Bedrock 지식 베이스를 위한 멀티테넌트 설계: 메타데이터 필터링으로 계정 제한 해결
Source: Dev.to
위에 제공된 소스 링크 외에 번역할 텍스트를 알려주시면 한국어로 번역해 드리겠습니다.
소개
최근에 일상 업무에서 Bedrock KnowledgeBase를 사용하면서, 그 사양과 관련된 몇 가지 어려움을 겪게 되었고 이를 공유하고자 합니다.
배경
현재 저는 Bedrock KnowledgeBase(KB)를 사용하여 멀티 테넌트 애플리케이션을 개발 중입니다. KB는 파일을 벡터 스토어에 벡터화하고 Bedrock Agent와 결합하면 상황에 맞는 대화를 생성할 수 있는 LLM RAG 구현을 위한 오케스트레이터입니다.
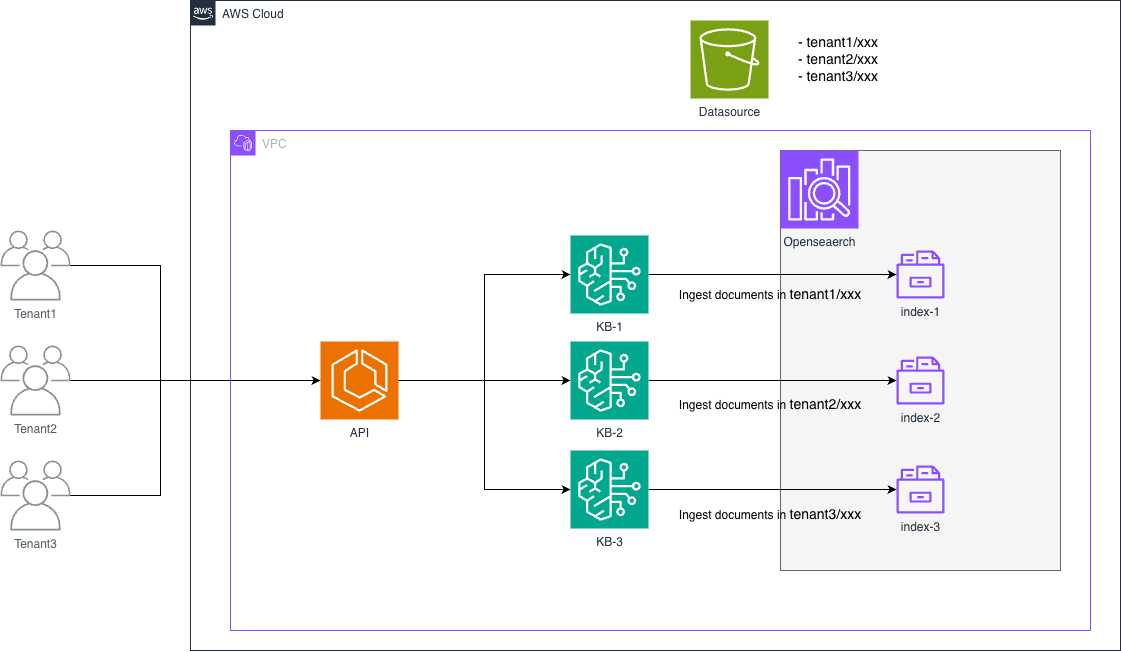
우리는 OpenSearch를 벡터 스토어로 사용하고 있으며, 설계상 각 테넌트마다 별도의 KB와 인덱스를 생성합니다. 이 접근 방식은 테넌트 간 데이터 격리를 보장하며, 당시에는 자연스러운 설계 선택처럼 보였습니다.
문제
Bedrock의 할당량을 확인하면서 계정당 지식 베이스 할당량이 하드 제한 100임을 발견했습니다. 초기 설계에서는 이로 인해 애플리케이션이 최대 100개의 테넌트만 지원할 수 있었으므로 아키텍처를 재고해야 했습니다.
