나는 Web Scraping을 위해 15개의 LLM을 테스트하고 대신 휴리스틱을 구축했다
Source: Dev.to
(번역을 원하는 본문을 제공해 주시면 한국어로 번역해 드리겠습니다.)
아무도 말하지 않는 문제: 600KB DOM
웹 스크래퍼를 만들기 시작했을 때 가장 직관적인 방법은 페이지를 LLM에 보내고 데이터를 추출하도록 요청하는 것이었습니다. 간단하죠?
틀렸습니다. 일반적인 제품 목록 페이지는 원시 DOM만 500–700 KB 정도 됩니다. 이를 어떤 모델에 보내도 페이지당 약 150,000 토큰을 사용하게 되고, 요청당 15–30 초를 기다려야 하며, 복잡한 작업에서는 컨텍스트 제한에 걸리게 됩니다.
첫 페이지에서 바로 이 장벽에 부딪혔습니다.
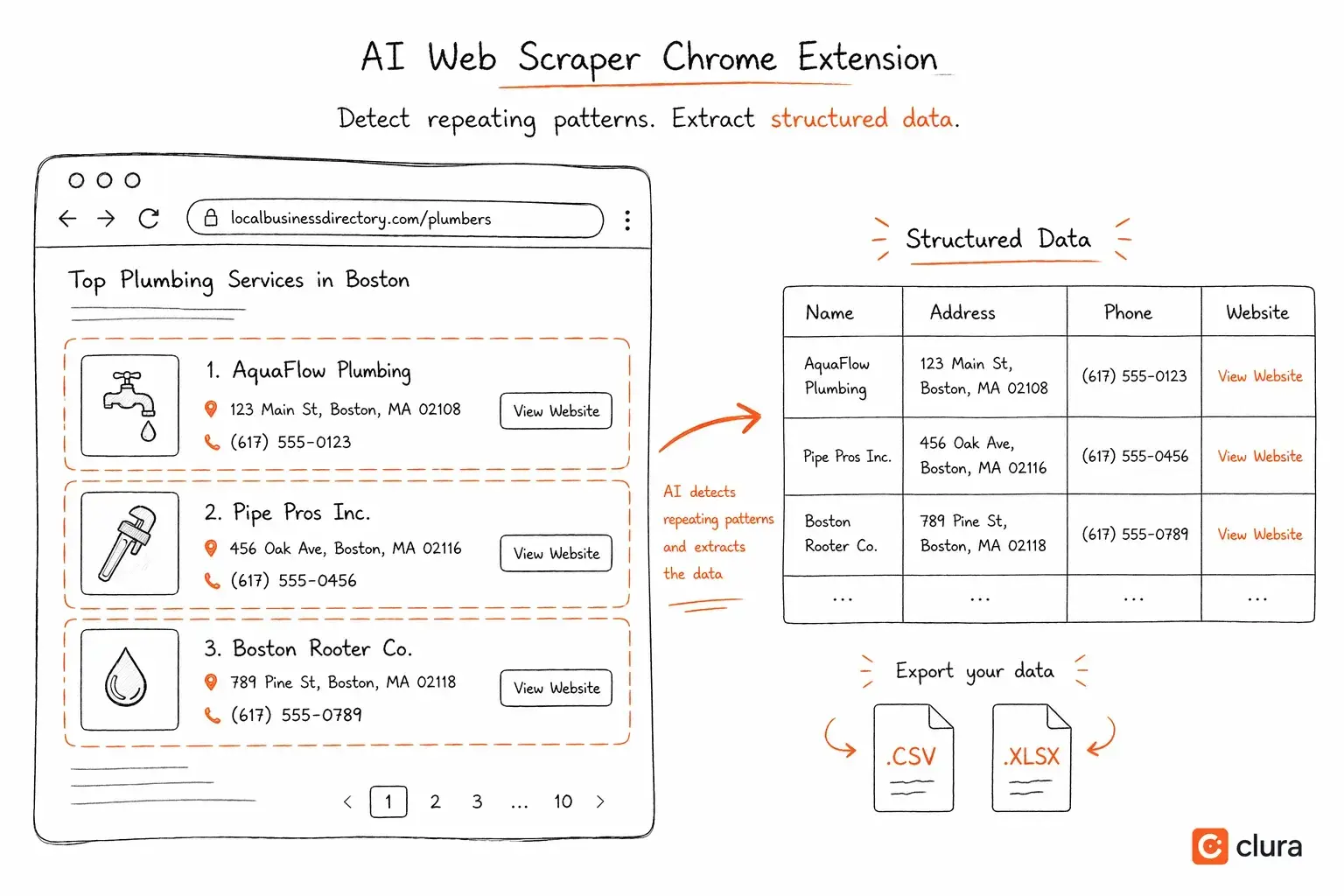
4개월, 15개 모델, 같은 결과
모든 모델을 테스트했습니다: GPT‑4, GPT‑4o, Gemini 1.5 Pro, Gemini Ultra, Claude 3 Opus, Claude 3.5 Sonnet, Mistral Large, Llama 3 70B, Cohere Command R+, 그리고 몇몇 작은 파인‑튜닝 모델들.
