KEDA와 함께하는 쿠버네티스 GPU 자동 스케일링: 외부 스케일러 구축
Source: CNCF Blog
문제
KEDA는 CGO_ENABLED=0 상태로 빌드됩니다. GPU 메트릭을 읽는 표준 방법인 NVIDIA Management Library(NVML)는 CGO가 필요하므로, Prometheus나 Kafka 스케일러를 추가하듯이 KEDA 코어에 GPU 스케일러를 바로 넣을 수 없습니다.
두 번째 문제는 KEDA의 오퍼레이터가 단일 배포(Deployment)로 실행된다는 점입니다. NVML 호출은 로컬에서 이루어지며—같은 노드에 있는 GPU의 메트릭을 읽습니다. 따라서 노드 B에서 실행 중인 파드가 노드 A의 GPU 0을 조회할 수 없습니다.
즉, 기존 KEDA 스케일러를 그대로 사용할 수 없었습니다. 우리는 모든 GPU 노드에서 실행되고 네트워크를 통해 메트릭을 제공하는 무언가가 필요했습니다.
아키텍처
이를 해결하기 위해 DaemonSet(참고 구현: keda-gpu-scaler)을 커스텀으로 구축합니다. 이 아키텍처에서 각 파드는:
go-nvml을 사용해 NVML을 호출하고 로컬 GPU 메트릭을 읽습니다.- KEDA의
ExternalScaler인터페이스를 이용해 gRPC로 메트릭을 제공합니다. - KEDA 오퍼레이터가 스케일러에 연결해 HPA 결정을 내립니다.
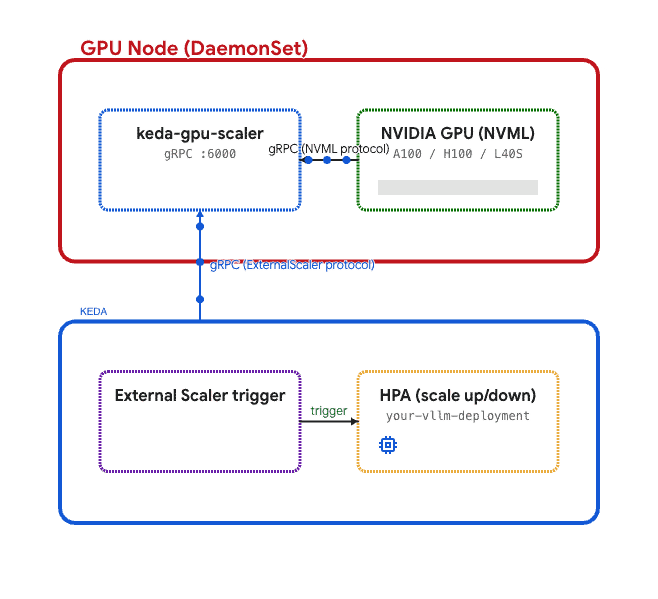
이는 Kubernetes가 디바이스 플러그인 및 메트릭 서버에 대해 사용하는 패턴과 동일합니다—노드당 하나의 에이전트가 로컬 하드웨어 데이터를 수집합니다.
스케일링 가능한 항목
스케일러는 GPU당 다음 메트릭을 노출합니다:
| 메트릭 | 설명 |
|---|---|
gpu_utilization | SM(컴퓨팅) 사용률(%) |
memory_utilization | 메모리 컨트롤러 사용률 |
memory_used_percent | VRAM 사용량(%) |
temperature | GPU 다이 온도(°C) |
power_draw | 현재 전력 소비량(W) |
멀티 GPU 노드에서는 max, min, avg, sum 중 하나를 선택해 집계할 수 있으며, 특정 GPU 인덱스를 대상으로 할 수도 있습니다.
미리 만든 프로파일
대부분의 사용자는 몇 가지 흔한 GPU 워크로드 유형 중 하나를 사용하므로, 스케일러에는 합리적인 기본값을 가진 프로파일이 포함되어 있습니다:
triggers:
- type: external
metadata:
scalerAddress: "keda-gpu-scaler.gpu-scaler.svc.cluster.local:6000"
profile: "vllm-inference"| 프로파일 | 메트릭 | 목표 | 활성화 임계값 | 사용 사례 |
|---|---|---|---|---|
vllm-inference | memory_used_percent | 80% | 5% | LLM 서빙, scale‑to‑zero |
triton-inference | gpu_utilization | 75% | 10% | Triton 모델 서빙 |
training | gpu_utilization | 90% | 0% | 학습 작업, scale‑to‑zero 없음 |
batch | memory_used_percent | 70% | 1% | 배치 추론, 적극적인 scale‑down |
값을 직접 오버라이드하거나, 프로파일을 완전히 생략하고 metricType, targetValue, activationThreshold 를 직접 지정할 수도 있습니다.
빠른 시작
Helm으로 설치
helm install gpu-scaler deploy/helm/keda-gpu-scaler \
--namespace gpu-scaler --create-namespace이 차트는 nvidia.com/gpu.present=true 라벨이 붙은 노드에 DaemonSet을 배포하고, nvidia.com/gpu 테인트를 허용합니다. 기본적으로 NVIDIA 컨테이너 런타임을 사용합니다—클러스터에 해당 런타임이 없을 경우 nvmlHostMounts.enabled=true 로 설정해 디바이스 파일을 직접 마운트하면 됩니다.
ScaledObject 생성
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: vllm-gpu-scaler
spec:
scaleTargetRef:
name: vllm-deployment
minReplicaCount: 0
maxReplicaCount: 8
triggers:
- type: external
metadata:
scalerAddress: "keda-gpu-scaler.gpu-scaler.svc.cluster.local:6000"
profile: "vllm-inference"이렇게 하면 끝입니다. 이제 KEDA는 GPU 메모리 사용량을 기준으로 vLLM 배포를 자동으로 스케일링하며, 유휴 시에는 scale‑to‑zero도 수행합니다.
GPU 없이 테스트하기
스케일러에는 mock collector 모드가 포함되어 있어 테스트가 가능합니다. e2e 테스트 스위트는 가짜 GPU 데이터를 제공하는 실제 gRPC 서버를 띄우고 IsActive → GetMetricSpec → GetMetrics 흐름 전체를 검증합니다(프로파일, 오류 경로, 스트리밍, 집계 모드 등을 다루는 11개의 테스트). 모든 테스트는 GPU 하드웨어 없이 CI에서 실행됩니다.
go test -v -tags=e2e -race ./tests/e2e/앞으로의 계획
커스텀 외부 스케일러를 구축하는 것은 CNCF 생태계를 확장하는 강력한 방법입니다. 이는 KEDA와 같은 졸업 프로젝트가 유연성을 유지하면서, 엔지니어가 최신 AI 인프라 패턴에 맞는 커스텀 DaemonSet을 만들 수 있게 해 줍니다. 모든 워크로드를 동일한 추상화에 억지로 끼워 넣을 필요가 없습니다.
위에서 공유한 코드 스니펫과 레포지토리는 이 아키텍처에 대한 오픈소스 레퍼런스 구현입니다. Kubernetes에서 GPU 워크로드를 운영하고 GPU 메트릭을 네이티브하게 이해하는 자동 스케일링이 필요하다면, KEDA의 ExternalScaler 인터페이스를 살펴보는 것이 좋은 출발점이 될 것입니다.
GitHub: keda-gpu-scaler