개발자를 위한 Claude Opus 4.6: Agent Teams, 1M Context, 그리고 실제로 중요한 것
Source: Dev.to

TL;DR – 새로운 내용
| 기능 | 무엇을 하는가 | 왜 중요한가 |
|---|---|---|
| 1 M 토큰 컨텍스트 | 한 번에 약 30 K 줄의 코드를 처리 | 전체 코드베이스를 이해, 단편이 아니라 |
| 에이전트 팀 | 여러 Claude 인스턴스가 병렬로 작업 | ~90 초 안에 코드 리뷰, ~30 분이 아니라 |
| 적응형 사고 | 4단계 노력 수준 (낮음 → 최고) | 간단한 작업은 비용을 적게, 필요할 때는 깊게 |
| 컨텍스트 압축 | 이전 컨텍스트를 자동 요약 | 컨텍스트 손실 없이 장기 세션 |
| 128 K 출력 토큰 | 출력이 4배 더 많음 | 잘린 조각이 아닌 완전한 구현 |
1. Agent Teams (Research Preview)
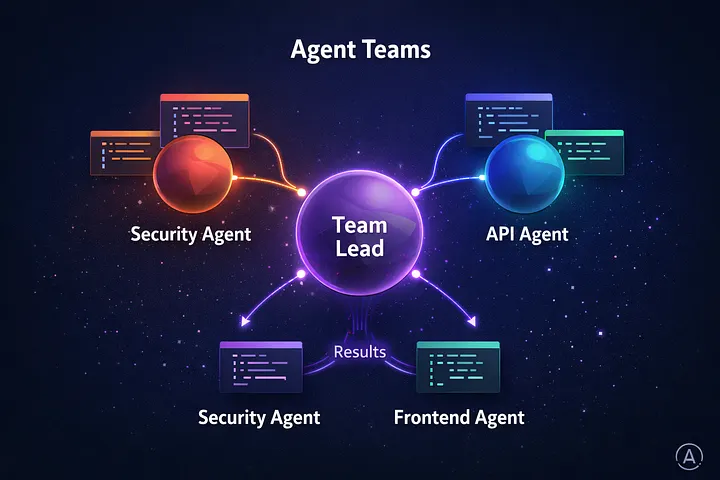
왜 중요한가 – Claude Code 사용자에게 핵심 기능입니다.
| 이전 | 이후 |
|---|---|
| 하나의 에이전트, 순차 처리(예: PR 파일을 하나씩 검토) | 팀 구조를 정의하고 Claude가 여러 에이전트를 생성해 독립적으로 작업하고 조정 |
