Serverless 데이터 파이프라인 마스터하기: 2026년을 위한 AWS Step Functions 모범 사례
Source: Dev.to
위 링크에 포함된 전체 텍스트를 제공해 주시면, 해당 내용을 한국어로 번역해 드리겠습니다.
AWS Step Functions – 프로덕션‑그레이드 서버리스 데이터 파이프라인
AWS Step Functions는 단순한 상태‑머신 오케스트레이터에서 현대 서버리스 데이터 엔지니어링의 핵심으로 진화했습니다. 조직이 깨지기 쉬운 모놀리식 스크립트에서 이벤트‑드리븐 아키텍처로 전환함에 따라 Step Functions는 복잡한 ETL(Extract, Transform, Load) 프로세스와 데이터 워크플로에 필요한 신뢰성, 가시성 및 확장성을 제공합니다.
하지만 “작동하는” 파이프라인을 구축하는 것과 “프로덕션‑그레이드” 파이프라인을 구축하는 것은 다릅니다. 이 가이드에서는 성능, 비용 효율성 및 유지 관리성을 중점으로 견고한 서버리스 데이터 파이프라인을 구축하기 위한 업계 표준 모범 사례를 살펴봅니다.
1️⃣ Choose the Right Workflow Type: Standard vs. Express
첫 번째이자 가장 중요한 데이터 파이프라인 설계 결정은 적절한 워크플로 유형을 선택하는 것입니다. 잘못 선택하면 불필요한 비용이 크게 증가하거나 장기 실행 프로세스를 추적할 수 없게 됩니다.
Comparison
| Feature | Standard Workflows | Express Workflows |
|---|---|---|
| Max Duration | 최대 1 년 | 최대 5 분 |
| Execution Model | Exactly‑once | At‑least‑once |
| Pricing | 상태 전환당 (≈ $25 백만당) | 기간 및 메모리 사용량 기준 |
| Use Case | 장기 실행 ETL, 인간이 개입하는 작업 | 대용량 IoT 수집, 스트리밍 |
Best Practice
- Standard Workflows – 감사 가능성과 Exactly‑once 실행이 가장 중요한 고가치·장기 실행 데이터 작업에 사용합니다.
- Express Workflows – 비용을 절감하기 위해 높은 빈도·짧은 수명의 작업(예: 개별 SQS 메시지 처리 또는 API 변환) 등에 사용합니다.
Source:
2️⃣ 대용량 페이로드를 위한 “클레임 체크” 패턴 구현
Step Functions은 상태 간에 전달되는 입력 및 출력 페이로드에 256 KB 제한을 적용합니다. 데이터 파이프라인에서는 원시 데이터 조각이나 큰 배열을 JSON 메타데이터로 전달하면 이 제한을 쉽게 초과할 수 있습니다.
❌ 나쁜 관행 – 원시 데이터 직접 전달
큰 Base64‑인코딩 문자열이나 방대한 JSON 배열을 상태 출력에 직접 포함하면 결국 States.DataLimitExceeded 오류로 실행이 실패합니다.
✅ 좋은 관행 – S3 포인터 사용
데이터를 S3 버킷에 저장하고 S3 URI(포인터)를 상태 간에 전달합니다. 이것이 고전적인 클레임 체크 패턴입니다.
예시 (ASL 정의)
// BAD: Passing raw data results in a failure
{
"StartAt": "ProcessData",
"States": {
"ProcessData": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ProcessBigData",
"End": true
}
}
}// GOOD: Passing an S3 reference
{
"StartAt": "ProcessData",
"States": {
"ProcessData": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ProcessBigData",
"Parameters": {
"s3Bucket": "my-data-pipeline-bucket",
"s3Key": "input/raw_file.json"
},
"ResultPath": "$.s3OutputPointer",
"End": true
}
}
}왜 중요한가: 파이프라인은 데이터 자체가 아니라 메타데이터만 처리하므로 데이터 양이 100배 증가해도 안정적으로 동작합니다.
