LLM을 1995년식 문서처럼 쓰도록 파인튜닝
Source: Hacker News
Posted on Jun 1, 2026
· 10 min read
80~90년대 소프트웨어 기술 작가처럼 쓰도록 인스트럭트 모델을 파인튜닝한 실험
연구를 위해 옛날 기술 문서 전설을 소환하기
90년대 기술 작가처럼 글을 쓰는 개인 로컬 모델을 훈련시키려면 방대한 양의 텍스트가 필요합니다. 예를 들어, 저 자신처럼 쓰도록 파인튜닝하고 싶다면 이 블로그는 10만 단어 정도에 불과해 충분하지 않죠. 충분히 훈련시키려면 더 많은 샘플이 필요하고, 그런 자료는 구하기도 만들기도 쉽지 않습니다. 가장 빠른 방법은 기존 코퍼스를 활용하는 것입니다. 어디서 구할 수 있을까요?
Bitsavers를 만나보세요. 오래된 컴퓨터 매뉴얼과 브로셔를 수집·스캔해 놓은 사이트로, 컴퓨터 역사와 고전 기술 문서의 귀중한 저장소이며 전 세계에 미러가 존재합니다. 저는 90년대 마이크로소프트 매뉴얼을 좋아해서 Microsoft 컬렉션을 훈련 자료로 선택했습니다. 이 컬렉션은 1977년부터 2005년 사이에 출판된, 3,700만 단어가 넘는 문서를 포함하고 있습니다.
OCR 처리된 텍스트 파일을 다운로드한 뒤, 파이썬 스크립트로 인덱스·프런트머터 등 잡다한 잡음을 정리했습니다. 그 다음, OpenRouter의 저렴하고 빠른 모델 gemma-4-26b를 이용해 각 문단을 “keep”(보관) 혹은 “drop”(제거)으로 분류했습니다. 이 2차 정리 비용은 약 8달러였으며, 두 번의 정리 과정을 거쳤음에도 불구하고 나중에 발견한 잡음이 약간 남아 있었지만 테스트에는 크게 문제되지 않았습니다.
정제된 텍스트를 문단·섹션 경계, 헤딩을 기준으로 나누고 코드 블록은 그대로 유지하면서, Claude의 권고에 따라 각 청크를 약 512 토큰 이하로 제한했습니다. 각 청크마다 템플릿에서 추출한 합성 명령어를 붙여 JSONL 형식(한 줄에 하나의 JSON 객체)으로 192,456개의 예시를 만들었습니다. 더 나은 명령어나 질문을 생성하기 위해 작은 모델을 사용할 수도 있었지만, 저는 급한 성격이라 바로 진행했습니다.
💡 자료에 대한 주의사항: 이 프로젝트는 독립적인 비상업적 연구이며 마이크로소프트와는 어떠한 연관·후원·승인도 없습니다. 저는 개인 스타일 전이 실험을 위해서만 이 절판 매뉴얼을 사용했으며, 코퍼스·훈련 데이터·어댑터는 배포되지 않고 파인튜닝된 모델은 제 컴퓨터에만 국한됩니다.
처음부터 훈련하는 대신 파인튜닝을 선택한 이유
이상적인 상황이라면 수백만 달러를 투자해 제 고유 LLM, Fabrice를 만들 수 있겠지만, 저는 부유하지 않으니(이 글을 쓰고 있기도 하고) 파인튜닝이 현실적인 대안이었습니다. 파인튜닝은 모델의 “가중치”를 약간만 조정해 훈련 자료에 따라 토큰이 생성되도록 만드는 작업으로, 거대한 빙산을 작은 선박으로 살짝 방향을 틀어 주는 느낌이라고 비유합니다.