활성화 방법
settings.json을 통해
{
"experimental": {
"agentTeams": true
}
}또는 환경 변수로
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=true최적 활용 사례
- 다계층 코드 리뷰 – 보안 에이전트 + API 에이전트 + 프론트엔드 에이전트
- 경쟁 가설 디버깅 – 각 에이전트가 서로 다른 이론을 병렬로 테스트
- 여러 서비스에 걸친 신규 기능 – 각 에이전트가 자신의 도메인 담당
- 대규모 리팩터링 – 모듈별로 분할 정복
실제 작동 방식
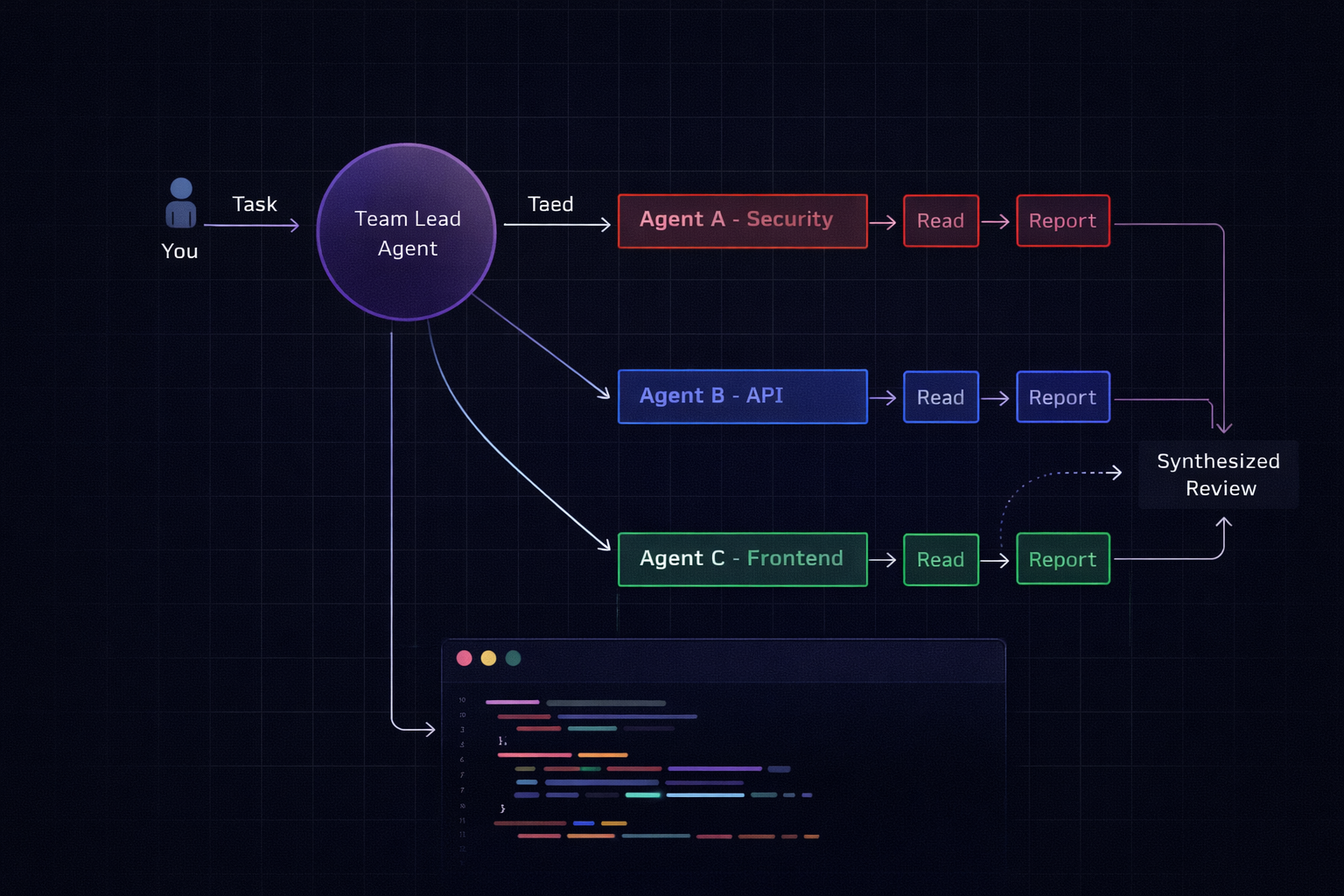
- 하나의 세션이 팀 리드 역할을 합니다.
- 리드는 작업을 하위 작업으로 분할하고 팀원 세션을 생성합니다(각각 고유한 컨텍스트 윈도우 보유).
- 팀원들은 독립적으로 작업하고 결과를 리드에게 전달합니다.
- 리드는 발견 내용을 종합합니다.
Shift+↑/↓ 또는 tmux를 사용해 언제든지 하위 에이전트로 전환할 수 있습니다.
프로 팁: 에이전트 팀은 읽기‑중심 작업에서 빛을 발합니다. 같은 파일을 동시에 수정해야 하는 쓰기‑중심 작업에서는 단일 에이전트 접근이 여전히 더 안정적입니다.