솔루션
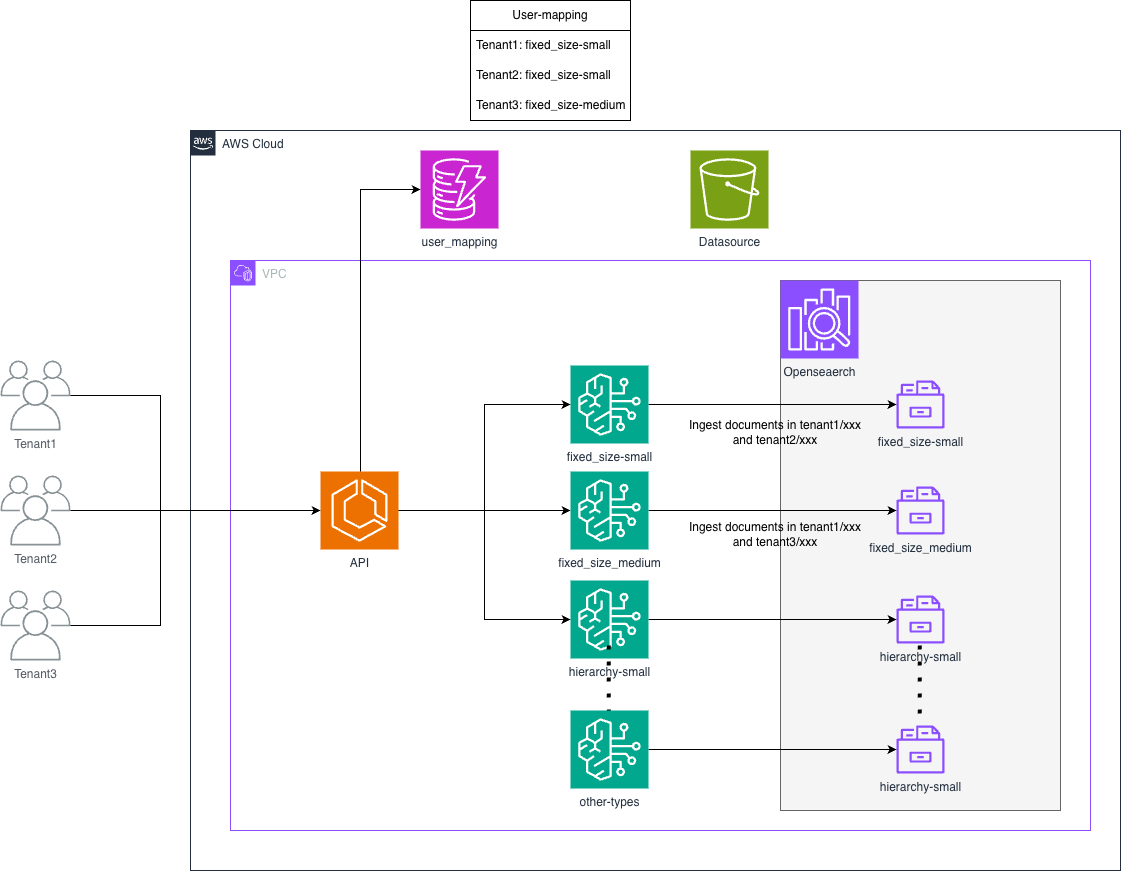
우리는 설계를 수정하여 KB와 인덱스를 여러 테넌트가 공유하도록 만들었습니다. KB에는 벡터화와 관련된 여러 매개변수(예: ChunkStrategy)가 있기 때문에, ChunkStrategy와 MaxToken의 여러 조합을 만들어 사용자가 공유 옵션 중에서 선택하도록 했습니다.
중요한 고려 사항은 다른 테넌트와의 대화 중에 테넌트 데이터가 참조되지 않도록 하는 것입니다. KB는 벡터화 시 사용자 정의 메타데이터를 첨부할 수 있으므로, tenant_id와 같은 메타데이터 필드를 첨부하고 검색 시 해당 ID로 문서를 필터링합니다.
아키텍처 개요
- 여러 테넌트가 공유하는 지식 베이스
- 각 문서에 첨부된 사용자 정의 메타데이터 (
tenant_id) - 검색 시 메타데이터 필터링을 통해 데이터 격리 보장
문서에 메타데이터 첨부하기
# ingest_documents
response = client.ingest_knowledge_base_documents(
knowledgeBaseId='string',
dataSourceId='string',
clientToken='string',
documents=[
{
'metadata': {
'type': "IN_LINE_ATTRIBUTE",
'inlineAttributes': [
{
'key': 'tenant_id',
'value': {
'type': "STRING",
'stringValue': "$tenant_id",
}
},
]
},
'content': {
# document content here
}
},
]
)에이전트 호출 시 메타데이터로 문서 필터링하기
# invoke_agent
response = boto3.client('bedrock-agent').invoke_agent(
knowledgeBaseConfigurations=[
{
"knowledgeBaseId": "$vector_store_id",
"description": "Knowledge base for document retrieval",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"equals": {
"key": "tenant_id",
"value": "$tenant_id"
}
}
}
},
}
]
)향후 계획
위 구현을 통해 이제 100‑KB 제한을 성공적으로 피하면서 애플리케이션을 구축할 수 있습니다.
멀티‑테넌트 애플리케이션에서는 한 테넌트가 다른 테넌트의 데이터에 접근할 수 없음을 확인하는 것이 중요합니다. 다음과 같은 모니터링 메커니즘을 만들 계획입니다:
- 여러 테스트 테넌트를 생성합니다.
- 각 테넌트마다 공유 벡터 스토어에 구별되는 문서를 삽입합니다.
- 다른 테넌트의 문서에 대한 질문으로 에이전트를 조회합니다.
- 답변이 반환되지 않음을 확인합니다.
이 스크립트를 스테이징 환경에서 정기적으로 실행하면 의도치 않은 데이터 유출을 감지하는 데 도움이 됩니다. 시스템 리소스(CPU, 메모리) 모니터링도 중요하지만, 데이터 격리 모니터링도 동일하게 중요합니다.
결론
이것은 KB 사양과 우리의 대응책에 관련된 문제들입니다. 이번 경험을 통해 시스템 설계를 결정하기 전에 클라우드 서비스 사양을 확인하는 것이 얼마나 중요한지 알게 되었습니다. 이 글이 여러분에게 도움이 되길 바랍니다.