첫 AI 에이전트를 만드는 방법 및 Sevalla에 배포하기
Source: Dev.to
몇 년 전만 해도, 대화하고, 결정을 내리며, 외부 데이터를 활용할 수 있는 코드를 작성하는 것이 어려웠습니다.
오늘날, 새로운 도구 덕분에 개발자들은 메시지를 읽고, 그에 대해 추론하며, 스스로 함수를 호출할 수 있는 스마트 에이전트를 만들 수 있습니다.
그러한 플랫폼 중 하나가 LangChain 입니다. LangChain을 사용하면 언어 모델, 도구, 앱을 연결하고, 에이전트를 FastAPI 서버에 래핑한 뒤, 클라우드 플랫폼에 배포할 수 있습니다.
이 기사에서는 첫 번째 AI 에이전트를 구축하는 과정을 단계별로 안내합니다. LangChain이 무엇인지, 에이전트를 어떻게 구축하고, FastAPI를 통해 서비스를 제공하며, Sevalla에 배포하는 방법을 배울 수 있습니다.
Source:
LangChain이란
LangChain은 대형 언어 모델을 다루기 위한 프레임워크입니다. 생각하고, 추론하고, 행동하는 애플리케이션을 만드는 데 도움을 줍니다.
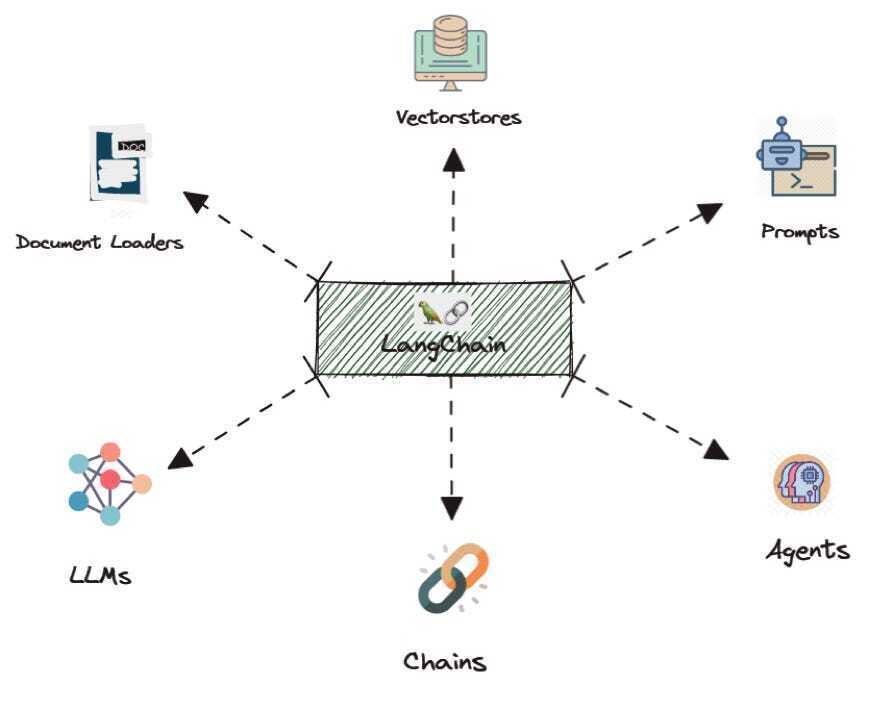
모델 자체는 텍스트 응답만 제공하지만, LangChain을 사용하면 함수 호출, 도구 활용, 데이터베이스 연결, 워크플로우 수행 등 더 많은 작업을 할 수 있습니다.
LangChain을 다리로 비유하면:
- 한쪽: 언어 모델.
- 다른 쪽: 여러분의 도구, 데이터 소스, 비즈니스 로직.
LangChain은 모델에게 어떤 도구가 존재하는지, 언제 사용해야 하는지, 어떻게 응답해야 하는지를 알려줍니다. 이를 통해 질문에 답하고, 작업을 자동화하며, 복잡한 흐름을 처리하는 에이전트를 구축하기에 이상적입니다.
- 유연함 – 다양한 AI 모델을 지원합니다.
- Python‑우선 – 대부분의 데이터 사이언스 및 백엔드 스택에 자연스럽게 녹아듭니다.
- 프로덕션‑준비 – 에이전트를 만드는 방법을 알면 이 패턴을 더 복잡한 사용 사례에 재사용할 수 있습니다.
저는 최근에 **LangChain 튜토리얼**을 자세히 공개했습니다.
LangChain으로 첫 번째 에이전트 만들기
필요할 때 도구를 호출할 수 있는 간단한 에이전트를 만들어 보겠습니다. 더미 날씨 도구를 제공하고, 특정 도시의 날씨를 물어보는 예시입니다.