Source: …
2. 실제로 작동하는 1 M‑토큰 컨텍스트 윈도우
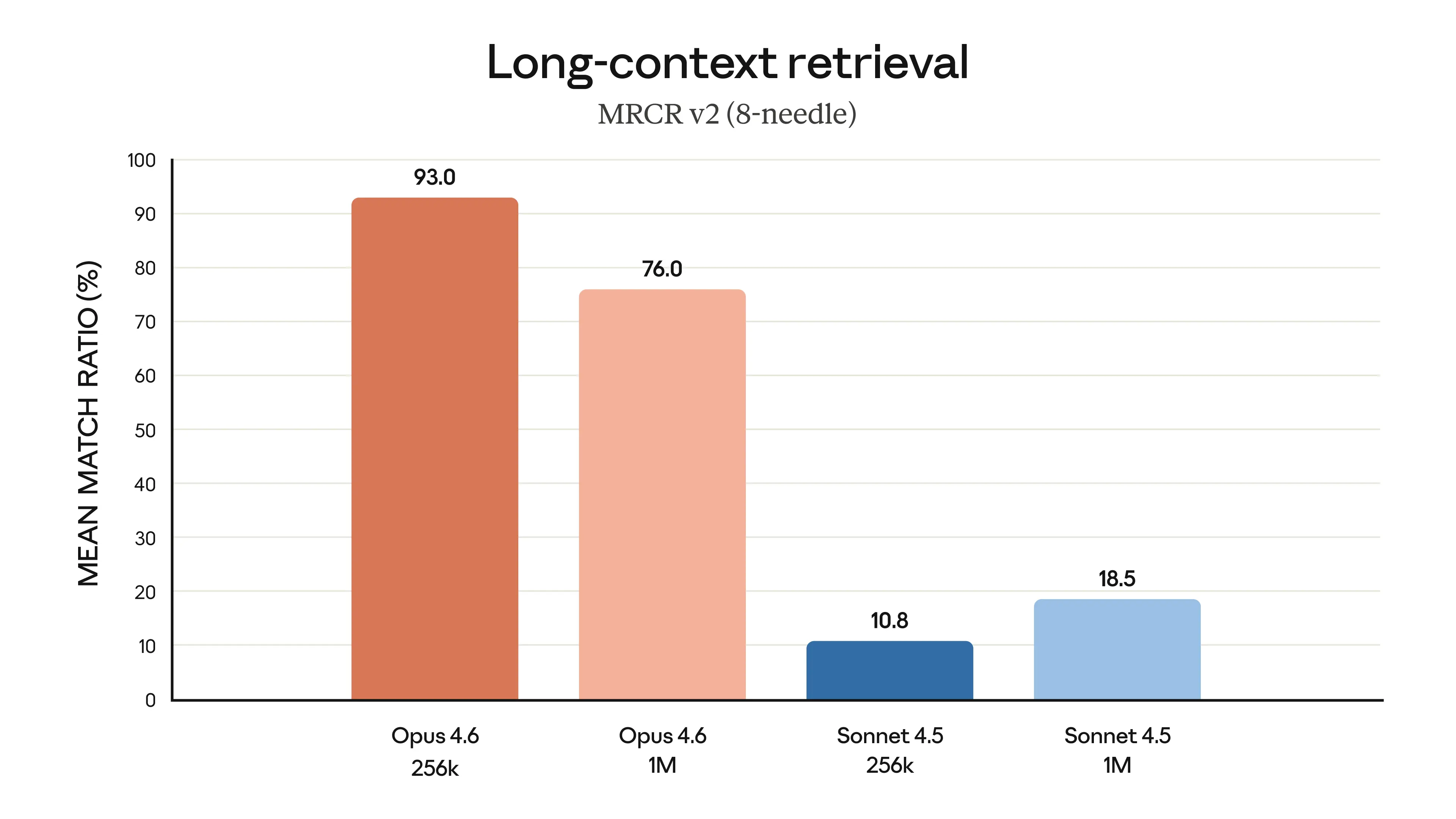
다른 모델들도 이전에 큰 컨텍스트 윈도우를 가졌었습니다. 여기서 차이는 검색 품질입니다.
Anthropic의 MRCR v2 벤치마크(대규모 컨텍스트에 숨겨진 특정 정보를 찾아내고 추론하는 모델의 능력을 측정)는 다음과 같이 나타냅니다:
Opus 4.6 : 76.0% ████████████████████████████████████████
Sonnet 4.5: 18.5% ███이것은 단순히 “토큰이 더 많다”는 것이 아닙니다. 모델이 컨텍스트에 있는 내용을 기억하는 것과 잊어버리는 것의 차이입니다.
