GPU 비행 — 시스템 아키텍처
Source: Dev.to
위 링크에 포함된 텍스트를 번역하려면 실제 내용이 필요합니다. 번역하고 싶은 본문을 복사해서 제공해 주시면, 요청하신 대로 마크다운 형식과 코드 블록, URL은 그대로 유지하면서 한국어로 번역해 드리겠습니다.
시스템 다이어그램
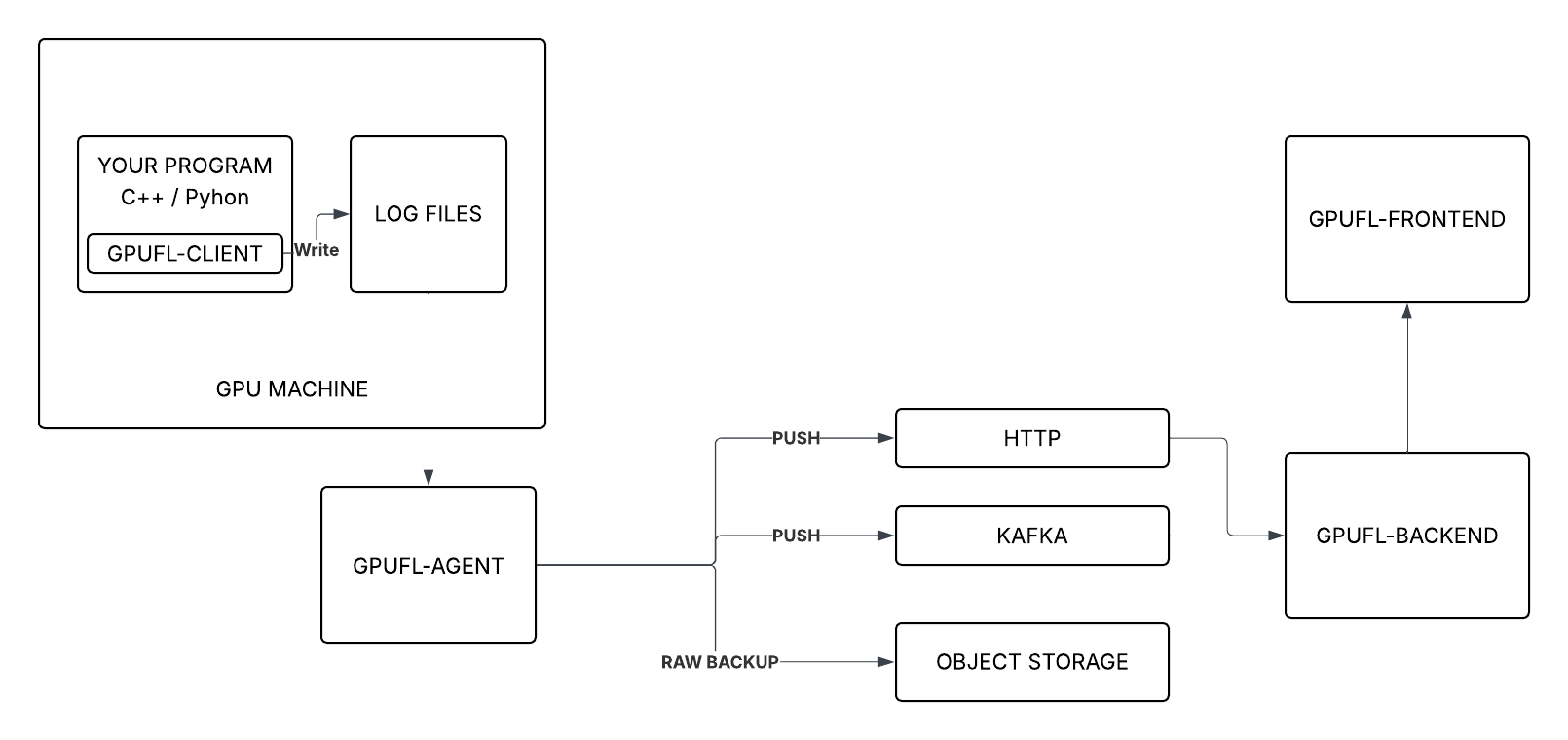
요약
| Component | Role |
|---|---|
| gpufl‑client | GPU 머신에서 실행되며 CUDA 활동에 후크하고 구조화된 로그를 기록합니다. |
| gpufl‑agent | 로그를 감시하고 HTTP 또는 Kafka를 통해 백엔드로 이벤트를 전달합니다. |
| gpufl‑backend | 이벤트를 수신하고 저장하며, 쿼리를 위한 API를 제공합니다. |
| gpufl‑front | 세션을 탐색하고 GPU 동작을 검사하기 위한 React UI입니다. |
클라이언트
C++ 라이브러리(또는 gpufl 파이썬 패키지)로 구현되었습니다.