-
.env파일을 만들고 OpenAI API 키를 추가합니다 (LangChain이 자동으로 읽어들입니다):OPENAI_API_KEY= -
에이전트 코드를 작성합니다:
from langchain.agents import create_agent from dotenv import load_dotenv # 환경 변수 로드 load_dotenv() # LLM이 호출할 수 있는 도구 정의 def get_weather(city: str) -> str: """주어진 도시의 날씨를 가져옵니다.""" return f"It's always sunny in {city}!" # 에이전트 생성 agent = create_agent( model="gpt-4o", tools=[get_weather], system_prompt="You are a helpful assistant" ) # 에이전트 호출 result = agent.invoke( {"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}]} ) print(result)
무슨 일이 일어나고 있나요?
create_agent는 지정된 모델을 기반으로 에이전트를 구축합니다.get_weather는 도구이며, 에이전트가 호출할 수 있는 파이썬 함수입니다.- 시스템 프롬프트는 에이전트에게 역할을 알려줍니다.
agent.invoke는 사용자 메시지를 전송하고, 에이전트는get_weather를 호출할지 결정한 뒤 응답을 반환합니다.
예제가 작지만 핵심 아이디어를 잘 보여줍니다: 에이전트는 자연어를 읽고, 사용할 도구를 선택하고, 호출한 뒤 답변을 제공합니다.
FastAPI로 에이전트 래핑하기
이제 에이전트를 HTTP 엔드포인트로 노출하여 다른 서비스가 상호작용할 수 있게 합니다. FastAPI를 사용하면 매우 간단합니다.
-
필요한 패키지를 설치합니다:
pip install fastapi uvicorn python-dotenv langchain -
main.py파일을 생성합니다:from fastapi import FastAPI from pydantic import BaseModel import uvicorn from langchain.agents import create_agent from dotenv import load_dotenv import os load_dotenv() # 도구 정의 def get_weather(city: str) -> str: """주어진 도시의 날씨를 가져옵니다.""" return f"It's always sunny in {city}!" # 에이전트 생성 agent = create_agent( model="gpt-4o", tools=[get_weather], system_prompt="You are a helpful assistant", ) app = FastAPI() class ChatRequest(BaseModel): message: str @app.get("/") def root(): return {"message": "Welcome to your first agent"} @app.post("/chat") def chat(request: ChatRequest): result = agent.invoke( {"messages": [{"role": "user", "content": request.message}]} ) # 응답 형식은 상황에 따라 다를 수 있으니 필요에 맞게 조정하세요 reply = result["messages"][-1].content if "messages" in result else str(result) return {"reply": reply} def main(): port = int(os.getenv("PORT", 8000)) uvicorn.run(app, host="0.0.0.0", port=port) if __name__ == "__main__": main()
작동 방식
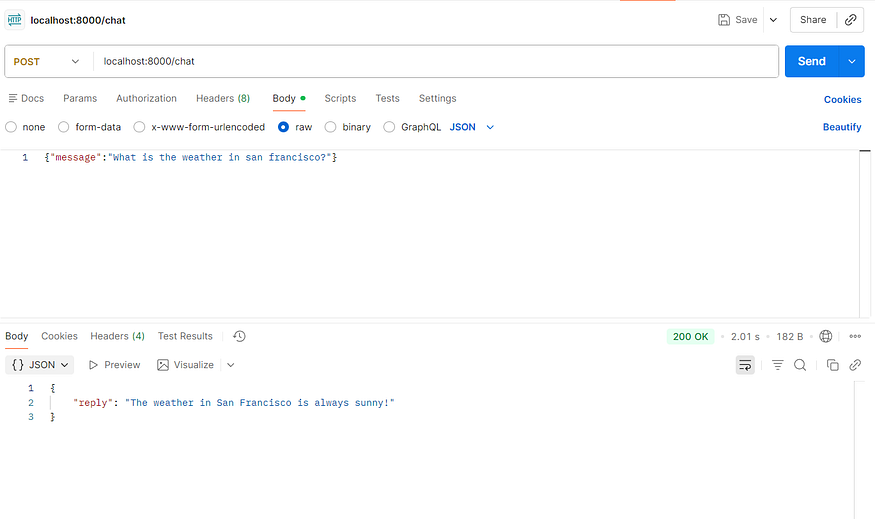
GET /– 간단한 헬스 체크.POST /chat– JSON{ "message": "Your question?" }를 받아 LangChain 에이전트에 전달하고, 에이전트의 응답을 반환합니다.
서버를 실행합니다:
python main.py이제 curl이나 Postman 같은 도구를 사용해 http://localhost:8000/chat 로 요청을 보내면, 커스텀 도구를 호출할 수도 있는 AI‑생성 답변을 받을 수 있습니다.
