노르웨이의 2페타바이트 화웨이 플래시 스토리지 및 LLM 훈련
Source: Hacker News
번역하려는 전체 텍스트를 제공해 주시면, 요청하신 대로 한국어로 번역해 드리겠습니다. (코드 블록, URL 및 마크다운 형식은 그대로 유지됩니다.)
노르웨이 국립 도서관 LLM 프로젝트
개요
노르웨이 국립 도서관은 노르웨이어를 이해하는 대형 언어 모델(LLM)을 개발하고 있으며, AI 학습 데이터 파이프라인에 2 PB의 화웨이 OceanStor Dorado 플래시 스토리지를 사용하고 있습니다.

마리우스 후스네스, 도서관 IT 플랫폼 책임자
마리우스 후스네스는 파리에서 열린 Huawei’s ID Forum 2026에서 이 프로젝트에 대해 논의하면서, 현재 상업적인 LLM 제공업체 중 어느 곳도 현지(노르웨이) 언어 모델을 개발하고 있지 않다고 지적했습니다. 그는 자국 언어에 대한 주권 LLM이 없는 국가는 불리한 위치에 놓이게 된다고 주장했습니다. 전 세계적으로 훈련된 영어 중심 모델은 현지 언어로 표현된 국가의 역사, 뉴스, 문화 등을 놓치게 됩니다.
노르웨이 문화부는 국립 도서관에 주권 AI 구축을 맡겼습니다. 도서관은 노르웨이 책, 신문, 웹 페이지 및 기타 문화 자료의 가장 큰 디지털 컬렉션을 보유하고 있기 때문입니다. 이 기관의 법정 보관 의무는 책을 넘어 노르웨이 전체 문화 유산까지 확장됩니다.
데이터 액세스 및 저장
노르웨이 신문과의 협약을 통해 저작권이 있는 콘텐츠에 대한 LLM 훈련이 허용됩니다. Husnes가 말했듯이, “민간 기업은 이걸 할 수 없습니다.”
도서관은 2005년부터 컬렉션을 디지털화해 왔으며 현재 20 PB의 고유 데이터를 3‑2‑1 구성(복제본 3개, 매체 유형 2가지, 오프사이트 1곳)으로 저장하고 있어 전체 약 60 PB에 달합니다. 디지털화 파이프라인(텍스트, 오디오, 비디오, 이미지, 웹 콘텐츠)은 방대한 OCR 데이터, 메타데이터 및 온라인 접근을 위한 API를 생성합니다.
이 데이터 대부분은 디지털 디스크‑플러스‑테이프 아카이브(보존 시스템)에 보관됩니다. Husnes의 과제는 이 데이터를 LLM 훈련 파이프라인으로 옮기는 것입니다. 그는 병목 현상이 컴퓨팅이 아니라 데이터 품질, 정제 및 파이프라인 처리량이라고 지적했습니다.
첫 번째 처리 단계
- 컴퓨팅: Nvidia DGX H200, 384코어 CPU 클러스터.
- 스토리지: Huawei OceanStor Dorado 올플래시 어레이(총 2 PB), 데이터 파이프라인 및 훈련 준비를 위한 저지연 스토리지를 제공.
