선도적인 Inference 제공업체, NVIDIA Blackwell에서 Open Source Models 사용으로 AI 비용을 최대 10배 절감
Source: NVIDIA AI Blog
AI‑powered 상호작용—헬스케어에서의 진단 인사이트부터 게임 속 캐릭터 대화, 그리고 자율 고객 서비스 에이전트에 이르기까지—는 모두 동일한 지능 단위인 token 위에 구축됩니다.
토큰 비용이 중요한 이유
AI 상호작용을 확장하면 기업은 다음과 같은 질문을 하게 됩니다: 더 많은 토큰을 감당할 수 있을까?
답은 토큰노믹스를 개선하는 데 있습니다—각 토큰의 비용을 줄이는 실천입니다.
최근 MIT 연구는 인프라와 알고리즘의 진보가 최첨단 성능에 대한 추론 비용을 연간 최대 10배까지 낮추고 있음을 보여줍니다.
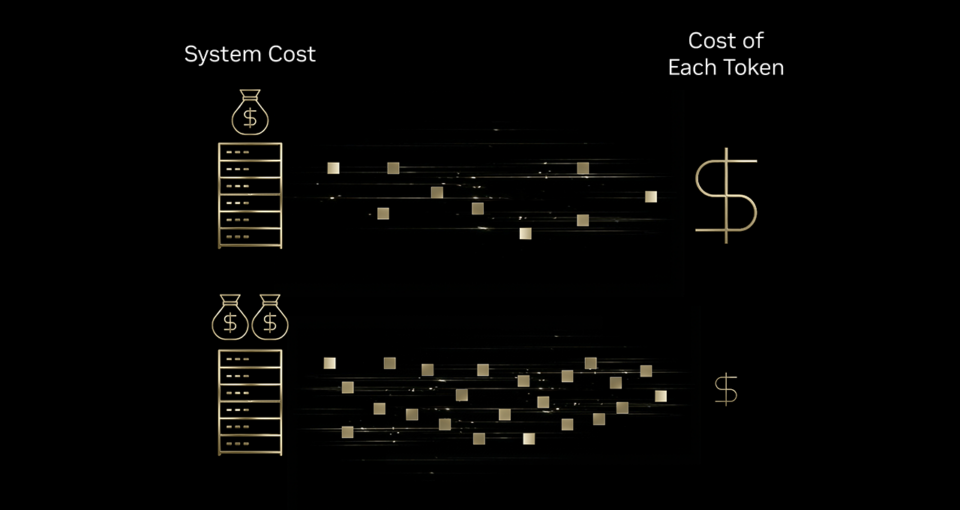
인프라 효율성 = 더 나은 토크노믹스
고속 인쇄기를 생각해 보세요:
- 프린터가 잉크, 에너지, 기계 비용을 약간만 늘려도 10배 더 많은 페이지를 생산할 수 있다면, 페이지당 비용이 크게 감소합니다.
마찬가지로 AI 인프라에 대한 투자는 전체 비용을 크게 늘리지 않으면서 토큰 생산량을 훨씬 더 많이 증가시켜 토큰당 비용을 의미 있게 낮춥니다.
누가 앞장서고 있나요?
Leading inference providers are already leveraging the NVIDIA Blackwell platform to slash token costs:
- Baseten
- DeepInfra
- Fireworks AI
- Together AI
These providers:
- 최첨단 오픈‑소스 모델을 호스팅하며, 이 모델들은 최전선 수준의 지능에 도달했습니다.
- 오픈‑소스 인텔리전스를 NVIDIA Blackwell의 극한 하드웨어‑소프트웨어 공동 설계와 결합합니다.
- 자체 최적화된 추론 스택을 배포합니다.
The result? Up to 10× lower cost per token compared with the previous NVIDIA Hopper platform, unlocking dramatic savings for businesses across every industry.
Takeaway
토큰 경제를 개선하는 것은 단순한 기술적 조정이 아니라, 기업이 AI 상호작용을 저렴하게 확장할 수 있게 하는 전략적 레버입니다. NVIDIA Blackwell과 같은 최첨단 인프라를 도입함으로써 조직은 비용을 억제하면서도 더 풍부하고 빈번한 AI 경험을 제공할 수 있습니다.