이것이 일상 작업 흐름을 바꾸는 방식
| 작업 | 이전 (≈200 K 토큰) | 이후 (≈1 M 토큰) |
|---|---|---|
| 버그 추적 | 파일을 하나씩 넣고 아키텍처를 다시 설명 | “큐에서 API까지 버그를 추적” – 모든 것을 파악 |
| 코드 리뷰 | PR을 직접 요약 | 전체 diff와 주변 코드를 제공 |
| 새 기능 | 프롬프트에 코드베이스를 설명 | 모델이 전체 코드베이스를 직접 읽게 함 |
| 리팩토링 | ~15 파일 이후 컨텍스트 손실 | 47개의 파일 전체가 하나의 세션에 존재 |
실용적인 예시
# 전체 서비스를 Claude Code에 로드
cat src/**/*.ts | wc -l
# → 28 000 라인 – 1 M‑토큰 윈도우에 충분히 들어감
# Claude에게 전체 코드베이스에서 버그를 추적하도록 요청
> "The /api/tasks endpoint sometimes returns stale data.
> Trace the data flow from the queue processor through
> the cache layer to the API response handler."가격 참고: 표준 요금($5 / $25 per million input/output tokens)은 200 K 토큰까지 적용됩니다. 그 이상은 프리미엄 요금인 $10 / $37.50이 적용됩니다. 대부분의 개발 워크플로우에서는 200 K 토큰 이하로 유지됩니다.
3. Adaptive Thinking & Effort Levels

Claude Opus 4.6 introduces four effort levels (low → max). The model automatically selects the cheapest level that can satisfy the request, but you can force a higher level when you need deeper reasoning or more exhaustive code generation.
| Effort level | Typical use case | Cost impact |
|---|---|---|
| Low | Simple look‑ups, one‑line fixes | Minimal |
| Medium | Routine refactoring, standard PR review | Moderate |
| High | Complex architectural changes, multi‑service debugging | Higher |
| Max | Full‑stack feature implementation, exhaustive testing scaffolding | Highest |
How to control effort
In settings.json
{
"defaultEffort": "medium", // low | medium | high | max
"allowEffortOverride": true // let the UI expose a selector
}Inline in a prompt
@effort=high
Please generate a complete CRUD module for the `Task` entity, including validation, service layer, and unit tests.When to use each level
| Situation | Recommended effort |
|---|---|
| Quick typo fix or one‑liner | Low |
| Standard code review or linting | Medium |
| Cross‑service bug hunt, performance profiling | High |
| End‑to‑end feature scaffolding, design‑level reasoning | Max |
Bottom line
- Agent Teams let you parallelise read‑heavy work and keep each sub‑task’s context tidy.
- 1 M‑token context means you can hand Claude the whole repo and let it reason holistically.
- Adaptive effort levels give you fine‑grained cost control without sacrificing depth when you need it.
If you’re already using Claude Code, enable the experimental flags, start feeding larger chunks of your codebase, and let the model decide how much “thinking” power to apply. Your daily dev workflow will become faster, cheaper, and far less context‑starved.
새로운 API 매개변수: thinking.budget_tokens (노력 수준과 결합)
// 빠른 이름 변경 – 과도하게 고민하지 마세요
const response = await anthropic.messages.create({
model: "claude-opus-4-6",
thinking: { type: "enabled", effort: "low" },
messages: [{ role: "user", content: "Rename userId to accountId across this module" }]
});
// 복잡한 아키텍처 결정 – 깊게 파고들기
const response = await anthropic.messages.create({
model: "claude-opus-4-6",
thinking: { type: "enabled", effort: "max" },
messages: [{ role: "user", content: "Design the migration strategy for moving from REST to GraphQL" }]
});노력 수준
| Level | Description |
|---|---|
low | 최소한의 추론; 빠르고 저렴함. |
medium | 추론과 비용의 균형. |
high | 기본 수준; 철저하지만 효율적. |
max | 완전한 추론; 최고 품질. |
Adaptive Mode
thinking.type이 adaptive 로 설정되면 모델이 자동으로 적절한 노력 수준을 선택합니다:
- 간단한 질문 → 빠르고 저렴한 답변.
- 복잡한 추론 → 전체 처리 응답.
비용 측면에서 중요한 이유
프로덕션에서 AI 기반 도구를 운영할 때 모든 요청에 최대 지능을 사용할 필요는 거의 없습니다. Adaptive thinking을 활용하면 다음을 할 수 있습니다:
- 사소한 쿼리를 더 빠르고 저렴한 모델로 라우팅.