왜 파인튜닝이고 RAG(검색 기반 생성)가 아니냐고요? 이번 실험에서는 사실을 찾아내는 것이 아니라, LLM이 특정 스타일로 행동하고 글을 쓰게 하는 것이 목표였기 때문입니다. 전체 훈련에 비해 파인튜닝은 데이터 양이 적어도 되므로 비용이 훨씬 저렴합니다. 그리고 개인적으로 파인튜닝을 직접 해보고 얼마나 실현 가능한지 확인하고 싶었습니다.
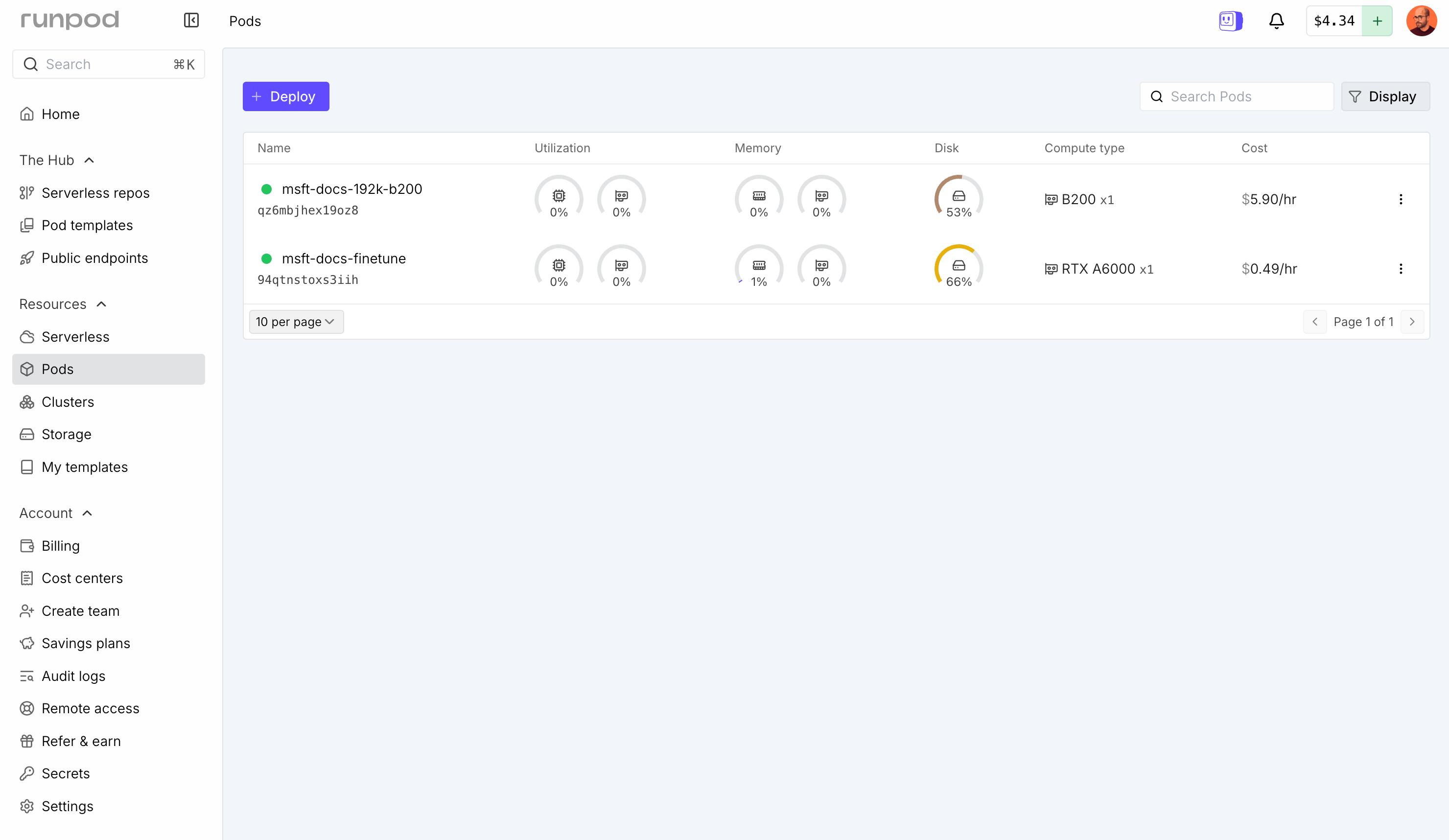
오래된 그래픽 카드를 탑재한 제 컴퓨터에서 며칠·몇 주를 들이지 않으려, 저는 AI 개발자를 위한 온디맨드 GPU 팟을 제공하는 온라인 서비스 Runpod을 이용했습니다. 예를 들어 시간당 6달러 미만으로 Nvidia B200(192GB 메모리) 같은 강력한 GPU를 임대할 수 있으며, 자동 충전·비용 제어 기능도 갖추고 있습니다.
