DiffusionGemma, 구글 최강 속도 AI지만 큰 대가가 있다.
 구글
구글
TL;DR
- DiffusionGemma는 텍스트를 한 번에 큰 덩어리로 생성한 뒤, 단어를 하나씩 만드는 대신 계속 다듬어 나갑니다.
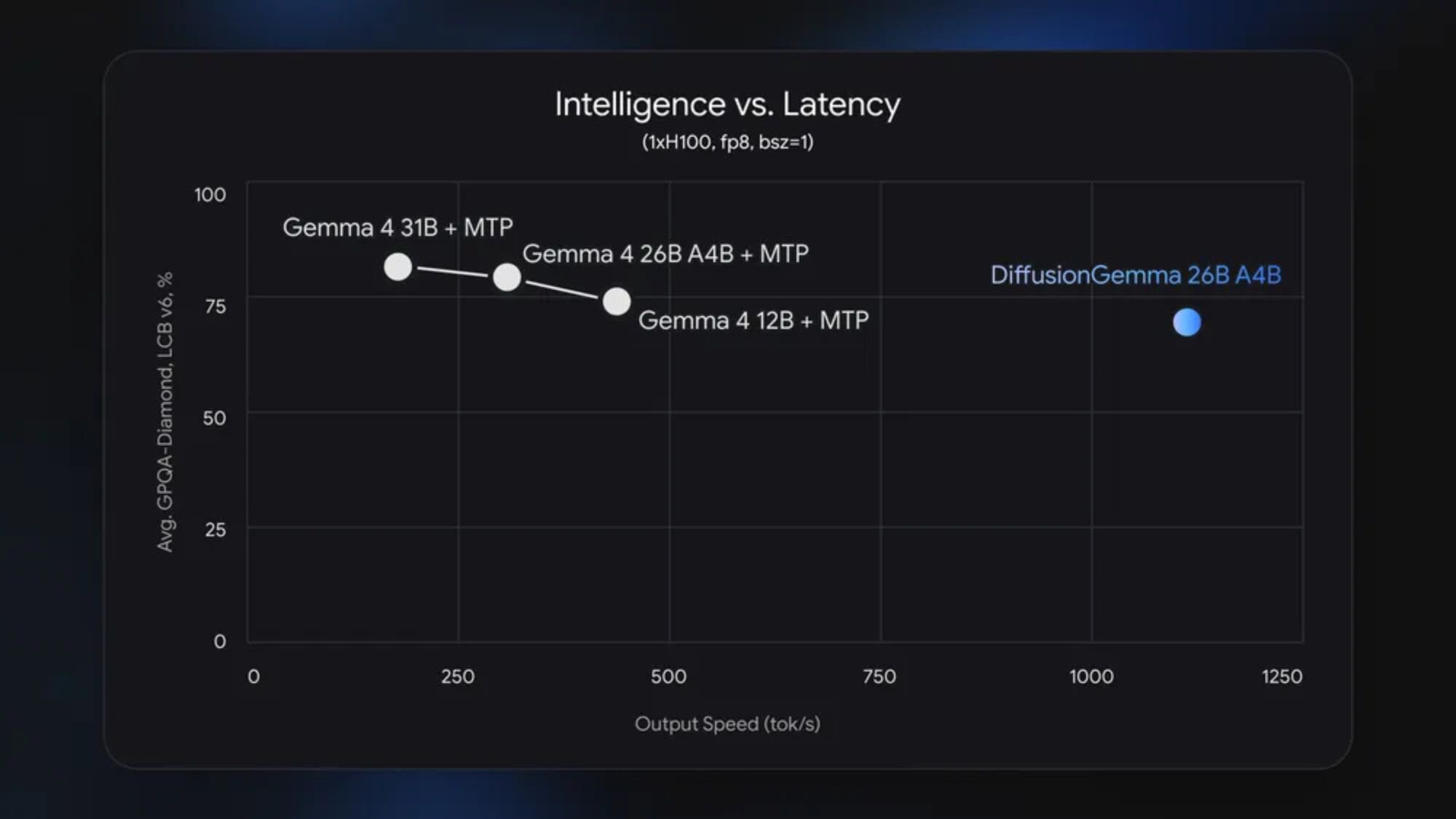
- 구글에 따르면, NVIDIA H100에서는 초당 1,000 토큰 이상, RTX 5090에서는 약 700 토큰을 달성하며, 병렬 처리 덕분에 최대 4배 빠릅니다.
- 출력 품질은 Gemma 4에 비해 아직 낮아, 완성된 제품이라기보다 실험용 도구에 가깝습니다.