결과는 일관되었습니다:
- GPT‑4 / Gemini Ultra: 정확하지만 페이지당 25–35초 소요
- Claude 3.5 Sonnet: 정확도‑지연 비율이 가장 좋지만 여전히 5–10초
- 소형 모델: 더 빠르지만 필드 이름을 지속적으로 환각처럼 생성
어떤 모델도 지연 시간 문제를 해결하지 못했습니다. 왜냐하면 제가 그들에게 잘못된 문제를 해결하도록 요청했기 때문입니다.
전처리기 혁신
실제 문제는 모델이 아니라 입력 크기였습니다.
DOM 전처리기를 만들었습니다:
- 모든
,, 및 트래킹 픽셀 제거 - 네비게이션, 푸터, 사이드바 요소 삭제
- 의미 있는 콘텐츠가 없는 깊게 중첩된 래퍼를 압축
- SimHash를 적용해 구조적으로 동일한 서브 트리를 중복 제거
결과: 580 KB → 4.2 KB (99.3 % 감소).
입력이 4 KB가 되면 모든 모델이 빨라졌습니다. 하지만 더 흥미로운 일이 일어났습니다: 그 크기에서는 반복 패턴이 명확해졌습니다. 동일한 구조가 20번, 50번, 100번씩 반복되었습니다 — 제품 카드, 디렉터리 행, 검색 결과 등.
아키텍처 결정
패턴이 구조만으로도 이미 명확하다면, 모델에게 찾게 할 이유가 무엇인가요?
나는 휴리스틱 탐지기를 작성했습니다:
- 3개 이상의 구조적으로 동일한 형제 요소 식별
- 깊이, 자식 수 균일성, 텍스트 밀도로 후보 리스트 점수 매기기
~0 ms 안에 순위가 매겨진 리스트 후보 반환.
그 다음 AI는 탐지 후에 개입합니다 — 리스트를 식별하기 위해서가 아니라 필드를 라벨링하고 출력을 구조화하기 위해서입니다. 이는 약 ~200 토큰 작업이며, 150,000 토큰 작업이 아닙니다.
| 단계 | 접근 방식 | 지연 시간 |
|---|---|---|
| 리스트 탐지 | 휴리스틱 | 0.2 ms |
| 필드 라벨링 | LLM (소량 입력) | ~2 s |
| 총합 | — | ~2 s |
vs. 순진한 LLM 접근 방식: 25–35 초.