신비한 버즈워드가 난무하는 세계에 뛰어들다
파인튜닝 방식을 결정한 뒤, 저는 Claude와 가장 합리적인 방법을 상의했습니다. 그 결과 QLoRA(Quantized Low-Rank Adaptation)를 선택했는데, 이는 LLM의 모든 가중치를 바꾸는 대신 “동결”하고 그 위에 어댑터(작은 파일)를 얹어 모델 행동을 재구성하는 방식입니다. QLoRA의 Q는 결과가 양자화(압축)되어 메모리 요구량이 감소한다는 뜻입니다.
이해가 안 가시나요? 당연히 어렵습니다. 😅
집에서 LLM을 다루는 일은 언제나 타협의 연속입니다. 시간·비용·목표 사이에서 균형을 잡아야 하죠. 저는 주말 안에 의미 있는 결과를 얻고자 두 모델, Llama 3.1 8B Instruct와 Qwen 2.5 7B Instruct에 파인튜닝을 시도했습니다. 8B 규모라면 MacBook Air에서도 무리 없이 구동됩니다. 또한 질문 응답용이 아닌 Llama base 모델도 테스트했습니다.
훈련 조건은 다음과 같이 다양하게 변형했습니다.
| 실행 | 베이스 모델 | 데이터 양 | 에폭 수 | 랭크 |
|---|---|---|---|---|
| Llama instruct-40k | Llama 3.1 8B Instruct | 40k | 1 | 16 |
| Llama base-40k | Llama 3.1 8B (base) | 40k | 1 | 16 |
| Qwen-40k | Qwen 2.5 7B Instruct | 40k | 3 | 16 |
| Qwen-192k | Qwen 2.5 7B Instruct | 192k | 1 | 16 |
| Qwen-r8 | Qwen 2.5 7B Instruct | 40k | 1 | 8 |
| Qwen-r16 | Qwen 2.5 7B Instruct | 40k | 1 | 16 |
어댑터는 파인튜닝한 대상 모델에만 적용할 수 있습니다. 각 어댑터를 훈련한 뒤 노트북으로 내보내 GGUF LoRA 파일로 변환·양자화하고, 로컬 Ollama 모델로 등록해 벤치마크에 활용했습니다. 로컬 변환 방식은 GPU 없이도 빠르게 진행할 수 있지만, 완전 병합된 모델에 비해 추론 속도가 다소 느립니다. 이번 테스트에서는 속도가 큰 문제가 아니었습니다.
모든 조건에 대한 어댑터 훈련은 휴식 시간을 포함해 약 하루가 걸렸고, 총 비용은 50달러 정도였습니다. 진행 중 두 개의 어댑터는 사라졌는데, Runpod은 예산이 0이 되면 팟을 즉시 삭제하기 때문에(교훈을 얻었습니다) 조심해야 합니다. Claude는 각 실행을 설정하고 Runpod API와 연동하는 작업을 자동으로 처리해 주었으며, Claude Code의 /goal 명령을 활용해 반복 실행을 손쉽게 관리했습니다.