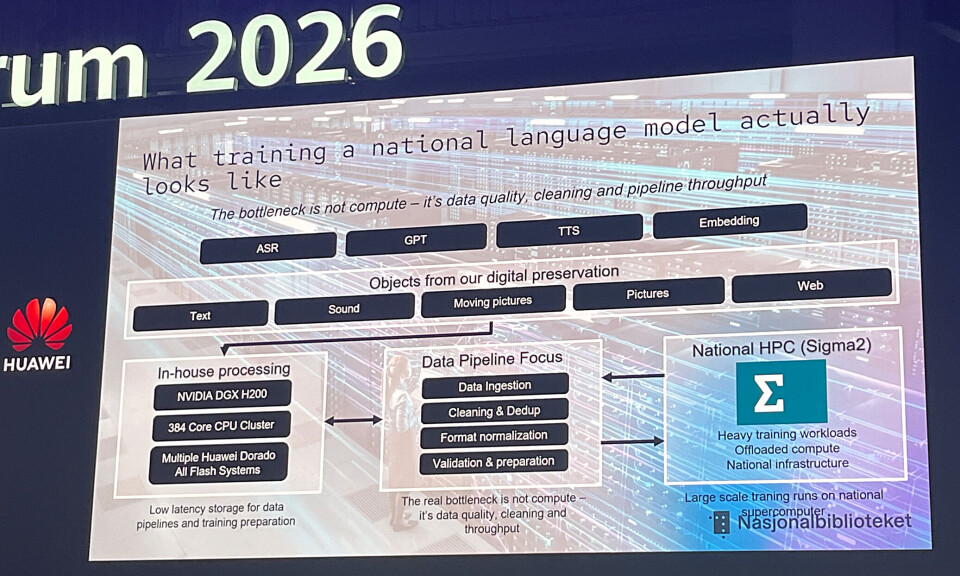
Husnes – 국가 LLM 훈련
파이프라인은 수집, 정제, 중복 제거, 형식 정규화, 검증 및 준비 작업을 수행합니다. 처리된 데이터는 실제 훈련이 이루어지는 노르웨이 국가 슈퍼컴퓨터인 Sigma2 Olivia 시스템으로 전송됩니다.
- Olivia: 448 GPU와 64 512 CPU 코어를 갖춘 HPE Cray EX 시스템.
- 스토리지: 5.3 PB Cray ClusterStor E1000.
스토리지 시스템 과제
60 PB 보존 시스템은 내구성과 비용 효율성을 위해 최적화돼 있어 빠른 I/O에 적합하지 않으며, 읽기 지연 시간이 높습니다. 반면 AI 파이프라인 스토리지는 고처리량·저지연 병렬 접근을 위해 설계되었습니다. Husnes는 “PB 규모 데이터셋을 아카이브에서 AI 데이터 파이프라인 시스템으로 이동하는 문제에 대해 아무도 이야기하지 않았다”고 언급했습니다. 그의 팀은 직접 해결책을 고안해야 했습니다.

Husnes – 보존 및 AI 파이프라인 스토리지
진행 중인 학습
LLM 훈련은 아직 진행 중이다. Husnes는 그의 팀이 아직 탐구하고 있는 세 가지 주요 영역을 요약했다:
- 평가 – 주권 노르웨이 LLM을 평가할 표준 도구가 존재하지 않는다. 언어는 두 가지 문자 형태, 여러 방언, 그리고 역사적 변형을 가지고 있어, 그들은 즉석에서 맞춤형 평가 스위트를 구축하고 있다.
- 거버넌스 – 주권 LLM에 대한 접근을 누가 통제하는가? 허용 가능한 사용을 누가 결정하는가? 이는 쉬운 답이 없는 제도적·정치적 질문이다.
- 오케스트레이션 – 보존 아카이브, 온‑프레미스 AI 환경, 그리고 국가 Sigma2 슈퍼컴퓨터라는 세 시스템을 통합하는 작업은 지속적인 엔지니어링 노력이다.
Takeaway
Huawei’s OceanStor Dorado flash storage는 유럽 국가가 자체 주권 언어 모델을 구축하도록 지원하는 데 있어 매우 중요한 역할을 하고 있으며, 대규모 AI 파이프라인에서 고성능·저지연 스토리지의 중요성을 보여줍니다.
시장 통찰
… 그리고 두 번째는, 주권적인 현지 언어 LLM을 개발하는 모든 국가는 Husnes와 상담하고 관련 사항을 숙지하는 것이 좋다는 점이다.
Husnes가 말했듯이: “노르웨이는 모든 비영어권 국가가 직면하게 될 문제를 해결하고 있는 작은 나라입니다—자신의 언어, 문화, 역사를 반영하는 AI를 어떻게 구축하나요? AI는 구축자뿐만 아니라 관리자가 필요합니다.”