다음 단계
- 더미
get_weather함수를 실제 API 호출로 교체합니다. - 추가 도구를 연결합니다 (예: 데이터베이스 쿼리, 외부 서비스).
- FastAPI 앱을 Sevalla 같은 클라우드 플랫폼이나 컨테이너 오케스트레이션 서비스에 배포합니다.
FastAPI는 /chat 엔드포인트를 정의합니다. 사용자가 메시지를 보내면 서버가 에이전트를 호출하고, 에이전트는 기존과 같이 처리한 뒤 FastAPI가 깔끔한 JSON 응답을 반환합니다. API 레이어가 복잡성을 간단한 인터페이스 뒤에 숨깁니다.
이제 작동하는 에이전트 서버가 준비되었습니다. 로컬 머신에서 실행하고, Postman이나 cURL로 호출해 응답을 확인해 보세요. 정상 동작한다면 배포 준비가 완료된 것입니다.
Sevalla에 배포하기
AWS, DigitalOcean 등 원하는 클라우드 제공자를 선택해 에이전트를 호스팅할 수 있습니다. 여기서는 Sevalla를 사용합니다.
Sevalla는 개발자 친화적인 PaaS로, 애플리케이션 호스팅, 데이터베이스, 객체 스토리지, 정적 사이트 호스팅을 제공합니다. 모든 플랫폼이 클라우드 리소스에 비용을 부과하지만, Sevalla는 $50 크레딧을 제공하므로 이번 데모에서는 비용이 발생하지 않습니다.
프로젝트를 GitHub에 푸시하기
레포지토리를 GitHub에 푸시하고 자동 배포를 활성화하면 새로운 변경 사항이 자동으로 배포됩니다. 또한 원본 레포를 포크할 수도 있습니다.
- Sevalla에 로그인합니다.
- Applications → Create new application으로 이동한 뒤 GitHub 레포지토리를 연결합니다.
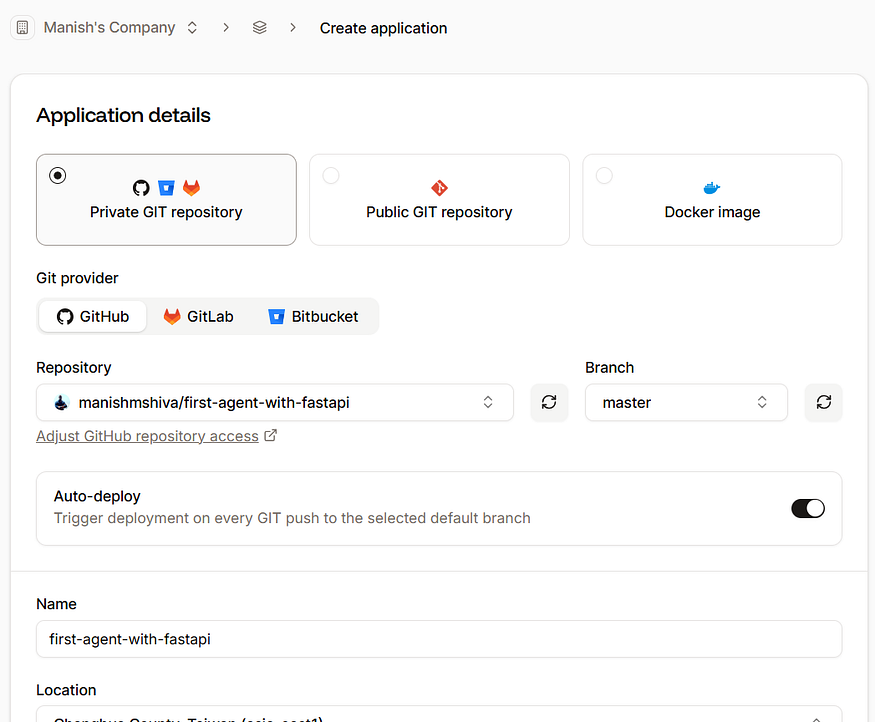
기본 설정을 그대로 사용하고 Create application을 클릭합니다.
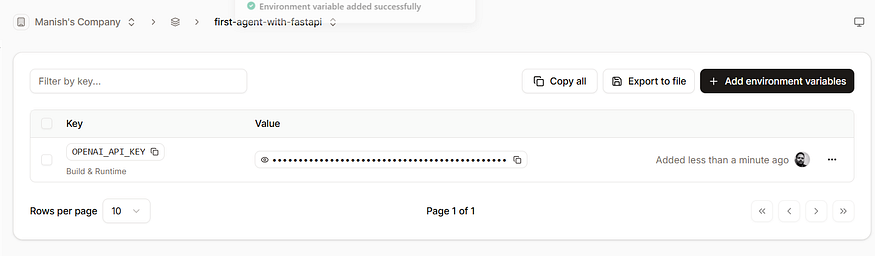
환경 변수 추가
앱이 생성된 후 Environment variables로 이동해 OpenAI 키를 추가합니다:
| 변수 | 값 |
|---|---|
OPENAI_API_KEY | your‑openai‑api‑key |
배포
-
Deployments → Deploy now로 이동합니다.