Source:
3️⃣ 고급 오류 처리 및 재시도
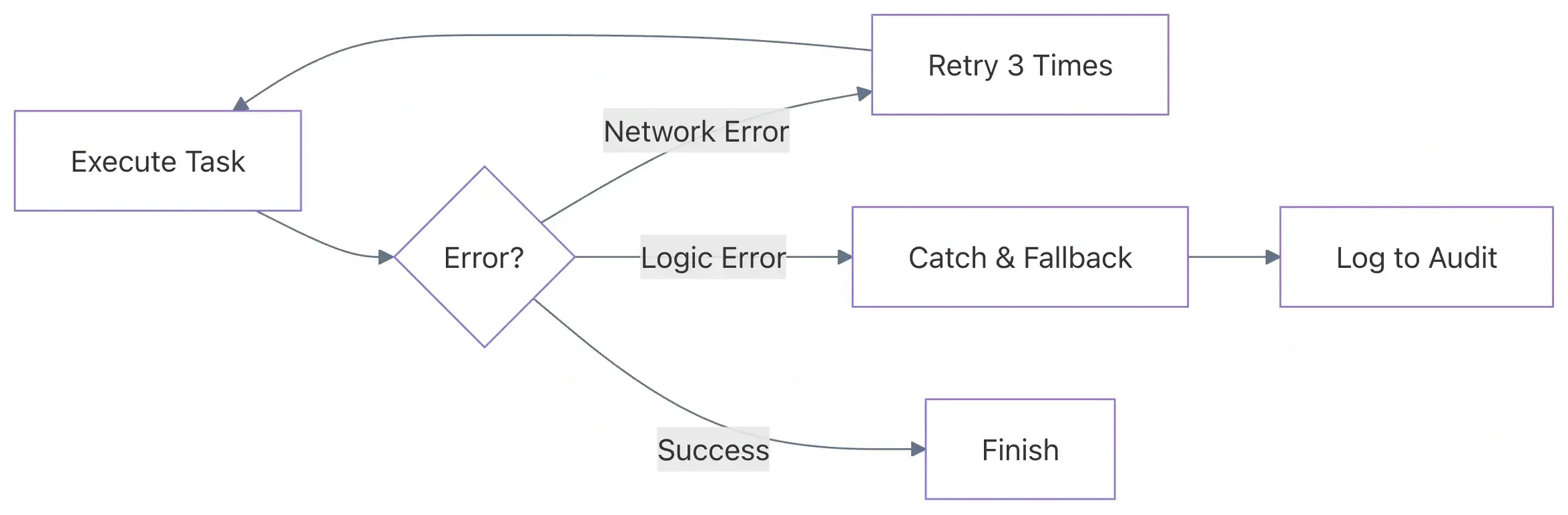
분산 시스템에서는 일시적인 오류(네트워크 타임아웃, 서비스 제한, Lambda 콜드 스타트)가 불가피합니다. 견고한 데이터 파이프라인은 자체 복구가 가능해야 합니다.
❌ 함정 – 범용 캐치‑올
모든 오류에 대해 하나의 Catch 블록만 사용하는 것—또는 더 나아가 재시도를 전혀 사용하지 않는 것—은 수동 개입을 요구하고 데이터 손실 위험을 초래합니다.
✅ 모범 사례 – 지수 백오프를 적용한 구체적인 재시도
오류 유형별로 목표가 되는 재시도 전략을 구성합니다. 예를 들어, AWS 서비스 제한은 사용자 정의 비즈니스 로직 오류와 다르게 처리해야 합니다.
좋은 예 (지터가 포함된 재시도)
"Retry": [
{
"ErrorEquals": [
"Lambda.TooManyRequestsException",
"Lambda.ServiceException"
],
"IntervalSeconds": 2,
"MaxAttempts": 5,
"BackoffRate": 2.0,
"JitterStrategy": "FULL"
},
{
"ErrorEquals": ["CustomDataValidationError"],
"MaxAttempts": 0
}
]왜 중요한가: 지수 백오프는 하위 리소스(RDS, DynamoDB 등)에서 “천둥‑무리” 문제를 방지합니다. 지터를 추가하면 동시에 실패한 100개의 동시 실행이 정확히 같은 밀리초에 재시도하는 상황을 피할 수 있습니다.