의료 – Baseten 및 Sully.ai
AI 추론 비용을 10배 절감
헬스케어 분야에서는 의료 코딩, 문서화, 보험 양식 관리와 같은 지루하고 시간이 많이 소요되는 작업이 의사가 환자와 보낼 수 있는 시간을 잠식합니다.
Sully.ai는 의료 코딩 및 메모 작성과 같은 일상 업무를 자동화하는 “AI 직원”을 만들어 이 문제를 해결합니다. 플랫폼이 성장하면서 자체 폐쇄형 모델이 다음과 같은 세 가지 주요 병목 현상을 초래했습니다:
| 병목 현상 | 영향 |
|---|---|
| 예측 불가능한 지연 | 실시간 임상 워크플로우가 느려짐 |
| 증가하는 추론 비용 | 비용이 매출보다 빠르게 증가 |
| 제한된 모델 제어 | 품질이나 업데이트를 미세 조정할 수 없음 |
솔루션
Sully.ai는 Baseten’s Model API 로 전환하여 NVIDIA Blackwell GPU 에서 오픈소스 모델(예: gpt‑oss‑120b)을 배포했습니다. 스택에는 다음이 포함됩니다:
- NVFP4 저정밀 데이터 포맷 – 효율적인 추론을 위해 설계
- NVIDIA TensorRT‑LLM 라이브러리 – 최적화된 실행 제공
- NVIDIA Dynamo 추론 프레임워크 – 배포를 간소화
Baseten은 기존 Hopper 기반 설정에 비해 달러당 최대 2.5배 더 나은 처리량을 확인하고 Blackwell GPU를 선택했습니다.
결과
| 지표 | 개선 |
|---|---|
| 추론 비용 | ↓ 90 % (≈ 10배 감소) |
| 응답 시간 | ↑ 65 % 더 빠른 핵심 워크플로우 (예: 의료 메모 생성) |
| 의사 시간 절감 | > 3천만 분 회복 |
링크
- Sully.ai website
- Baseten case study: 30 M clinical minutes saved
- NVFP4 data format announcement
- NVIDIA Dynamo inference framework
Gaming — DeepInfra와 Latitude 토큰당 비용을 4× 절감
Latitude는 AI Dungeon 어드벤처 스토리 게임과 곧 출시될 AI 기반 롤플레잉 플랫폼 Voyage를 통해 AI‑네이티브 게임의 미래를 구축하고 있습니다. 플레이어는 자유롭게 행동을 선택하고 자신만의 이야기를 만들며 세계를 탐험할 수 있습니다.
The Challenge
- 각 플레이어 행동은 대형 언어 모델(LLM)에 대한 추론 요청을 트리거합니다.
- 참여도가 높아질수록 비용이 증가하지만, 응답 시간은 경험을 끊김 없이 유지할 만큼 빠르게 유지되어야 합니다.
The Solution
Latitude는 DeepInfra의 추론 플랫폼에서 대형 오픈소스 모델을 실행합니다. 이 플랫폼은 NVIDIA Blackwell GPU와 TensorRT‑LLM으로 구동됩니다.
대규모 mixture‑of‑experts (MoE) 모델에 대해 DeepInfra는 토큰당 비용을 다음과 같이 낮췄습니다:
| 플랫폼 | 비용 / 1 M 토큰 |
|---|---|
| NVIDIA Hopper (baseline) | $0.20 |
| Blackwell (FP16) | $0.10 |
| Blackwell (NVFP4, low‑precision) | $0.05 |
Result: 고객이 기대하는 정확성을 유지하면서 토큰당 비용을 4배 절감했습니다.
Benefits for Latitude
- 트래픽 급증 시에도 빠르고 안정적인 응답 제공.
- 플레이어 경험을 손상시키지 않으면서 더 강력한 모델을 배포할 수 있음.
- 플레이어 참여도가 증가함에 따라 비용 효율적인 확장 가능.

Latitude의 텍스트 기반 어드벤처 “AI Dungeon”은 플레이어가 동적인 이야기를 탐험하는 동안 실시간으로 내러티브 텍스트와 이미지를 생성합니다.