구글은 DiffusionGemma라는 실험용 AI 모델을 공개했으며, 오늘날 대부분의 채팅봇이 텍스트를 생성하는 방식과는 매우 다른 접근 방식을 취합니다. 단어를 차례대로 하나씩 쓰는 대신, 한 번에 전체 텍스트 블록을 만들고 이를 읽을 수 있을 때까지 계속 다듬어 나갑니다. 이 방식은 최종 결과물의 다듬음 정도를 포기하더라도 속도와 하드웨어 효율성을 높이는 것이 목표입니다.
 구글
구글
이 새 AI 모델은 Apache 2.0 라이선스로 오픈소스화되었으며, 일반 사용자보다는 개발자와 연구자를 대상으로 합니다. 왜 이것이 중요한지 이해하려면 대부분의 대형 언어 모델이 어떻게 동작하는지 살펴볼 필요가 있습니다. Google의 Gemma 4와 같은 시스템은 텍스트를 한 번에 하나의 토큰씩 순차적으로 생성합니다. 새로운 단어는 앞서 나온 내용에 의존하기 때문에 과정이 본질적으로 순차적이며 가속화가 어렵습니다.
반면 DiffusionGemma는 무작위 토큰으로 가득 찬 전체 캔버스(즉, 잡음이 섞인 읽을 수 없는 텍스트)에서 시작해 여러 차례에 걸쳐 이를 점진적으로 정제합니다. 각 패스마다 출력은 점점 더 구조화되고 일관되게 변해 최종 응답에 도달합니다. 전통적인 모델이 “쓰기”를 한다면 DiffusionGemma는 “초안 작성 후 전체 편집”을 하는 셈입니다.
이러한 전환은 성능에 직접적인 영향을 미칩니다. 구글이 주장하길, DiffusionGemma는 단일 사용자나 프로세스가 GPU를 사용할 때 낮은 동시성 상황에서 기존 자동회귀 모델보다 최대 4배 빠를 수 있다고 합니다. 고성능 하드웨어에서는 그 차이가 더욱 두드러집니다. NVIDIA H100에서는 초당 1,000 토큰 이상, RTX 5090에서는 700 토큰 이상을 처리할 수 있다고 회사는 밝혔습니다.
내부 구조를 살펴보면 DiffusionGemma는 260억 파라미터를 갖춘 Mixture‑of‑Experts 모델이지만, 추론 시 전체를 한 번에 활성화하지는 않습니다. 약 38억 파라미터만 사용해 연산량을 억제합니다. 구글에 따르면, 이렇게 하면 양자화된 상태에서 고급 소비자용 GPU에서도 실행이 가능하며, 메모리 사용량은 약 18 GB VRAM에 머무른다고 합니다.
모델이 텍스트를 생성하는 방식이 특히 흥미로운데, 한 번에 최대 256개의 토큰을 병렬로 생성할 수 있으며, 각 토큰은 블록 내 모든 다른 토큰을 참조할 수 있습니다. 즉, 출력 전체에 대한 전역적인 시야를 갖게 되는 것입니다.
이 덕분에 구조화된 작업이나 규칙 기반 작업에 더 적합합니다. 예를 들어, 누락된 코드 조각을 채우거나 JSON 같은 구조화된 포맷을 완성하고, 스도쿠식 퍼즐 같은 논리 중심 문제를 해결하거나, 전체 출력의 일관성이 문장별 흐름보다 중요한 수학적 패턴을 다룰 때 유리합니다. 전체 블록을 한 번에 보기 때문에, 같은 생성 사이클 내에서 모순을 바로 잡을 수 있어 이후 토큰이 나와서 수정할 필요가 없습니다.
하지만 단점도 명확합니다. 구글은 DiffusionGemma가 표준 Gemma 4 모델의 출력 품질에 미치지 못한다는 점을 솔직히 인정합니다. 글이 덜 안정적이고 다듬어짐이 부족해 복잡하거나 미묘한 답변을 요구하는 상황에서는 신뢰성이 떨어집니다. 즉, 속도는 얻지만 다듬음은 잃는 셈입니다.
 구글
구글
이 때문에 구글은 이를 실험용 도구로 포지셔닝합니다—실시간 AI 도구, 인라인 작문·코딩 보조, 즉각적인 피드백이 최종 품질보다 중요한 빠른 반복 워크플로우 등에 적합하도록 설계된 것입니다.
따라서 DiffusionGemma는 기존 Gemini·Gemma 모델을 대체하려는 것이 아니라, 효율성과 반응성을 위해 출력 품질을 일부 포기하는 ‘속도 우선’ 실험이라고 볼 수 있습니다. 하지만 이 모델은 다음과 같은 새로운 방향을 시사합니다: 모델이 다음 단어를 예측하는 것이 아니라, 전체 텍스트 블록을 동시에 생성하고 다듬는 방식으로 텍스트를 만들어 나가는 것입니다.
Follow
우리 커뮤니티의 일원이 되어 주셔서 감사합니다. 게시하기 전에 댓글 정책을 읽어 주세요.