Apple 지원 AI 모델, 무음 비디오에서 소리와 음성 생성
Source: 9to5Mac

VSSFlow – 통합 오디오 생성 모델
새로운 모델인 VSSFlow는 새로운 아키텍처를 사용하여 단일 통합 시스템 내에서 소리 및 음성을 모두 생성하며, 최첨단 결과를 제공합니다.
아래 데모를 시청(및 청취)하세요.
데모 링크는 여기 (플레이스홀더를 실제 비디오 URL로 교체하세요.)
The Problem
대부분의 비디오‑투‑사운드 모델(즉, 무음 비디오에서 오디오를 생성하는 모델)은 현실적인 음성을 만드는 데 어려움을 겪습니다. 반대로 대부분의 텍스트‑투‑스피치 시스템은 다른 목적에 맞게 설계되어 있어 비음성 사운드를 생성하지 못합니다.
이러한 작업을 통합하려는 이전 시도들은 공동 학습이 성능을 저하시킨다고 가정하는 경우가 많았습니다. 따라서 그들은 음성 및 사운드를 별도로 가르치는 다단계 파이프라인을 채택하여 불필요한 복잡성을 더했습니다.
What the researchers did
Apple의 세 명의 연구원과 중국 인민대학의 여섯 명의 협력자가 **VSSFlow**를 소개했습니다 — 무음 비디오에서 사운드 효과 및 음성을 모두 생성할 수 있는 단일 AI 모델입니다.
아키텍처의 핵심 포인트:
- 공동 학습: 음성 학습과 사운드 학습이 서로 방해하기보다 서로를 강화합니다.
- 통합 파이프라인: 별도의 단계를 없애 워크플로를 단순화합니다.
- 양방향 이점: 음성 생성의 향상이 사운드 효과 생성에도 도움이 되고, 그 반대도 마찬가지입니다.
솔루션
VSSFlow는 여러 생성‑AI 개념을 활용합니다:
- Phoneme‑level tokenisation – 전사(transcript)를 음소 토큰 시퀀스로 변환합니다.
- Flow‑matching – 모델이 잡음(noise)으로부터 소리를 복원하도록 학습합니다. 즉, 무작위 잡음에서 시작해 원하는 오디오 신호로 끝나도록 훈련됩니다. (자세한 설명은 여기를 참고하세요.)
이러한 아이디어를 10‑layer 아키텍처에 결합하여 비디오와 전사 정보를 직접 오디오‑생성 파이프라인에 융합합니다. 그 결과, 사운드 효과와 음성을 모두 생성할 수 있는 단일 시스템이 탄생합니다.
핵심 통찰: 음성 및 환경 소리를 동시에 학습함으로써 두 작업 모두에서 성능이 향상되었으며, 서로 경쟁하지 않았습니다.
학습 데이터
| 데이터셋 | 내용 |
|---|---|
| V2S | 환경 소리와 짝을 이룬 무음 비디오 |
| VisualTTS | 전사와 짝을 이룬 무음 말하기 비디오 |
| TTS | 일반 텍스트‑투‑스피치 데이터 |
모델은 이 혼합 데이터를 엔드‑투‑엔드로 학습하여 사운드 효과 와 spoken dialogue를 동시에 생성하도록 배웁니다.
동시 출력에 대한 파인‑튜닝
초기 VSSFlow는 배경음 와 spoken dialogue를 하나의 출력에 함께 만들 수 없었습니다. 이를 해결하기 위해 저자들은 합성 예시가 대량으로 포함된 컬렉션을 사용해 사전 학습된 모델을 파인‑튜닝했습니다. 이 데이터에서는 음성 및 환경 소리가 함께 섞여 있습니다(합성‑데이터 파이프라인은 여기를 참고). 이 파인‑튜닝을 통해 모델은 두 모달리티의 공동 음향 특성을 학습합니다.
