Kubernetes 클러스터에서 MCP 툴 호출을 퇴거시키기
Source: Dev.to
Overview
Model Context Protocol (MCP)은 한동안 스스로 발을 헛디뎠(https://www.anthropic.com/engineering/code-execution-with-mcp)으며, 이는 에이전트 분야에 종사하는 우리 many가 느꼈지만 정량화되지 않았던 좌절감을 잘 표현합니다:
LLM은 뛰어난 코드 생성기이지만, 상태 머신은 형편없다.
에이전트의 산업 표준은 ReAct 패턴 (Reason + Act)이며, 이는 본질적으로 LLM을 의사‑런타임(pseudo‑runtime)으로 전환합니다. 모델은 도구를 선택하고, API를 호출하고, 네트워크 응답을 기다리고, JSON 결과를 파싱하고, 이를 반복합니다. 오늘날의 LLM으로는 이 접근 방식이 효율적이지 않습니다. 확률적 엔진에 결정론적 제어 흐름을 맡기면 환각이 발생하고, 컨텍스트 창이 급속히 오염되며, 상태 관리가 깨지기 쉽습니다.
저는 Kubernetes 진단을 위해 Code Mode 패턴을 구현해 보았습니다. LLM이 순차적으로 조정하도록 원자적 도구(list, get, log 등)를 노출하는 대신, 런타임이 포함된 샌드박스를 제공했습니다. LLM은 프로그램을 작성하고, 에이전트가 이를 실행합니다. 결과는 단순히 “더 좋다”는 수준을 넘어, 에이전트가 인프라와 상호 작용하는 방식에 대한 근본적인 변화를 의미합니다.
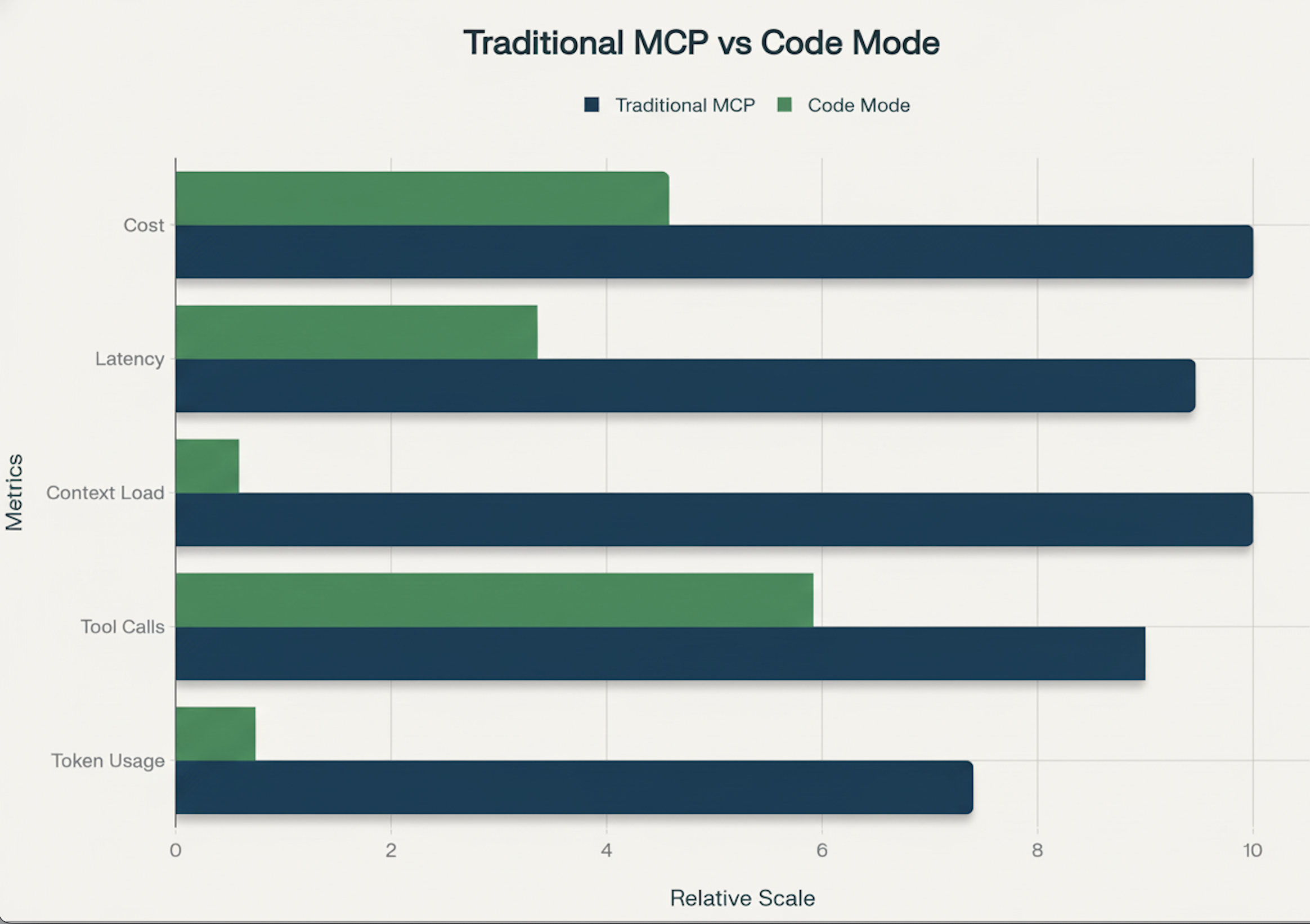
실제 디버깅 세션에서는 전통적인 작업 흐름(로그에서 실패한 pod의 문제를 정확히 찾아내는)이 810번의 도구 호출에 걸쳐 1 백만 토큰에 달할 수 있습니다. 동일한 조사를 Code Mode로 수행하면 **100200 k 토큰** 수준으로 감소하며, ~2–10배 감소하고, 컨텍스트가 무거운 작업에서는 90 % 이상 토큰을 절감할 수 있습니다.
The Economics of Context
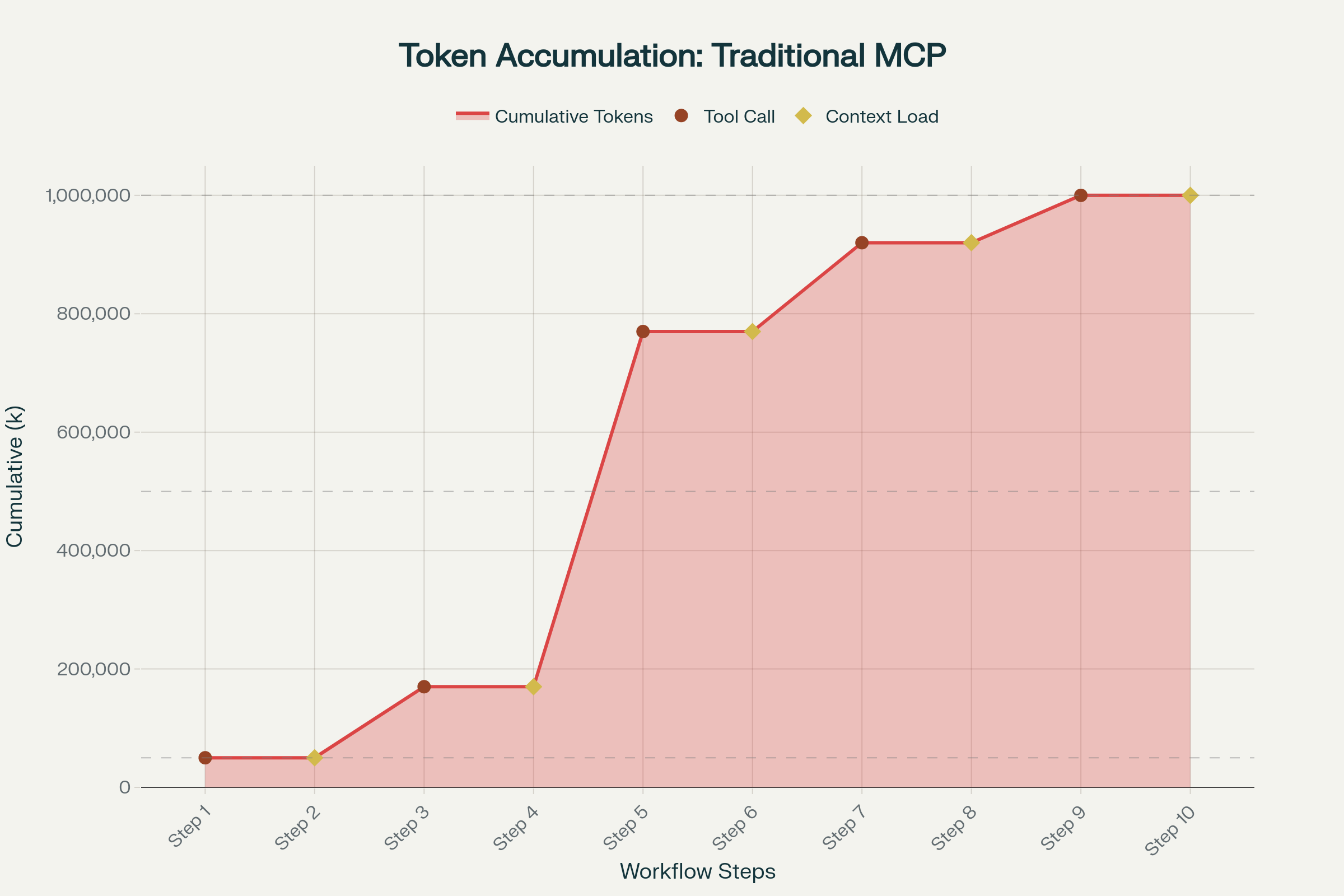
프로덕션 Kubernetes 워크플로(로그가 큰 경우)에서는 “pod가 왜 고장 났는가”라는 표준 흐름이 8~10번의 라운드에서 1 M+ 토큰을 소비합니다. 각 도구 호출은 중간 JSON을 컨텍스트에 추가해 환각 가능 영역을 넓힙니다.
전통적인 MCP 도구‑호출 체인은 프롬프트 캐싱에 비효율적입니다. 각 상호 작용이 대화 컨텍스트를 근본적으로 바꾸기 때문입니다(Claude 프롬프트 캐싱 문서).
Code Mode로 전환하면 모델은 프롬프트를 받고 하나의 코드 블록을 작성한 뒤 최종 정제된 답변을 받습니다. 불필요한 도구 호출이 사라져 토큰 사용량, 지연 시간, 환각 비율이 크게 감소합니다. 최근 Anthropic 벤치마크에서는 워크플로가 150 k 토큰에서 ~2 k 토큰으로 감소했으며(98 % 컨텍스트 절감) 우리 자체 Kubernetes 시나리오에서도 90 % 수준의 절감이 확인되었습니다.
- 전통적인 도구 사용: ~1 M 토큰 / 8‑10+ 라운드 트립.
- Code Mode: ~100‑200 k 토큰 / 4‑6+ 라운드 트립.
Why It Works
Code Mode는 아키텍처를 학습 데이터와 일치시킵니다. 최첨단 LLM은 유효한 실행 가능한 코드에 대해 대량 사전 학습되어 있어 제어 흐름, 오류 처리, 데이터 필터링을 암묵적으로 이해합니다.
반면, 인터랙티브 도구‑호출 패러다임은 LLM에게 다음을 강요합니다:
- 무상태 HTTP 요청 사이에서 루프 상태 관리.
- 이전 호출에서 발생한 잡음을 무시하면서 장황한 JSON 파싱.
실행 로직을 결정론적 샌드박스로 옮기면 루핑, 필터링, 조건부 대기와 같은 엄격한 논리를 전용 런타임에 위임하게 됩니다. LLM은 사실상 다음과 같은 스크립트를 작성합니다:
“모든 pod를 순회하고, pod가 5번 이상 재시작하면 로그를 가져와 ‘Error’를 grep하고 결과를 반환한다.”
샌드박스는 이 루프를 밀리초 안에 실행합니다. LLM은 500개의 정상 pod 리스트를 직접 보지 않으며, 최종 원인만을 확인합니다. 중간 결과는 샌드박스에서 처리되어 컨텍스트 창을 오염시키지 않으며, 이는 Anthropic이 지적한 에이전트 성능 저하의 일반적인 원인입니다.
Anthropic 내부 테스트에 따르면 Code Mode는 정확도도 크게 향상시킵니다. 이는 모델이 JSON으로 코드를 반환하도록 강요받을 때 겪는 어려움을 보여주는 연구와 일치합니다. 예를 들어 Aider 벤치마크는 모델이 JSON 형식 유효성을 동시에 보장해야 할 때 코드 품질이 낮아진다고 보고했습니다.
High‑Order Kubernetes Diagnostics
이 전환은 컨텍스트 제한 때문에 비용이 많이 들거나 기술적으로 불가능했던 워크플로를 가능하게 합니다.
1. “Cluster health scan” 시나리오
구식 방식: 에이전트가 모든 pod를 나열하고, 여러 도구 호출을 통해 각각을 설명하면서 금세 레이트 혹은 컨텍스트 제한에 부딪힌다.
새 방식: 에이전트가 루프를 작성한다.
// Execution inside the sandbox
const pods = tools.kubernetes.list({ namespace: 'default' });
const problems = pods
.filter(p => p.status === 'CrashLoopBackOff')
.map(p => {
const logs = tools.kubernetes.logs({ name: p.metadata.name });
return analyze(logs);
});
return problems;전체 스캔이 메인 LLM 채팅 체인 밖에서 수행된다.
2. Configuration Drift & Audits
에이전트는 Helm 릴리스 매니페스트(tools.helm.get)와 실시간 Kubernetes 객체(tools.kubernetes.get)를 가져와 샌드박스 내 메모리에서 차이를 비교하고 오직 드리프트만 반환할 수 있다. 표준 도구 호출 방식이라면 두 개의 거대한 YAML 파일을 컨텍스트 창에 붙여넣어야 한다.
3. Event‑Driven Debugging
샌드박스가 진정한 런타임을 제공하므로, 에이전트는 폴링 로직을 작성할 수 있다. 배포 상태를 확인하고 5초 대기한 뒤 다시 확인해도 “대기” 상태에 대해 토큰을 하나도 소모하지 않는다. 이는 채팅 기반 에이전트의 끊긴 단계와 비교해 마법 같은 원자적 “Rollout and Verify” 작업을 가능하게 한다.
4. PII Data Fetching
Code Mode와 MCP를 사용하면 Kubernetes 환경에서 중요한 보안 이점을 제공한다: 민감한 데이터가 LLM의 컨텍스트 창에 절대 노출되지 않는다. 전통적인 도구 호출에서는 에이전트가 API 자격 증명, 데이터베이스 비밀번호, 서비스 계정 토큰 등을 Kubernetes Secrets에서 가져올 때 해당 값이 클라우드 모델 제공자의 네트워크로 흐른다. Code Mode에서는 샌드박스가 비밀을 내부적으로 처리하고, 정제된 결과만 LLM에 반환한다.