4️⃣ 내재 함수 활용으로 Lambda 사용 최소화
많은 개발자들이 문자열 연결, 타임스탬프 생성, 간단한 산술 연산과 같은 사소한 작업을 위해 Lambda 함수를 호출합니다. 각 Lambda 호출은 지연 시간과 비용을 증가시킵니다.
❌ 나쁜 관행 – “Helper” Lambda
두 문자열을 결합하거나 값이 null인지 확인하기 위해 Lambda 함수를 호출하는 경우.
✅ 좋은 관행 – ASL 내재 함수
Step Functions는 상태 머신 정의 내에서 직접 이러한 작업을 수행할 수 있는 내장 함수를 제공합니다.
예시: 고유 ID 생성
{
"Parameters": {
"TransactionId.$": "States.UUID()",
"Timestamp.$": "States.Format('yyyy-MM-dd\'T\'HH:mm:ss.SSSZ', $$.Execution.StartTime)"
}
}왜 중요한가: 불필요한 Lambda 호출을 없애면 지연 시간과 비용을 모두 줄일 수 있으며, 워크플로 정의를 간결하고 유지 관리하기 쉽게 만들 수 있습니다.
📌 요약
| 영역 | 프로덕션 수준 권장 사항 |
|---|---|
| 워크플로우 유형 | 장기 실행·감사 가능한 작업에는 Standard를, 고빈도·단시간 작업에는 Express를 선택합니다. |
| 페이로드 크기 | Claim Check 패턴을 사용해 큰 데이터를 S3에 저장하고 URI만 전달합니다. |
| 오류 처리 | 지수 백오프와 지터를 적용한 세분화된 Retry 정책을 구현하고, 범용 잡기를 피합니다. |
| Lambda 사용 | 간단한 변환에는 ASL 내장 함수를 선호합니다. |
| 비용 및 성능 | 상태 전이를 최소화하고 불필요한 Lambda 호출을 피하며, 적절한 워크플로우 유형을 선택합니다. |
이러한 모범 사례를 적용하면 신뢰성, 가시성, 비용 효율성, 프로덕션 준비가 된 서버리스 데이터 파이프라인을 구축할 수 있습니다. 오케스트레이션을 즐기세요!
Intrinsic Functions Example
{
"Id.$": "States.UUID()",
"Message.$": "States.Format('Processing item {} at {}', $.itemId, States.FormatDateTime(States.Now(), 'yyyy-MM-dd'))"
}Commonly Used Intrinsic Functions
| Function | Description |
|---|---|
States.Array | 여러 값을 배열로 결합합니다. |
States.JsonToString | JSON 객체를 문자열로 변환하여 로그 또는 SQS 메시지에 사용합니다. |
States.MathAdd | 기본 산술 연산을 수행합니다. |
States.StringToJson | 문자열을 다시 JSON으로 파싱합니다. |
Why it matters: 왜 중요한가: 내재 함수는 Step Functions 서비스에 의해 실행되며, 실행당 추가 비용이 없고(상태 전환 비용을 제외) Lambda 함수의 콜드 스타트와 비교했을 때 실행 지연이 전혀 없습니다.
5. Distributed Map을 활용한 고성능 병렬 처리
대규모 데이터 처리 작업(예: S3에 있는 수백만 개의 CSV 행 처리)의 경우 기존 Map 상태만으로는 부족합니다. AWS는 Distributed Map을 도입했으며, 최대 10,000개의 병렬 실행을 수행할 수 있습니다.
모범 사례: 아이템 배칭
Distributed Map을 사용할 때 레코드가 작다면 실행당 하나의 레코드를 처리하지 않도록 하세요. 대신 ItemBatching을 사용합니다.