배포는 2~3분 정도 소요됩니다.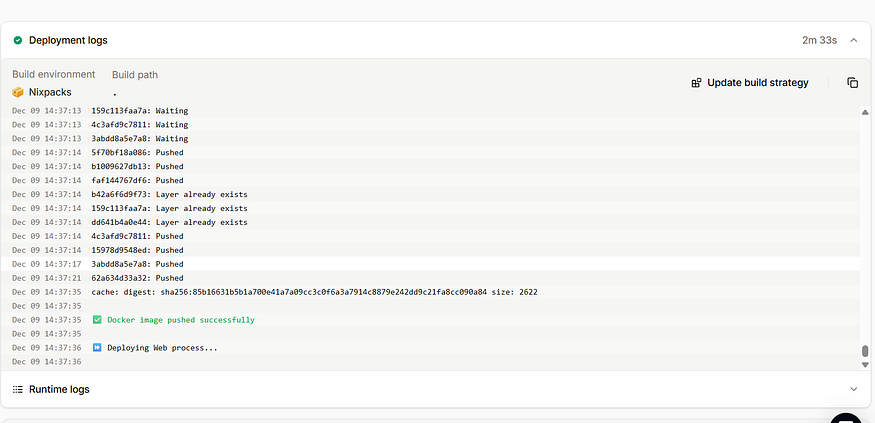
-
빌드가 완료되면 Visit app을 클릭합니다.
localhost:8000대신sevalla.app으로 끝나는 URL을 Postman이나 다른 클라이언트에 입력하면 서비스를 확인할 수 있습니다.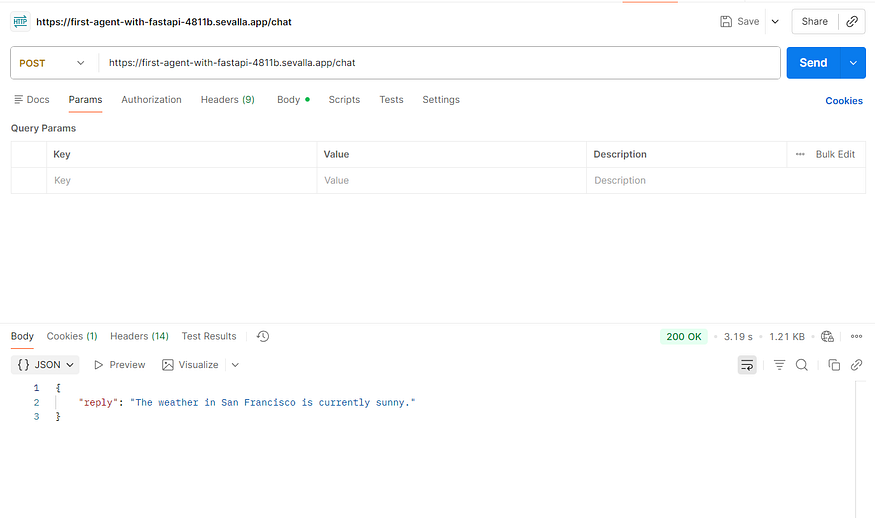
축하합니다! 도구 호출이 가능한 첫 번째 AI 에이전트가 이제 라이브 상태입니다. 더 많은 도구를 추가하거나 GitHub에 업데이트를 푸시하면 Sevalla가 자동으로 재배포합니다.
결론
AI 에이전트를 구축하는 것이 더 이상 전문가만을 위한 작업이 아닙니다. LangChain을 사용하면 몇 줄의 코드만으로 사용자에게 응답하고 함수를 자동으로 호출하는 추론 도구를 만들 수 있습니다.
에이전트를 FastAPI로 래핑하면 애플리케이션과 사용자가 접근할 수 있는 깔끔한 HTTP 입구가 제공됩니다. 마지막으로 Sevalla는 에이전트를 프로덕션에 배포하고, 모니터링하며, 빠르게 반복할 수 있게 해줍니다.
이 여정—아이디어에서 배포된 서비스까지—은 현대 AI 개발을 보여줍니다. 작게 시작하고, 도구를 탐색하고, 래핑하고, 배포한 뒤, 반복하며, 기능을 추가하고, 실제 서비스와 연결하세요. 곧 여러분은 온라인에 스마트하고 살아있는 에이전트를 갖게 될 것입니다. 이것이 오늘날 AI 물결의 힘입니다.