwrite")
.format("json")
.save("/tmp/taxi_stream_input")
)이 작업은 DBFS(Databricks File System)에 파일을 기록하며, /tmp/taxi_stream_input에 기존에 있던 파일들을 모두 덮어씁니다. 여러 개의 JSON 파일이 생성되며, 각각은 들어오는 이벤트 배치를 나타냅니다.
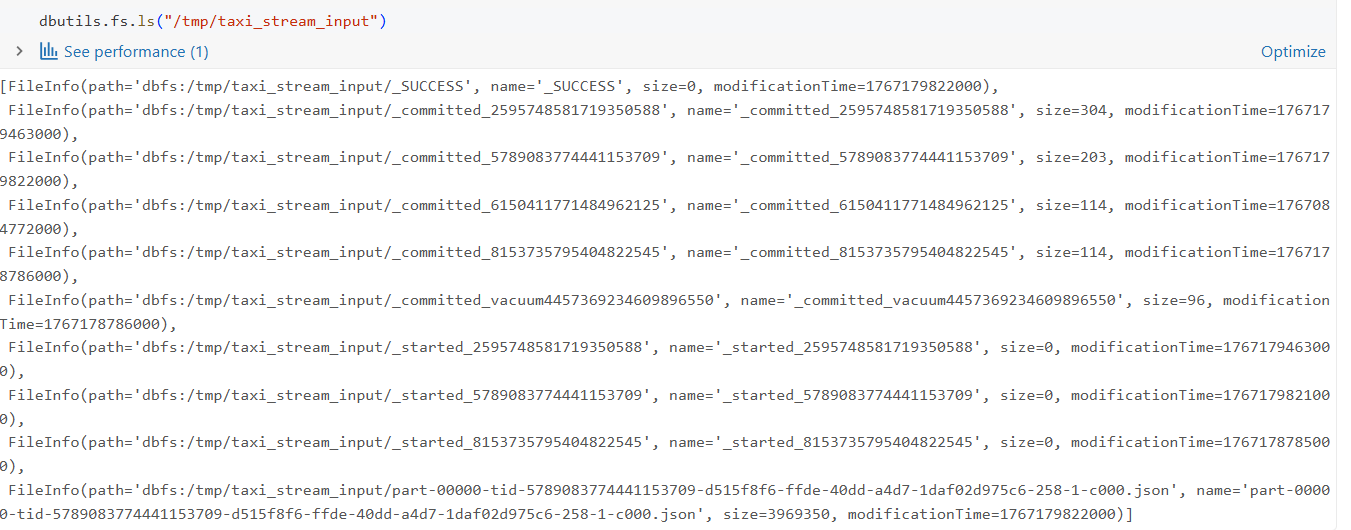
이제 데이터가 파일 스토리지에 존재하므로 이를 읽어 스트리밍을 시작할 수 있습니다.