SQL 조인 및 윈도우 함수 마스터하기
Source: Dev.to
SQL 조인
A JOIN은 두 개 이상의 테이블에서 관련 열을 기준으로 행을 결합합니다. 조인은 다음에 도움이 됩니다:
- 여러 테이블에 저장된 연결된 데이터를 검색합니다.
- 공통 열을 사용하여 레코드를 매칭합니다.
- 관련 정보를 결합하여 데이터 분석을 향상시킵니다.
- 별도 테이블에서 의미 있는 결과 집합을 생성합니다.
예시 테이블
Customers
| customer_id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
Orders
| order_id | customer_id | amount |
|---|---|---|
| 101 | 1 | 250 |
| 102 | 1 | 300 |
| 103 | 2 | 150 |
1. INNER JOIN
두 테이블 모두에 일치하는 값이 존재하는 행을 검색합니다. 관련 열을 기준으로 레코드를 결합합니다.
Syntax
SELECT
c.customer_id,
c.name,
o.order_id,
o.amount
FROM Customers AS c
INNER JOIN Orders AS o
ON c.customer_id = o.customer_id;Result

Note: 한정자를 사용하지 않은
JOIN은INNER JOIN과 동일합니다.
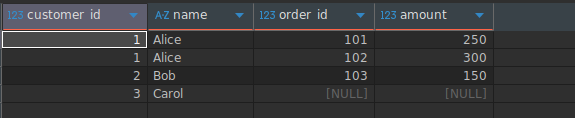
2. LEFT JOIN (LEFT OUTER JOIN)
왼쪽 테이블의 모든 행과 오른쪽 테이블에서 일치하는 행을 반환합니다. 일치하는 행이 없으면 오른쪽 열은 NULL을 포함합니다.
Syntax
SELECT
c.customer_id,
c.name,
o.order_id,
o.amount
FROM Customers AS c
LEFT JOIN Orders AS o
ON c.customer_id = o.customer_id;Result
3. RIGHT JOIN (RIGHT OUTER JOIN)
오른쪽 테이블의 모든 행과 왼쪽 테이블에서 일치하는 행을 검색합니다. 동일한 결과를 테이블 순서를 바꾸어 LEFT JOIN으로도 얻을 수 있기 때문에 덜 일반적입니다.
4. FULL OUTER JOIN
양쪽 테이블의 모든 행을 반환합니다. 반대쪽에 일치하는 행이 없을 경우, 누락된 열은 NULL로 채워집니다.
Syntax
SELECT
c.customer_id,
c.name,
o.order_id,
o.amount
FROM Customers AS c
FULL JOIN Orders AS o
ON c.customer_id = o.customer_id;조인을 사용할 때
- 관련 데이터 세트를 결합해야 할 때.
- 데이터베이스가 정규화되어 있을 때.
- 데이터의 풍부하거나 관계형 뷰를 원할 때.
Source: …
윈도우 함수
SQL 윈도우 함수는 현재 행과 관련된 행 집합에 대해 계산을 수행하지만 결과를 단일 집계 행으로 축소하지 않습니다. 주로 집계, 순위 지정 및 누적 합계에 사용됩니다.
기본 구문
FUNCTION_NAME() OVER (
PARTITION BY ...
ORDER BY ...
)OVER 절은 계산을 위한 “윈도우” 행 범위를 정의합니다:
- PARTITION BY – 데이터를 그룹(파티션)으로 나눕니다.
- ORDER BY – 각 파티션 내에서 행의 순서를 지정합니다.
예시 데이터셋
| sale_id | 지역 | 금액 |
|---|---|---|
| 1 | East | 200 |
| 2 | East | 200 |
| 3 | East | 100 |
| 4 | West | 300 |
| 5 | West | 150 |
윈도우 함수 유형
1. 집계 윈도우 함수
이들은 개별 행을 유지하면서 윈도우 내에서 집계를 계산합니다. 일반적인 함수:
SUM()– 값들의 합계.AVG()– 값들의 평균.COUNT()– 행 개수.MAX()– 최대값.MIN()– 최소값.
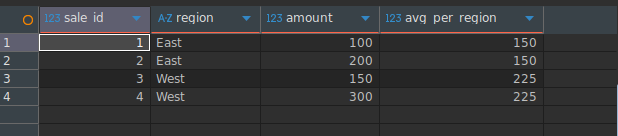
예시 – 지역별 평균
SELECT
sale_id,
region,
amount,
AVG(amount) OVER (PARTITION BY region) AS avg_region_sales
FROM Sales;결과
2. 순위 윈도우 함수
이들은 지정된 순서에 따라 파티션 내 각 행에 순위를 부여합니다.
RANK()
순위를 부여합니다; 동점인 경우 같은 순위를 받고 다음 순위는 건너뛰어집니다.
SELECT
sale_id,
region,
amount,
RANK() OVER (
PARTITION BY region
ORDER BY amount DESC
) AS sales_rank
FROM Sales;DENSE_RANK()
RANK()와 유사하지만 동점 이후 순위를 건너뛰지 않습니다.