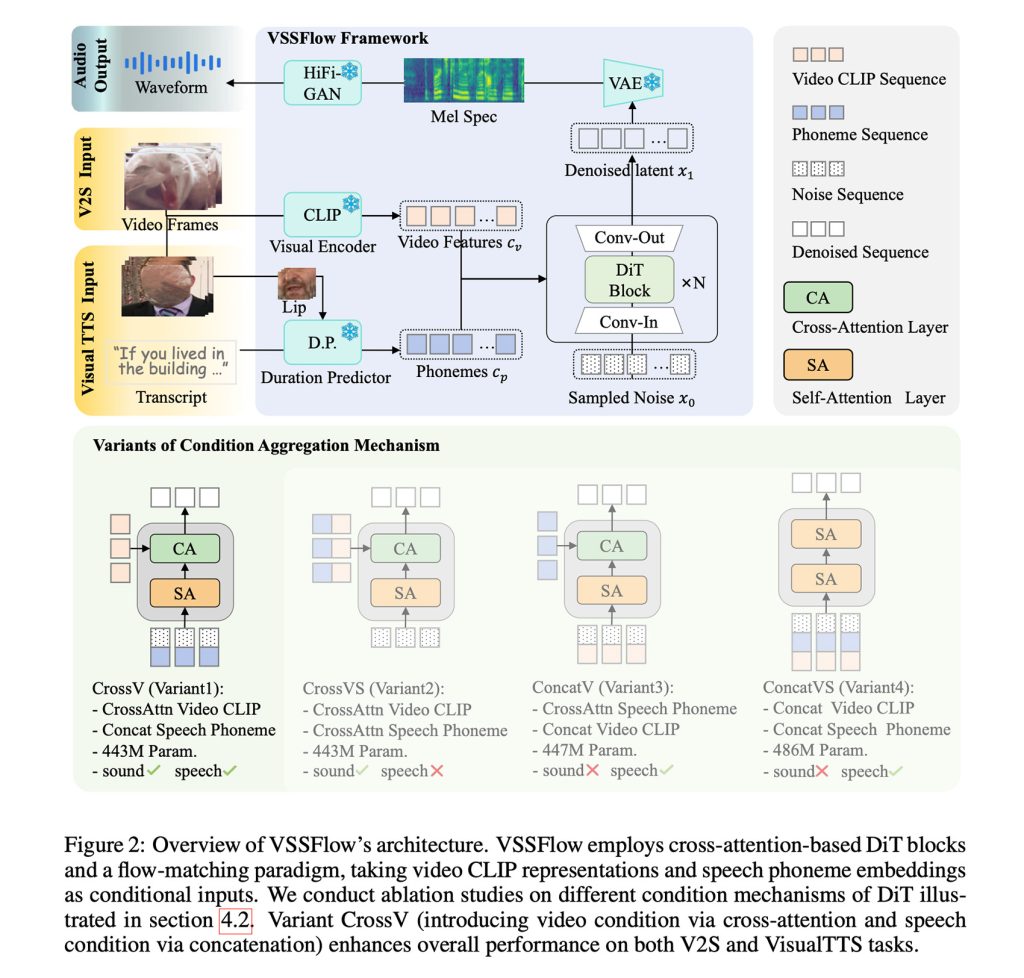
그림: VSSFlow 아키텍처
VSSFlow 활용하기
무음 비디오에서 소리와 음성을 생성하기 위해 VSSFlow는 무작위 노이즈에서 시작해 비디오에서 10 fps로 샘플링된 시각적 단서를 사용해 주변 소리를 형성합니다. 동시에, 말해지는 내용의 전사본이 생성된 음성에 대한 정확한 가이드를 제공합니다.
