Gemma 4 QAT 모델: 모바일·노트북 효율을 위한 압축 최적화
두 달 전 Gemma 4를 출시한 이후, 우리는 지속적으로 기능을 확장해 왔습니다. 먼저, 추론 속도를 높이기 위해 멀티‑토큰 예측 (MTP)을 도입했으며, 며칠 전에는 12B 모델을 공개해 E4B와 26B MOE 모델 사이의 격차를 메웠습니다.
오늘은 Quantization‑Aware Training (QAT) 으로 최적화된 새로운 체크포인트를 공개합니다. 이를 통해 Gemma 4를 일상적인 엣지 디바이스와 일반 소비자 GPU에서도 더욱 효율적으로 실행할 수 있습니다.
훈련 중에 양자화를 시뮬레이션함으로써 QAT는 모델이 압축될 때 발생하는 품질 손실을 최소화합니다. 이번 릴리스에는 널리 사용되는 Q4_0 양자화 포맷용 QAT 체크포인트와, 모바일 사용 사례에 특화된 새로운 양자화 포맷이 포함됩니다. 이 모바일 포맷을 사용하면 Gemma 4 E2B의 메모리 사용량을 1 GB로 줄일 수 있습니다. 이처럼 메모리 요구량을 크게 낮추면서도 Gemma 4가 제공하는 기능과 품질을 그대로 유지합니다.
모델 품질을 유지하면서 크기를 줄이는 방법
양자화는 메모리 사용량을 감소시키고 디코드 속도를 가속화함으로써 소비자 하드웨어에서 모델을 실행할 수 있게 하는 핵심 기술입니다. 하지만 기존의 사후 양자화(Post‑Training Quantization, PTQ)는 성능 저하를 초래하는 경우가 많습니다. 훈련 후에 모델을 단순히 양자화하는 대신, QAT는 양자화 과정을 훈련 단계에 직접 통합합니다. PTQ도 품질을 어느 정도 유지하지만, 우리의 QAT 결과는 표준 PTQ 베이스라인보다 전반적인 품질이 더 높습니다.
우리는 모든 모델에 대해 최상의 성능을 끌어내기 위해 Q4_0 포맷에 이 QAT 레시피를 적용했습니다. 엣지 모델(E2B와 E4B)에서는 모바일 전용 양자화 스키마를 도입해 양자화 접근 방식을 재구상했습니다.
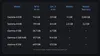
VRAM 및 저장 용량 절감
아래 표는 모델을 로드하는 데 필요한 대략적인 VRAM 용량을 보여줍니다.
모바일 디바이스에 최적화된 내부 설계
표준 압축 포맷은 모바일 프로세서에서 효율적으로 실행되기 어려운 경우가 많습니다. Gemma 4가 모바일에서도 원활히 동작하도록, 우리는 엣지 하드웨어에 맞춘 맞춤형 모바일 양자화 스키마를 설계했습니다.
- 정적 활성화값: 일반적으로 모델은 실행 시마다 데이터를 어떻게 스케일링할지 계산하는 데 연산을 낭비합니다. 우리는 훈련 단계에서 이러한 설정을 미리 계산해 모바일 칩의 작업량을 줄이고 응답 속도를 높였습니다.
- 채널별 양자화: 압축된 데이터를 모바일 가속기의 설계에 맞게 구조화했습니다. 이를 통해 휴대폰이 느린 우회 방법 없이 네이티브 연산을 수행할 수 있습니다.
- 목표 2‑bit 양자화: 토큰을 생성하는 특정 부분을 2‑bit까지 강하게 압축하고, 핵심 추론 레이어는 높은 정밀도를 유지했습니다. 이렇게 하면 저장 용량을 절감하면서도 모델의 지능은 유지됩니다.
- 임베딩 및 KV 캐시 최적화: 모델의 어휘 목록과 단기 메모리(키‑밸류 캐시)에 압축을 집중했습니다. 이로써 활성 메모리 사용량이 크게 감소해, 긴 대화를 나누어도 메모리 부족 현상이 발생하지 않습니다.
우리의 오디오·비전 인코더는 많은 사용 사례에서 필요하지 않으므로, 필요한 모달리티만 배포하면 메모리 사용량을 더욱 줄일 수 있습니다. 예를 들어, Per‑Layer Embedding이 제외된 Gemma 4 E2B 텍스트 전용 모델은 1 GB 미만의 메모리만 필요합니다.
오늘 바로 시작해 보세요
이 모델들을 여러분이 선호하는 워크플로우에서 손쉽게 사용할 수 있도록, 우리는 다양한 개발자 도구와 파트너십을 맺어 Gemma 4 QAT 체크포인트를 바로 지원합니다.
- 가중치 다운로드: 지금 바로 Hugging Face에서 Q4_0 및 mobile 모델 가중치를 받아보세요. 워크플로우에 맞게 포맷을 제공했습니다. GGUF 포맷은
llama.cpp와 바로 호환되며, 압축 텐서는vLLM용으로 제공됩니다. 그 외의 경우, 비양자화 체크포인트를 제공하니 원하는 포맷으로 변환·양자화할 수 있습니다. - 통합 및 학습: QAT 체크포인트를 최적 배포하는 방법은 문서를 참고하세요.
- 데스크톱에서 체험: 사용자 친화적인 인터페이스인 llama.cpp, Ollama, LM Studio 등을 통해 Gemma 4 QAT 모델을 로컬 데스크톱에서 손쉽게 다운로드·관리·실행할 수 있습니다.
- 디바이스에 배포: Google의 경량 런타임인 LiteRT‑LM을 사용해 엣지에 최적화된 배포를 하거나, Transformers.js로 웹에서도 직접 실행할 수 있습니다.
- 선호하는 개발 도구 활용: 대형 모델은 vLLM으로 효율적으로 서빙하고, Apple Silicon에서는 MLX로 최적화하세요. MTP QAT 체크포인트를 사용하면 MTP의 속도 향상을 유지하면서 모델을 양자화할 수 있습니다. 또한 Hugging Face Transformers와 Unsloth을 이용해 가중치를 직접 파인튜닝할 수 있습니다.
Gemma 4를 로컬에서 실행하며 여러분이 어떤 작품을 만들어낼지 기대됩니다!