- 가장 강력한 모델(예: Opus)을 까다로운 작업에만 사용.
우리는 Glinr 에서 이 패턴을 적용하여 간단한 쿼리는 경량 모델로, 복잡한 작업은 Opus로 동적으로 라우팅합니다. Adaptive thinking은 이러한 라우팅 로직을 모델에 직접 내장시켜 지연 시간과 비용을 줄여줍니다.
4. 컨텍스트 압축 (베타)
const response = await anthropic.messages.create({
model: "claude-opus-4-6",
context_compaction: { enabled: true },
// ... long conversation history
});왜 중요한가
- 압축을 사용하지 않으면 2시간짜리 리팩토링 세션이 어떤 컨텍스트 제한도 초과하게 됩니다.
- 압축을 사용하면 모델이 이전 작업의 요약을 유지하면서 최근 턴에 대한 전체 세부 정보를 보존합니다.
- 이를 대화 기록에 대한
git squash로 생각하면 됩니다.
5. 개발자를 위한 중요한 벤치마크
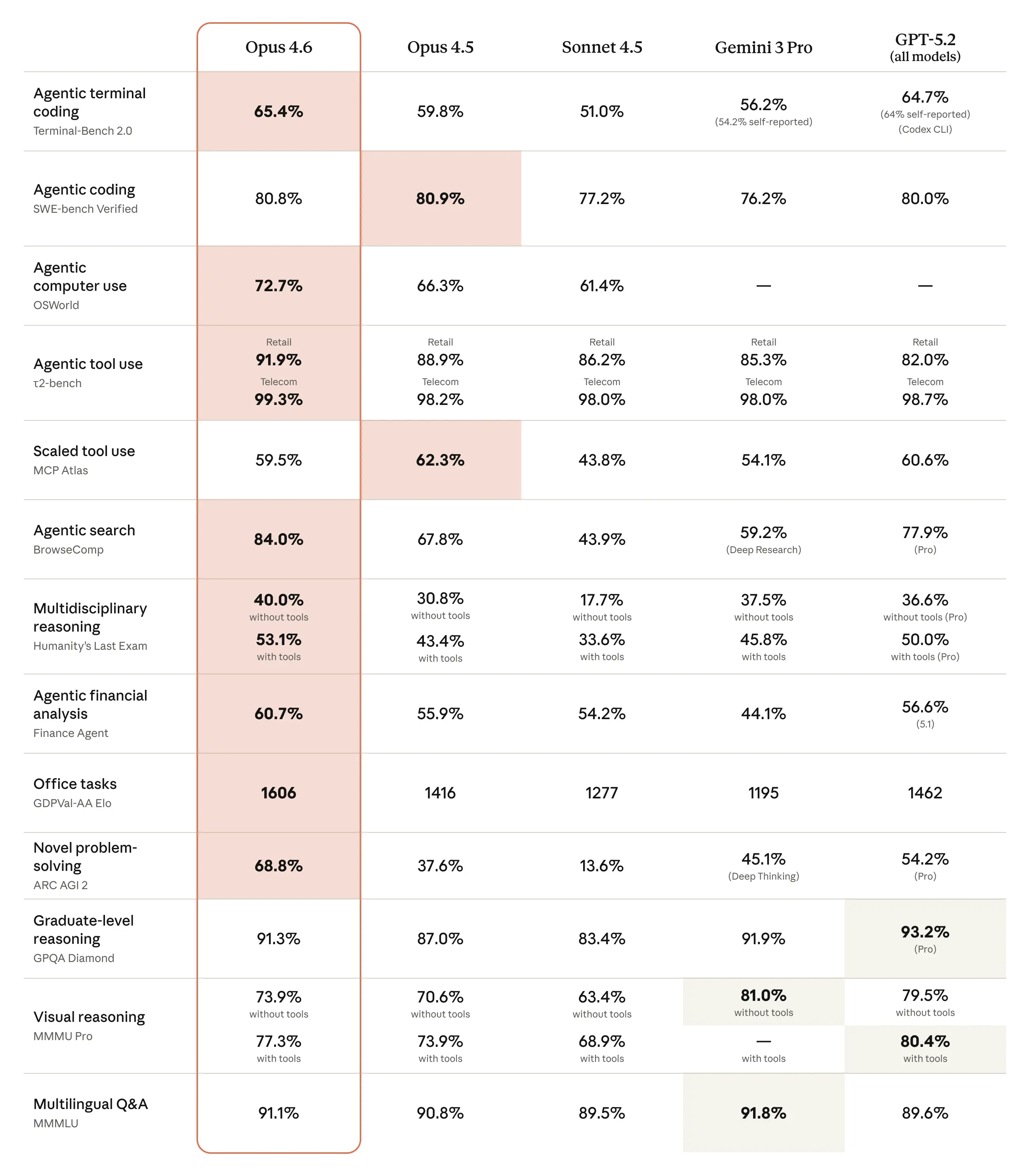
학술적인 벤치마크는 건너뛰세요. 코드 작성을 위해 중요한 것은 다음과 같습니다:
| Benchmark | Opus 4.6 | Opus 4.5 | 테스트 내용 |
|---|---|---|---|
| Terminal‑Bench 2.0 | 65.4 % | 59.8 % | 실제 에이전트 기반 코딩 작업 |
| SWE‑bench Verified | 80.8 % | ~72 % | 실제 GitHub 이슈 해결 |
| MRCR v2 (1 M) | 76.0 % | N/A | 장기 컨텍스트 검색 |
| HLE | #1 | – | 가장 어려운 추론 문제 |
Terminal‑Bench 점수는 특히 중요합니다. 이 점수는 모델이 전체 터미널 환경에 접근하여 테스트를 실행하고, 디버깅하며, 반복 작업을 수행할 때 얼마나 잘 수행되는지를 측정합니다. 65.4 % 성공률은 모델이 복잡한 코딩 작업의 거의 3분의 2를 자율적으로 해결할 수 있음을 의미합니다.