- 링크 라이브러리를 애플리케이션에 포함합니다.
- 프로그램 시작 시
gpufl::init()를 호출합니다 – GPU Flight가 자동으로 GPU‑관련 이벤트를 수집합니다.
클라이언트가 캡처할 수 있는 항목
- 커널 실행 – 이름, 그리드/블록 차원, 레지스터 수, 공유 메모리, 점유율, 타이밍.
- 메모리 복사 – 방향, 크기, 소요 시간, 처리량.
- SASS 메트릭 – 워프‑레벨 명령어당 카운터 (SassMetrics 엔진이 활성화된 경우).
- PC 샘플 – 워프 스톨‑이유 분포 (PcSampling 엔진이 활성화된 경우).
- 시스템 메트릭 – 주기적인 NVML 스냅샷 (GPU 사용률, VRAM 사용량, 온도, 전력 소모, 팬 속도).
로그 파일
클라이언트는 세 개의 JSONL 파일을 기록합니다(로그 회전은 자동).
.device.log # kernel launches, memory copies, timing
.scope.log # GFL_SCOPE blocks with optional SASS/PC data
.system.log # periodic NVML snapshots에이전트는 파일 오프셋을 추적하므로 회전 시 이벤트가 다시 전송되지 않습니다.
에이전트
에이전트는 별도 프로세스로, 로그 파일을 실시간으로 읽어 백엔드에 이벤트를 전달합니다.
클라이언트와 분리되어 있기 때문에 로그 폴더에 접근할 수 있는 어디서든 실행될 수 있습니다(같은 머신, NFS 공유, 별도 호스트 등).
┌──────────────────────────────┐
│ GPU Machine │
│ │
│ gpufl-client → .log files │
│ │ │
│ gpufl-agent │ ← 가장 간단한 경우: 같은 머신에 에이전트 배치
└────────────────────┼───────────┘
│ (또는 NFS / 공유 볼륨)
▼
gpufl-agent ← 또는: 별도 머신에 에이전트 배치왜 분리했나요?
프로파일링 로직을 분리하면 계측 라이브러리를 유지보수하기 쉬워지고 다양한 환경에서 이식성이 높아집니다. 전송 방식을 변경하더라도(HTTP ↔ Kafka ↔ S3) 클라이언트를 다시 컴파일할 필요가 없습니다.
에이전트 역할
- 세 개의 로그 스트림을 동시에 tail합니다.
- 커서 파일을 통해 파일 위치를 저장하고 재시작 시에도 이어서 읽습니다.
- 로그 회전을 자동으로 따라갑니다.
- HTTP 또는 Kafka를 통해 이벤트를 전송합니다.
- 선택적으로 압축된 원본 로그를 S3 호환 스토리지에 아카이브합니다.
원본
.log파일에는 전체 이벤트 스트림이 그대로 들어 있습니다. 이를 아카이브하면 장기 보관, 감사 가능성, 그리고 업데이트된 분석 로직으로 재처리할 수 있습니다.
설정 예시
# HTTP — 가장 간단하고, 개발이나 소규모 배포에 적합
gpufl-agent \
--folder=/var/log/gpuflight \
--type=http \
--url=http://backend:8080/api/v1/events/# Kafka — 프로덕션 환경 권장
gpufl-agent \
--folder=/var/log/gpuflight \
--type=kafka \
--brokers=kafka:9092# Kafka + S3 아카이브
gpufl-agent \
--folder=/var/log/gpuflight \
--type=kafka \
--brokers=kafka:9092 \
--archiver-endpoint=https://s3.amazonaws.com \
--archiver-bucket=gpu-traces \
--archiver-access-key=KEY \
--archiver-secret-key=SECRETHTTP vs. Kafka
많은 GPU 머신이 동시에 데이터를 전송할 경우, HTTP로 직접 백엔드에 전송하면 생산자 속도가 백엔드 처리 속도에 종속됩니다. 백엔드가 느려지거나 재시작하거나 일시적으로 다운되면 이벤트가 쌓이거나 손실될 수 있습니다.
GPU node 1 ──┐
GPU node 2 ──┼── gpufl-agent ──► Kafka ──► gpufl-backend
GPU node 3 ──┘메시지 큐(Kafka)의 장점:
- 버퍼링 – 백엔드가 재시작하거나 지연될 때 이벤트를 보관합니다.
- 버스트 처리 – GPU 워크로드에서 흔히 발생하는 급격한 이벤트 증가를 흡수합니다.
- 다중 소비자 – 같은 토픽을 다른 서비스(알림, 분석, 아카이브 등)에서도 읽을 수 있습니다.
단일 머신이나 개발 환경에서는 HTTP가 더 간단하고 충분히 적합합니다. 에이전트는 플래그 하나만으로 두 모드 모두 지원합니다.