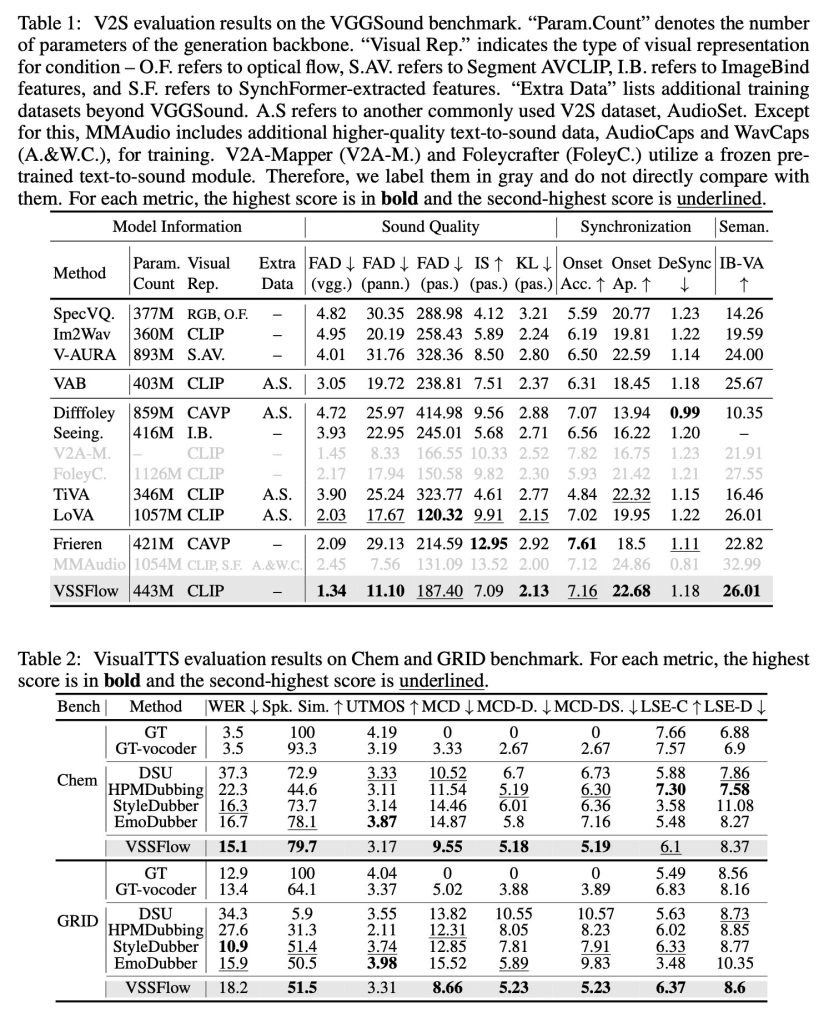
음향 효과 전용 모델이나 음성 전용 모델과 같은 작업‑특화 모델과 비교했을 때, VSSFlow는 단일 통합 시스템을 사용하면서도 두 작업 모두에서 경쟁력 있는 결과를 보여주었으며, 여러 핵심 지표에서 선두를 차지했습니다.
연구진은 사운드, 스피치, 그리고 공동 생성(Veo3 비디오 기반) 결과에 대한 여러 데모와 VSSFlow와 다양한 대체 모델 간의 비교를 공개했습니다. 아래에서 몇 가지 결과를 확인할 수 있지만, 모든 데모를 보려면 데모 페이지를 방문해 주세요.
Note: 연구진은 VSSFlow의 코드를 GitHub에 오픈소스(github.com/vasflow1/vssflow)로 공개했으며, 모델 가중치와 추론 데모를 출시하기 위해 작업 중입니다.
향후 방향 (저자 인용)
“이 작업은 비디오‑투‑사운드(V2S)와 시각 텍스트‑투‑스피치(VisualTTS) 작업을 통합한 통합 흐름 모델을 제시하며, 비디오‑조건부 사운드와 스피치 생성에 대한 새로운 패러다임을 구축합니다. 우리 프레임워크는 DiT 아키텍처에 스피치와 비디오 조건을 통합하기 위한 효과적인 조건‑집합 메커니즘을 보여줍니다. 또한, 분석을 통해 사운드‑스피치 공동 학습의 상호 강화 효과를 밝혀내어 통합 생성 모델의 가치를 강조합니다.
향후 연구를 위해 탐구할 가치가 있는 몇 가지 방향이 있습니다. 첫째, 고품질 비디오‑스피치‑사운드 데이터의 부족이 통합 생성 모델 개발을 제한합니다. 또한, 스피치 세부 정보를 보존하면서도 압축된 형태를 유지하는 사운드와 스피치에 대한 더 나은 표현 방법을 개발하는 것이 중요한 과제입니다.”
연구에 대해 더 자세히 알아보려면, **“VSSFlow: Unifying Video‑conditioned Sound and Speech Generation via Joint Learning”**이라는 제목의 논문을 여기서 확인하세요.
Source:
Amazon의 액세서리 할인
- AirPods Pro 3
- Apple AirTag 4‑Pack
- Beats USB‑C to USB‑C Woven Short Cable
- Wireless CarPlay Adapter
- Logitech MX Master 4
![]()
![]()
FTC: 우리는 수익을 창출하는 자동 제휴 링크를 사용합니다. 자세히 보기