왜?
예를 들어 100만 행을 개별적으로 처리하면 100만 번의 상태 전환 비용이 발생합니다. 이를 1 000개씩 배치하면 전환 비용이 1 000번으로 감소합니다.
예시 구성
{
"MapState": {
"Type": "Map",
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
}
},
"ItemBatcher": {
"MaxItemsPerBatch": 1000
},
"MaxConcurrency": 1000,
"Iterator": {
// Processing logic here
}
}
}6. 보안 및 가시성
최소 권한 IAM 역할
상태 머신에 “갓모드” IAM 역할을 절대 사용하지 마세요. 각 상태 머신은 해당 머신이 상호 작용하는 리소스(특정 S3 버킷, 특정 Lambda 함수)만을 대상으로 권한을 제한한 고유한 IAM 역할을 가져야 합니다.
로깅 및 X‑Ray
Step Functions에 AWS X‑Ray 추적을 활성화하세요. 이를 통해 여러 AWS 서비스에 걸친 전체 요청 경로를 시각화할 수 있어 병목 현상을 쉽게 파악할 수 있습니다.
로깅 구성 모범 사례:
- 프로덕션 환경에서는 로그 레벨을
ERROR로 설정합니다. - 개발 또는 디버깅 시에만
ALL을 사용하세요. 모든 상태 입력/출력을 로깅하면 대용량 파이프라인에서 CloudWatch 비용이 크게 증가할 수 있습니다.
요약 표: 해야 할 일과 하지 말아야 할 일
| 실행 항목 | 해야 할 일 | 하지 말아야 할 일 |
|---|---|---|
| 페이로드 | 대용량 데이터에는 S3 URI 포인터를 사용하세요. | 대용량 JSON 객체를 직접 전달하지 마세요. |
| 로직 | 기본 작업에는 Intrinsic Functions를 사용하세요. | 간단한 문자열 조작에 Lambda 함수를 트리거하지 마세요. |
| 재시도 | 지수 백오프와 지터를 사용하세요. | 모든 오류에 대해 고정 간격을 사용하지 마세요. |
| 병렬 처리 | 대규모 S3 데이터셋에는 Distributed Map을 사용하세요. | 수백만 항목에 표준 Map을 사용하지 마세요. |
| 비용 | 고볼륨 로직에는 Express Workflows를 사용하세요. | 단순하고 고빈도 작업에는 Standard Workflows를 사용하지 마세요. |
Common Pitfalls to Avoid
- Ignoring the History Limit: Standard Step Functions have a history limit of 25 000 events. For loops that run thousands of times, use a Distributed Map or Child Workflows to avoid hitting this limit.
- Hard‑coding Resource ARNs: Use environment variables or CloudFormation/Terraform references to inject ARNs into your ASL definitions. Hard‑coding makes it impossible to manage Dev/Staging/Prod environments.
- Tightly Coupling States: Avoid making states too dependent on the specific JSON structure of the previous state. Use
InputPath,OutputPath, andResultSelectorto map only the necessary data.
결론
AWS Step Functions는 서버리스 데이터 파이프라인을 연결하는 “접착제” 역할을 합니다. 모듈성을 구현하고, 대용량 페이로드에 Claim‑Check 패턴을 활용하며, 내재 함수를 이용함으로써 확장 가능하고 비용 효율적이며 디버깅이 쉬운 파이프라인을 구축할 수 있습니다.
명확성과 복원력을 최우선으로 최적화하세요. 모니터링이 쉽고 장애 발생 시 자동으로 복구되는 파이프라인은 새벽 3 시에 수동으로 재시작해야 하는 약간 더 빠른 파이프라인보다 더 큰 가치를 가집니다.
데이터 파이프라인에 Step Functions를 사용하고 계신가요? 팀에 잘 맞는 다른 패턴을 찾으셨다면 댓글로 알려주세요!