Source: https://example.com/source-link
Agentic Chat — Fireworks AI와 Sentient Foundation이 AI 비용을 최대 50 % 절감
Sentient Labs는 AI 개발자를 모아 강력한 오픈‑소스 추론 AI 시스템을 구축합니다. 그들의 사명은 다음 분야의 연구를 통해 더 어려운 추론 문제에 대한 AI 발전을 가속화하는 것입니다:
- 안전한 자율성
- 에이전시 아키텍처
- 지속적 학습
Sentient Chat
Sentient Chat은 Sentient Labs의 첫 번째 애플리케이션입니다. 이 서비스는:
- 복잡한 다중‑에이전트 워크플로를 오케스트레이션하고
- 커뮤니티가 기여한 10여 개 이상의 특화된 AI 에이전트를 통합합니다
단일 사용자 질의가 자동화된 상호작용의 연쇄를 촉발할 수 있기 때문에, 서비스는 엄청난 연산 요구량을 가지며 인프라 비용이 크게 발생합니다.
비용 절감이 달성된 방법
Sentient Labs는 Fireworks AI의 추론 플랫폼(NVIDIA Blackwell GPU 기반) 으로 전환했습니다. Blackwell에 최적화된 추론 스택은 기존 Hopper 기반 배포 대비 25‑50 % 더 높은 비용 효율성을 제공했습니다.
주요 결과
- GPU당 처리량 증가 → 동일 비용으로 더 많은 동시 사용자 지원
- 확장 가능한 플랫폼 덕분에 24시간 내에 180만 명의 대기자가 몰리는 바이럴 런칭 가능
- 한 주에 560만 건의 질의를 처리하면서도 낮은 지연 시간 유지
“Fireworks의 Blackwell‑최적화 추론 스택을 사용함으로써 Sentient은 이전 Hopper 기반 배포 대비 25‑50 % 더 나은 비용 효율성을 달성했습니다.” – Sentient Labs
시각적 개요
자세히 알아보기
- Fireworks AI에서 전체 이야기를 읽어보세요.
고객 서비스 — Together AI와 Decagon이 비용을 6배 절감
음성 AI를 이용한 고객 서비스 전화는 종종 좌절감으로 끝납니다. 약간의 지연만 있어도 사용자는 에이전트와 말을 겹치게 되거나 전화를 끊고, 신뢰를 잃게 됩니다.
Decagon은 기업 고객 지원을 위한 AI 에이전트를 구축하고 있으며, 음성은 가장 까다로운 채널입니다. 회사는 예측할 수 없는 트래픽 부하에서도 서브‑초 응답을 제공하면서 24/7 음성 배포에 대한 토큰 경제성을 유지할 수 있는 인프라가 필요했습니다.
솔루션
Together AI는 NVIDIA Blackwell GPU에서 Decagon의 멀티모델 음성 스택에 대한 프로덕션 추론을 실행합니다. 양사는 다음과 같은 핵심 최적화를 공동으로 진행했습니다:
| 최적화 | 설명 |
|---|---|
| 추측 디코딩 | 작은 “드래프트” 모델이 빠른 응답을 생성하고, 큰 모델이 백그라운드에서 정확성을 검증합니다. |
| 대화 캐싱 | 자주 반복되는 대화 요소를 캐시하여 응답 생성 속도를 높입니다. |
| 자동 스케일링 | 동적 스케일링으로 트래픽 급증을 처리하면서 성능 저하를 방지합니다. |
결과
- 응답 시간: 크게 단축되어 원활한 음성 상호작용이 가능해졌습니다.
- 토큰당 비용: 기존 Hopper 기반 배포 대비 최대 6배 낮아졌습니다.
NVIDIA의 극한 코드 설계는 컴퓨팅, 네트워킹, 소프트웨어 등 스택 전반에 걸쳐 이루어지며, 파트너 생태계와 함께 토큰당 비용을 대규모로 크게 낮추고 있습니다. 이러한 흐름은 NVIDIA Rubin 플랫폼을 통해 계속됩니다. 이 플랫폼은 여섯 개의 새로운 칩을 단일 AI 슈퍼컴퓨터에 통합하여 Blackwell 대비 10배 성능과 10배 낮은 토큰 비용을 제공합니다.
자세히 알아보기
NVIDIA의 풀‑스택 추론 플랫폼을 살펴보고 AI 추론을 위한 토큰 경제성이 어떻게 개선되는지 확인하세요: