평가: 배포하기 전에 증명하라
I’m happy to translate the article for you, but I’ll need the full text you’d like translated. Could you please paste the content (excluding the source line you already provided) here? Once I have the text, I’ll translate it into Korean while preserving the original formatting, markdown, and any code blocks or URLs.
모니터링 vs. 평가
“모니터링은 무슨 일이 일어나고 있는지를 알려주고 — 평가는 그것이 얼마나 좋은지를 알려준다.”
즉시 응답하고, 절대 충돌하지 않으며, 모든 질문에 절대적인 자신감으로 답변하는 에이전트를 만들 수 있습니다. 하지만 정확성 없이 자신감만 있다면 잘 차려입은 실수에 불과합니다.
그래서 Oracle AI Agent Studio는 두 가지 상보적인 기능을 제공합니다: 모니터링과 평가. 이 글에서는 평가에 초점을 맞추어—그것이 무엇인지, 어떻게 설정하는지, 그리고 에이전트를 실제 운영 환경에 투입하기 전에 왜 신경 써야 하는지를 설명합니다.
모니터링에 궁금하신가요? 이 post를 확인해 보세요.
평가가 중요한 이유
평가는 에이전트가 정의된 기준과 비즈니스 목표를 세 가지 차원에서 충족할 수 있는지 확인합니다:
- 정확도
- 지연 시간
- 토큰 사용량
이를 하지 않으면, 감에 의존해 배포하는 것과 같습니다.
적절한 평가 프레임워크를 통해 에이전트가 다음을 만족하는지 검증할 수 있습니다:
- 올바르게 답변한다
- 허용 가능한 시간 내에 응답한다
- 클라우드 비용 예산보다 토큰 예산을 더 빨리 소진하지 않는다
이를 AI 에이전트를 위한 테스트 스위트라고 생각하면 됩니다.
Source: …
측정 항목: 무엇을 측정할 것인가
Oracle AI Agent Studio는 풍부한 측정 항목 세트를 제공합니다. 평가에 해당하는 항목과 모니터링에 해당하는 항목을 구분하는 것이 중요한데, 두 용도는 서로 다르기 때문입니다.
| 지표 | 평가 | 모니터링 |
|---|---|---|
| Error Rate | ✅ | ✅ |
| Error Count | ✅ | ✅ |
| Session Count | ✅ | ✅ |
| P99 Latency | ✅ | ✅ |
| P50 Latency | ✅ | ✅ |
| Total Tokens | ✅ | ✅ |
| Input Token Count | ❌ | ✅ |
| Output Token Count | ✅ | ✅ |
| Median Correctness | ✅ | ❌ |
| Groundedness | ✅ | ❌ |
| Answer Relevance | ✅ | ❌ |
| Context Relevance | ✅ | ❌ |
품질 측정 항목인 Correctness, Groundedness, Answer Relevance, Context Relevance는 평가에만 해당합니다. 이는 에이전트가 단순히 기술적으로 작동하는 것이 아니라 실제로 유용한지를 판단해 줍니다.
간단 정의
- Median Correctness – 에이전트의 답변이 기대되는 기준 답변과 얼마나 일치하는지(0 → 1) 나타냅니다. 시험에서 에이전트가 받는 점수라고 생각하면 됩니다.
- Groundedness – 생성된 답변이 실제 검색된 원본 콘텐츠에 기반하고 있는지 여부를 나타냅니다. 근거가 있는 응답은 지식 베이스에 충실하며 환상을 만들지 않습니다.
- Answer Relevance – 응답이 사용자의 질문을 얼마나 직접적이고 정확하게 다루는지 평가합니다. 잘못된 질문에 대한 정답은 점수가 매겨지지 않습니다.
- Context Relevance – 검색된 정보 자체의 품질을 의미합니다. 에이전트가 가져온 컨텍스트가 적절하고 신뢰할 수 있어야 좋은 답변을 만들 수 있습니다.
평가 설정: 단계별 가이드
단계 1 — 평가 세트 정의하기
이를 테스트 계획이라고 생각하면 됩니다. 포함 내용:
- 테스트 질문 – 에이전트가 처리해야 할 입력
- 예상 응답 – 측정 기준이 되는 정답 답변
- 성공 기준 – 각 메트릭이 충족해야 할 임계값
예상 응답이 없는 평가 세트는 단순 데모에 불과합니다. 예상 응답이 있어야 실행 결과가 의미 있는 품질 게이트가 됩니다.
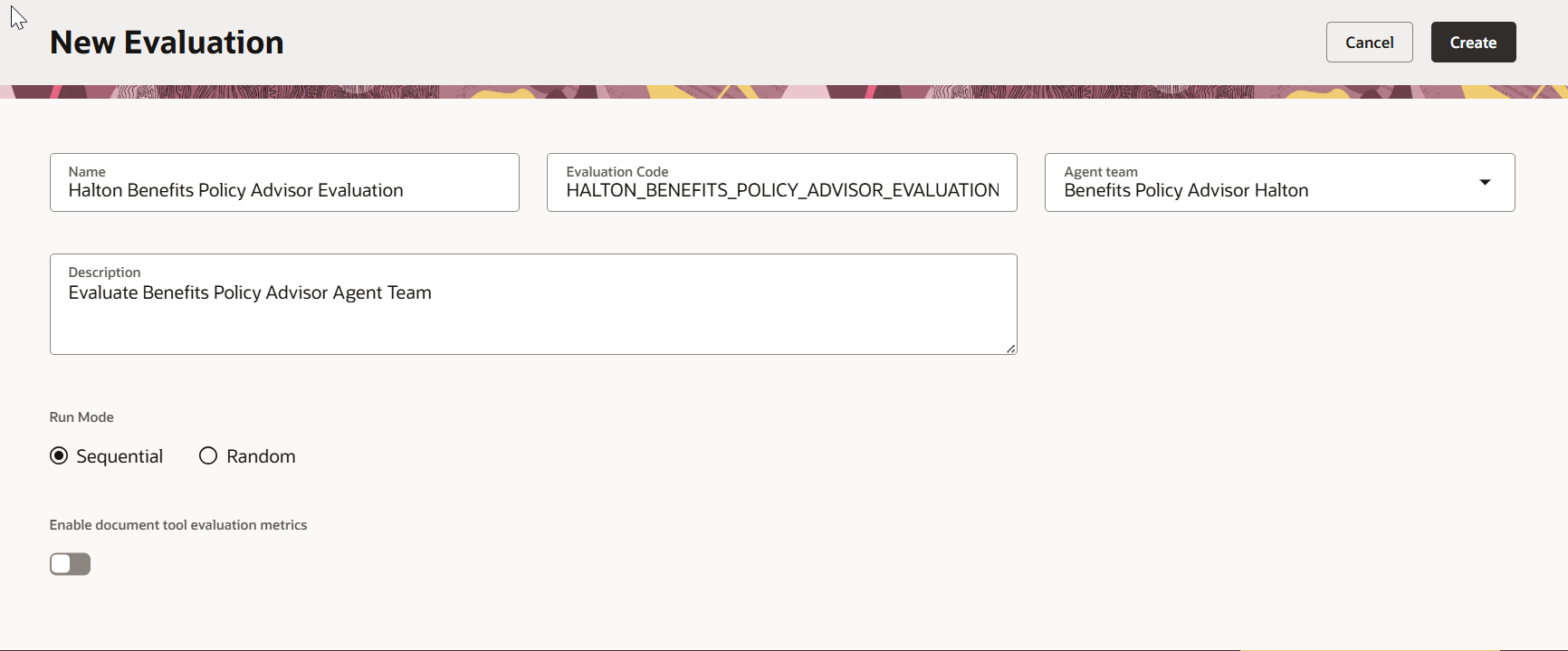
단계 2 — 실행 모드 선택하기
| 모드 | 설명 |
|---|---|
| Sequential | 정의한 순서대로 질문을 실행합니다. 이전 질문의 컨텍스트가 다음 질문에 필요할 때(예: 다중 턴 대화) 사용합니다. |
| Random | 질문을 무작위 순서로 실행합니다. 독립적인 질문에 유용하며 위치 편향을 줄이는 데 도움이 됩니다. |
단계 3 — 질문 정의하기
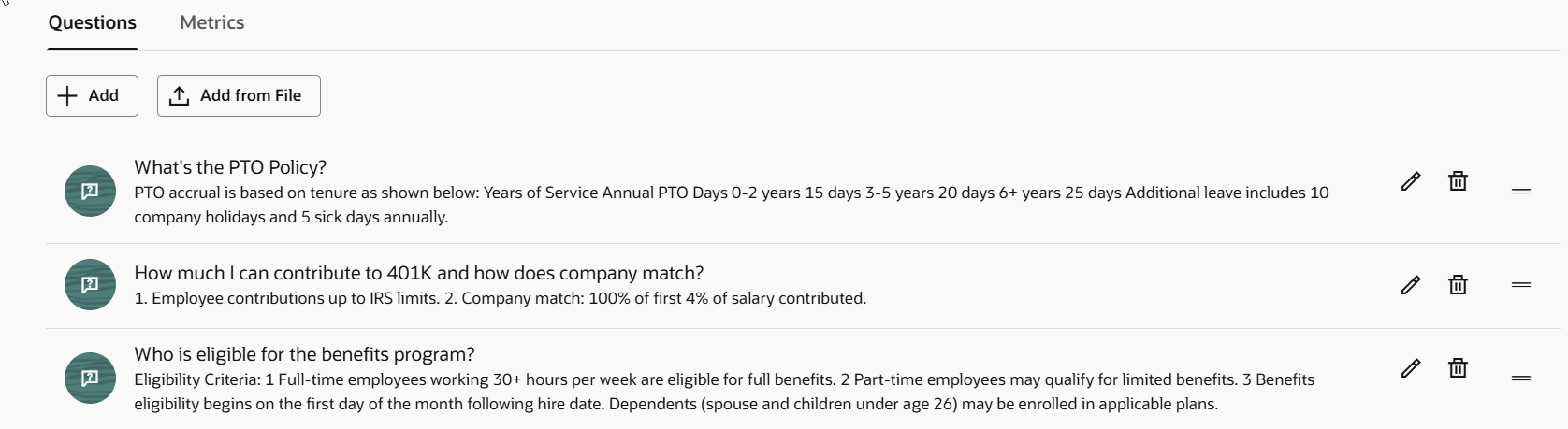
Questions 탭에서 사용자가 물어볼 것으로 예상되는 질문을 추가하고, 에이전트가 반환해야 할 정확한 응답을 짝지어 입력합니다.
예시 – HR 복리후생 에이전트
Q: 복리후생 프로그램에 누가 자격이 있나요?
A:
Eligibility Criteria:
- Full‑time employees working 30+ hours per week are eligible for full benefits.
- Part‑time employees may qualify for limited benefits.
- Benefits eligibility begins on the first day of the month following hire date.
- Dependents (spouse and children under age 26) may be enrolled in applicable plans.예상 응답은 가능한 한 실제 운영 수준에 가깝게 유지하세요. 정확도 메트릭은 정의한 기준 답변이 얼마나 정확한가에 따라 달라집니다.
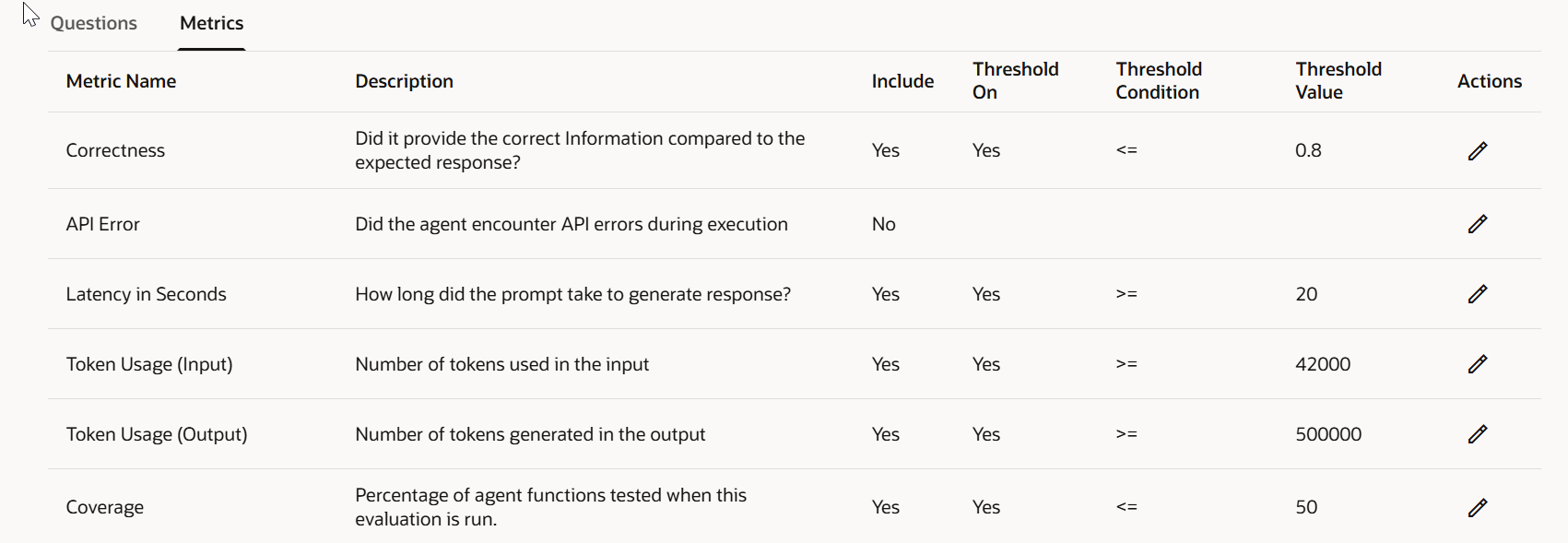
단계 4 — 메트릭 구성하기
Metrics 탭에서 이번 평가 실행에 포함할 메트릭을 선택합니다. 에이전트의 구체적인 사용 사례와 비즈니스 요구에 맞게 평가를 맞춤 설정하세요.
- 에이전트가 API를 호출하지 않는 경우 API 오류 메트릭을 제외할 수 있습니다 – 결과에 불필요한 잡음이 섞이지 않게 합니다.
- 정확도가 최우선인 경우(예: 정책·컴플라이언스 에이전트) 높은 정확도 임계값을 설정하세요 –
0.8정도가 엔터프라이즈 환경에서 합리적인 기준입니다. - 토큰 비용이 우려되는 경우 출력 토큰 임계값을 설정합니다, 예:
output_token_threshold: 150 # 응답당 최대 토큰 수임계값이 없는 메트릭은 단순 숫자에 불과합니다. 임계값이 있어야 숫자가 통과/실패 신호로 변환됩니다.
단계 5 — 평가 실행 시작하기
Initiate Evaluation Run 버튼을 클릭합니다. Oracle AI Agent Studio가 평가를 실행하고 각 질문에 대한 결과를 반환합니다. 포함 내용:
- 실제 응답 vs. 예상 응답 – 나란히 표시
- 질문당 지연 시간
- 토큰 사용량 (입력 및 출력)
- 선택한 메트릭에 대한 품질 점수
결과 읽기
실행이 완료된 후 결과를 검토하는 것이 실제 가치를 발휘하는 단계입니다. 다음은 예시입니다:
- Latency: 한 질문이 20초 이상 걸렸습니다 — 정의된 임계값을 초과했습니다. 이는 조사할 가치가 있는 빨간 신호입니다. 너무 복잡한 검색 단계, 큰 시스템 프롬프트, 또는 최적화가 필요한 지식 베이스 때문일 수 있습니다. 나머지 질문들은 임계값 내에 잘 들어왔습니다.