6. 보안: 500개 + 제로‑데이 발견
출시 전, Anthropic 팀은 Opus 4.6을 사용해 오픈‑소스 코드베이스에서 취약점을 탐색했습니다. 스캔을 통해 500 + 이전에 알려지지 않은 제로‑데이 취약점이 발견되었으며, 단순 충돌 버그부터 심각한 메모리 손상 결함까지 다양했습니다. 눈에 띄는 사례 중 하나로, Claude가 자동으로 개념 증명(Proof‑of‑Concept) 익스플로잇을 생성해 해당 발견을 검증했습니다.
주요 시사점
- AI는 전통적인 테스트가 놓치는 수백 개의 중요한 버그를 발견할 수 있습니다.
- 자동화된 개념 증명 생성은 검증 및 수정 작업을 가속화합니다.
- 보안 감사를 위해 AI를 활용하는 것은 소프트웨어 보호 방식에 큰 변화를 가져옵니다.
보안 감사를 위해 AI를 사용하고 있다면, 이것은 큰 변화를 의미합니다.
핵심 요약
Opus 4.6은 사소한 업그레이드가 아닙니다. 다음 요소들의 조합이:
- 실제로 작동하는 컨텍스트 – 1 M 토큰, 76 % 검색 정확도
- 병렬 에이전트 팀 – 분할 정복
- 적응형 노력 – 필요한 만큼만 비용 지불
- 컨텍스트 압축 – 몇 분이 아니라 몇 시간 동안 지속되는 세션
…정성적으로 다른 도구를 만들어냅니다. “AI 자동완성”보다는 “AI 개발 팀”에 가깝습니다.
이 모델은 현재 API의 claude-opus-4-6, Claude Code, 그리고 claude.ai를 통해 이용할 수 있습니다.
*우리는 **Glinr*에 Opus 4.6의 기능을 통합하고 있습니다 — 모델 간을 지능적으로 라우팅하고, 다중 에이전트 워크플로를 관리하며, 티켓부터 배포까지 모든 것을 추적하는 AI 작업 오케스트레이션 플랫폼입니다. AI 기반 개발 도구를 만들고 있다면, 이야기를 나눠야 합니다.
Tags: ai, webdev, programming, productivity, Claude4.6, GLINR
더 많은 콘텐츠를 원한다면 팔로우하고 좋아요를 눌러 주세요
- Medium –
- LinkedIn –
- Site –