실제로 배포한 내용
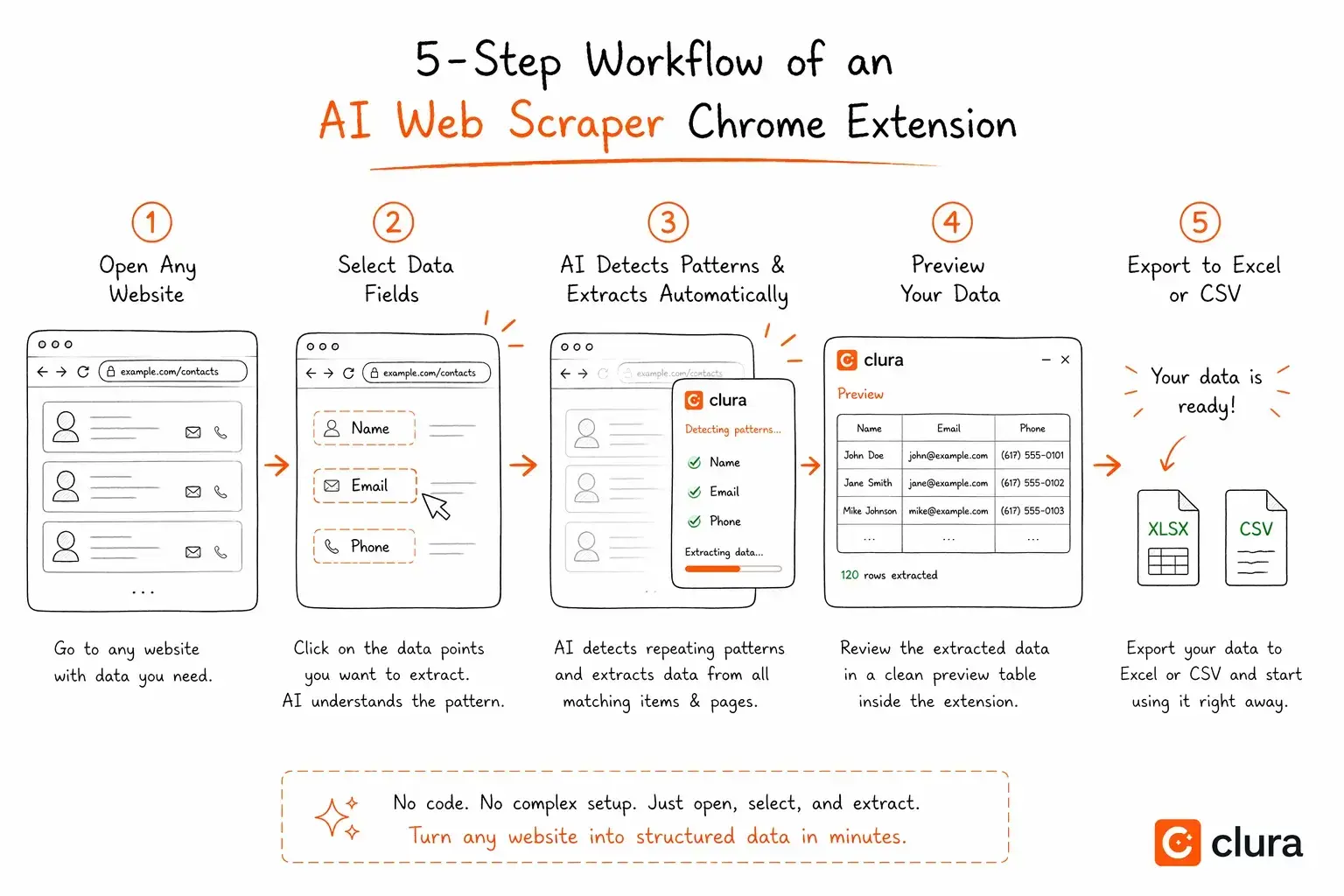
이 아키텍처는 **Clura — 휴리스틱‑우선 AI 웹 스크래퍼 Chrome 확장 프로그램**이 되었습니다.
어떤 페이지든 열면, Clura는 휴리스틱 엔진을 사용해 모든 목록을 자동으로 감지합니다. 목록을 선택하고 원하는 필드를 선택하면, 몇 초 안에 모든 레코드를 추출합니다. “describe what you want” 프롬프트가 없습니다. 로봇 훈련도 없습니다. 30‑초 대기 시간도 없습니다. 휴리스틱 레이어가 감지를 담당하고, AI가 라벨링을 담당합니다.
교훈
LLM은 어떤 것이 의미하는 무엇을 이해하는 데는 뛰어납니다. 하지만 600 KB의 HTML을 스캔해 어디에 있는지를 찾는 것은 형편없습니다. 이는 구조적 패턴 문제이며, 구조적 패턴 문제는 알고리즘이 해결하는 분야입니다.
제가 찾은 최고의 AI 제품 아키텍처는 “최고의 모델을 사용한다”는 것이 아니라, “문제를 축소하는 휴리스틱을 사용해 모델이 실제로 잘 할 수 있는 부분만 보게 만든다”는 것입니다.
만약 여러분이 복잡한 실제 입력을 다루는 LLM 기반 무언가를 구축하고 있다면, DOM 사전 처리 단계만으로도 충분히 도입할 가치가 있습니다. 이는 사용 중인 모든 모델을 더 빠르고, 저렴하며, 더 정확하게 만들어 줍니다 — 기본 작업이 무엇이든 관계없이.
이 기능을 직접 보고 싶다면, Clura를 무료로 사용해 보세요 — 감지를 위해 서버 왕복 없이 완전히 브라우저에서 실행됩니다.