- Token Usage: 입력 및 출력 토큰 수 모두 허용 가능한 범위 내에 있었습니다. 예산에 좋은 소식입니다.
- Correctness: 임계값 0.8을 기준으로, 그 기준 이하 점수를 받은 질문은 검토를 위해 표시됩니다. 낮은 점수 질문들의 패턴은 종종 지식 베이스의 빈틈이나 시스템 프롬프트의 모호함을 드러냅니다.
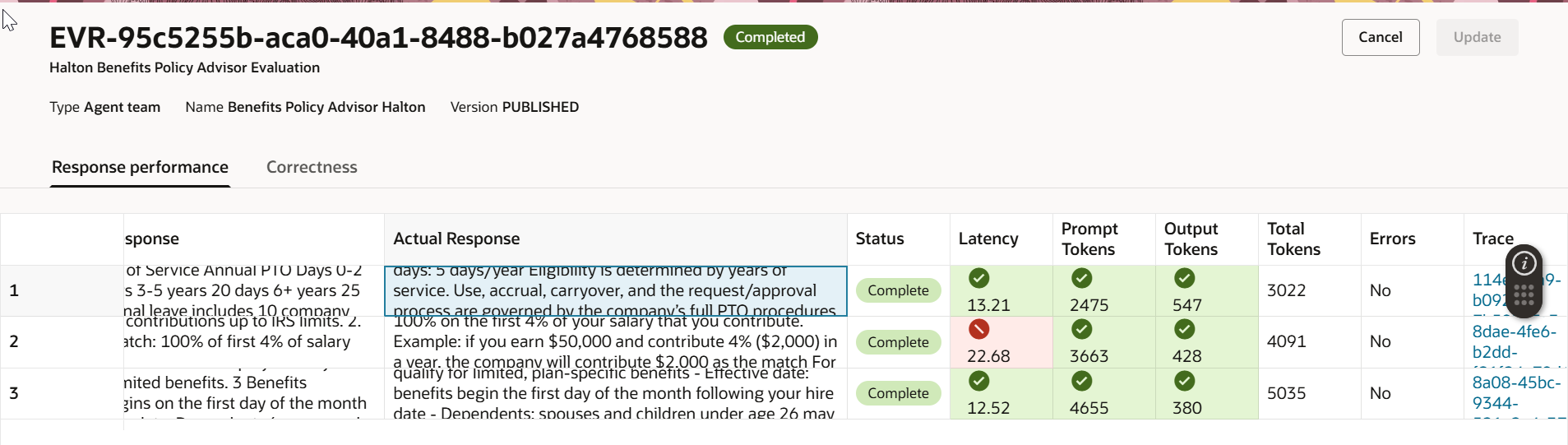
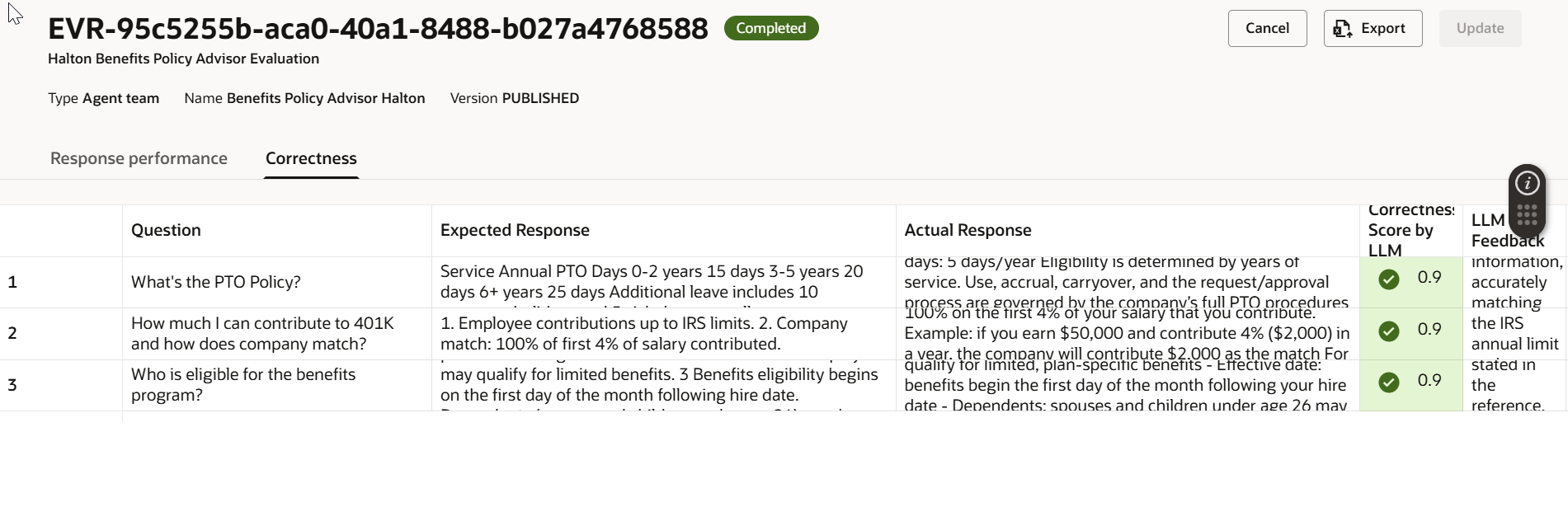
이 지연 시간, 비용, 품질 신호의 조합은 전체적인 그림을 제공합니다 — 단순히 “답변했는가?”가 아니라 “잘, 빠르게, 효율적으로 답변했는가?”를 보여줍니다.
Final Thoughts
평가를 통과한 AI 에이전트는 단순히 기술적으로 뛰어난 것에 그치지 않습니다 — 비즈니스 사용자가 “이게 맞는지 어떻게 알 수 있나요?” 라고 물었을 때 실제로 신뢰할 수 있는 에이전트입니다.
품질 임계값을 정의하고, 의미 있는 평가 세트를 구축하며, 기대 결과와 비교해 결과를 검토하는 것이 프로덕션‑준비된 에이전트와 데모 환경에서 실행되는 프로토타입을 구분하는 요소입니다. Oracle AI Agent Studio는 이를 올바르게 수행할 수 있는 도구를 제공합니다. 사용하세요.