SELECT
sale_id,
region,
amount,
DENSE_RANK() OVER (
PARTITION BY region
ORDER BY amount DESC
) AS sales_dense_rank
FROM Sales;ROW_NUMBER()
동점 여부와 관계없이 파티션 내 각 행에 고유한 순차 번호를 제공합니다.
SELECT
sale_id,
region,
amount,
ROW_NUMBER() OVER (
PARTITION BY region
ORDER BY amount DESC
) AS row_num
FROM Sales;3. 분석 (비집계) 윈도우 함수
이들은 다른 행을 참조하는 계산을 수행하지만 집계는 하지 않습니다.
LEAD()/LAG()– 다음/이전 행의 값을 가져옵니다.FIRST_VALUE()/LAST_VALUE()– 윈도우 내 첫 번째/마지막 값을 반환합니다.NTILE()– 행을 지정된 개수의 버킷으로 나눕니다.
예시 – 누적 합계
SELECT
sale_id,
region,
amount,
SUM(amount) OVER (
PARTITION BY region
ORDER BY sale_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS running_total
FROM Sales;요약
- 조인은 관계에 따라 여러 테이블의 행을 병합합니다. 유지하고자 하는 행에 따라 적절한 조인 유형(
INNER,LEFT,RIGHT,FULL)을 선택하세요. - 윈도우 함수는 전체 결과 집합을 유지하면서 행 단위로 집계, 순위 및 기타 분석을 계산할 수 있게 해줍니다. 고급 보고, 시계열 분석, 데이터 사이언스 파이프라인에 필수적입니다.
두 도구를 함께 사용하여 원시 관계형 데이터를 실행 가능한 인사이트로 전환하는 풍부하고 성능 좋은 쿼리를 작성하세요.
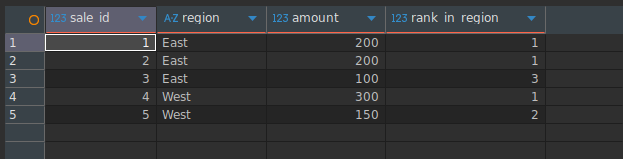
SQL에서 순위 함수
RANK()
파티션 내 각 행에 순위를 할당하며, 동점이 있을 경우 번호를 건너뜁니다.
SELECT
sale_id,
region,
amount,
RANK() OVER (
PARTITION BY region
ORDER BY amount DESC
) AS rank_in_region
FROM Sales;Result
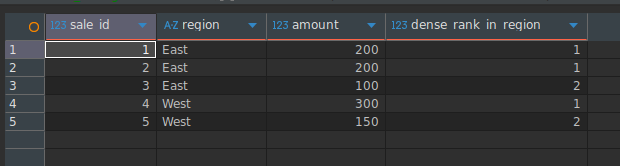
DENSE_RANK()
동점이 있더라도 번호를 건너뛰지 않고 순위를 할당합니다.
SELECT
sale_id,
region,
amount,
DENSE_RANK() OVER (
PARTITION BY region
ORDER BY amount DESC
) AS dense_rank_in_region
FROM Sales;Result
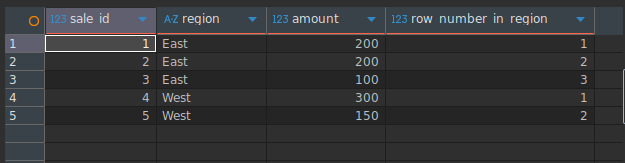
ROW_NUMBER()
결과 집합의 각 행에 고유한 순차 번호를 부여합니다.
SELECT
sale_id,
region,
amount,
ROW_NUMBER() OVER (
PARTITION BY region
ORDER BY amount DESC
) AS row_number_in_region
FROM Sales;Result
Window 함수 사용 팁
- 신중하게 파티션하기 –
PARTITION BY가 없으면 전체 테이블이 하나의 그룹으로 취급됩니다. ORDER BY확인하기 – 윈도우 내부에서 계산 순서를 결정합니다.- 성능 최적화 – 대용량 데이터셋에서는 Window 함수가 느릴 수 있으니 적절한 인덱스를 추가하는 것을 고려하세요.
결론
조인과 윈도우 함수는 결합될 때 고급 데이터 분석을 가능하게 하는 두 가지 강력한 SQL 도구입니다.
- 조인은 여러 테이블의 데이터를 하나로 모아 완전하고 의미 있는 데이터 세트를 형성합니다. 관계형 데이터베이스의 기본이며 분석, 보고, 백엔드 시스템 및 데이터‑엔지니어링 워크플로에 필수적입니다.
- 윈도우 함수는
GROUP BY와 달리 데이터를 축소하지 않고 관련 행 전체에 걸쳐 고급 계산을 수행할 수 있게 해줍니다. 각 행을 유지하면서 순위, 누적 합계, 비교 및 백분위수와 같은 인사이트를 추가합니다.