백엔드
Spring Boot REST 서비스로 구현되며 두 가지 주요 책임을 가집니다:
수집(Ingestion) –
POST /api/v1/events/{eventType}여기서eventType은device,scope,system중 하나입니다.
Kafka 배포 환경에서는 컨슈머 브리지가 토픽에서 읽어 동일한 엔드포인트를 내부적으로 호출합니다.쿼리 API – 다음을 제공합니다:
- 세션 목록
- 시간에 따른 시스템 메트릭
- 세션별 커널 이벤트
- 스코프별 프로파일 샘플
프론트엔드는 이 공개 API만을 사용하며, 숨겨진 내부 인터페이스는 존재하지 않습니다.
이벤트 유형
| 유형 | 내용 |
|---|---|
| device | 커널 실행, 메모리 복사, 정밀 타이밍(CUPTI). |
| scope | GFL_SCOPE 타이밍 블록, 선택적으로 SASS 메트릭 및 PC 샘플이 포함될 수 있음. |
| system | 주기적인 NVML 스냅샷(GPU 사용률 %, VRAM, 온도, 전력 소모, 팬 속도). |
인증
모든 백엔드 엔드포인트는 Bearer 토큰으로 보호됩니다.
프론트엔드
React 애플리케이션으로 다음을 시각화합니다:
- 세션 및 타임라인
- 커널별 성능 상세 정보
- 시스템 수준 메트릭(GPU 사용률, 온도 등)
- 스코프 수준 프로파일링 데이터(SASS 카운터, PC 샘플)
백엔드의 REST API와만 통신하므로 UI가 데이터 수집 파이프라인과 완전히 분리됩니다.
요약
- Client → 구조화된 JSONL 로그를 기록합니다.
- Agent → 로그를 tail하고 이벤트를 전달합니다 (HTTP/Kafka), 필요에 따라 원시 로그를 보관합니다.
- Backend → 이벤트를 수집하고 저장하며, 쿼리 API를 제공합니다 (Bearer 토큰으로 보호).
- Frontend → 공개 API 위에 구축된 React UI입니다.
이 모듈식 설계 덕분에 전송 메커니즘을 교체하고, 수집을 독립적으로 확장하며, 프로파일링 로직을 가볍고 이식 가능하게 유지할 수 있습니다.
GPU Flight 개요
- Ingestion – 에이전트에서 직접 HTTP 수집; 프런트엔드 또는 외부 도구에서 프로그래밍 방식 접근을 위한 API 키.
- Data retention – 구성 가능한 정리 정책으로 디스크 사용량을 제한. 설정된 보존 기간을 초과하면 오래된 세션이 자동으로 정리됩니다.
- Frontend – 다크 테마를 적용한 React + TypeScript 단일 페이지 애플리케이션(SPA)으로, 백엔드 REST API와 연결됩니다.
메인 대시보드
메인 뷰는 단일 프로파일링 세션에 대해 세 개의 탭으로 구성된 대시보드입니다:
┌────────────────────────────────────────────────────┐
│ Session: my_training_run [host: gpu-node-01] │
├──────────────┬─────────────┬───────────────────────┤
│ Kernels │ Scopes │ System │
└──────────────┴─────────────┴───────────────────────┘Kernels 탭
- 커널 실행 타임라인.
- 커널을 클릭하면 Inspector가 열리며, 다음 정보를 표시합니다:
- 점유율, 레지스터 수, 공유 메모리, 그리드 및 블록 차원.
- 실행을 트리거한 CPU 호출 스택.
Scopes 탭
GFL_SCOPE블록의 계층적 트리와 시간 분해표시.- SASS Metrics 엔진을 사용하는 세션의 경우, 각 스코프에 이전 포스트와 비교한 발산 데이터도 표시됩니다.
System 탭
- 다음 항목에 대한 시계열 차트:
- GPU 사용률 %
- VRAM 사용량
- 온도
- 전력 소비
- 팬 속도
세션 선택기
선택기를 사용하면 호스트와 애플리케이션 이름별로 탐색할 수 있어, 머신 간 또는 시간 경과에 따른 실행 비교가 용이합니다.
다음 게시물: 로컬 설정 가이드
Docker Compose 파일이 제공되어 전체 스택—클라이언트 예제, 에이전트, 백엔드, 프론트엔드—을 단일 머신에서 실행합니다. 이를 통해 수동 설정 없이 GPU Flight를 체험할 수 있습니다.
앞으로 무엇이 올까요?
- 클라우드 데모 – 실시간 배포가 진행 중입니다. 이용 가능해지면 링크가 게시되어 직접 설정 없이 UI에서 실제 GPU 프로파일링 데이터를 탐색할 수 있습니다.
오픈‑소스
GPU Flight는 오픈 소스입니다.