FFI를 넘어서: Rust와 Lock‑Free Ring‑Buffers를 활용한 Zero‑Copy IPC
Source: Dev.to


작성자: Rafael Calderon Robles | LinkedIn
1. 호출 비용 신화: 마샬링과 런타임
오버헤드가 단지 CALL 명령어 때문이라는 오해가 흔합니다. 현대 환경(예: Python/Node.js → Rust)에서는 실제 “세금”이 세 가지 구분된 체크포인트에서 발생합니다:
| 체크포인트 | 발생하는 일 |
|---|---|
Marshalling / Serialization (O(n)) | JS 객체나 Python 딕셔너리를 C와 호환되는 구조(연속 메모리)로 변환합니다. 이 과정에서 CPU 사이클이 소모되고, Rust가 한 바이트도 접근하기 전에 L1 캐시가 오염됩니다. |
| Runtime Overhead | Python은 GIL을 해제하고 다시 획득해야 하며, Node.js는 V8/Libuv 장벽을 넘을 때 비용이 많이 드는 컨텍스트 스위치를 발생시킵니다. |
| Cache Thrashing | GC가 관리하는 힙과 Rust 스택 사이를 오가면서 데이터 지역성이 파괴됩니다. |
만약 초당 100 k개의 메시지를 처리한다면, CPU는 비즈니스 로직을 실행하기보다 경계 사이에서 바이트를 복사하는 데 더 많은 시간을 소비합니다.

2. 해결책: 공유 메모리 위의 SPSC 아키텍처
대안은 잠금‑프리 링 버퍼를 공유‑메모리 영역(mmap)에 두는 것입니다. 우리는 SPSC(단일 생산자 단일 소비자) 프로토콜을 구축하여 호스트가 쓰고 Rust가 읽으며, 핫 경로에서는 시스템 콜이나 뮤텍스를 전혀 사용하지 않습니다.
캐시 정렬 링 버퍼의 구조
이것을 생산 환경에서 정의되지 않은 동작(UB)을 일으키지 않게 실행하려면 메모리 레이아웃에 대해 엄격해야 합니다.
use std::sync::atomic::{AtomicUsize, Ordering};
use std::cell::UnsafeCell;
// Design constants
const BUFFER_SIZE: usize = 1024;
// 128 bytes to cover both x86 (64 bytes) and Apple Silicon (128 bytes pair‑prefetch)
const CACHE_LINE: usize = 128;
// GOLDEN RULE: Msg must be POD (Plain Old Data).
// Forbidden: String, Vec, or raw pointers. Only fixed arrays and primitives.
#[repr(C)]
#[derive(Copy, Clone)] // Guarantees bitwise copy
pub struct Msg {
pub id: u64,
pub price: f64,
pub quantity: u32,
pub symbol: [u8; 8], // Fixed‑size byte array for symbols
}
#[repr(C)]
pub struct SharedRingBuffer {
// Producer isolation (Host)
// Initial padding to avoid adjacent hardware prefetching
_pad0: [u8; CACHE_LINE],
pub head: AtomicUsize, // Write: Host, Read: Rust
// Consumer isolation (Rust)
// This padding is CRITICAL to prevent false sharing
_pad1: [u8; CACHE_LINE - std::mem::size_of::()],
pub tail: AtomicUsize, // Write: Rust, Read: Host
_pad2: [u8; CACHE_LINE - std::mem::size_of::()],
// Data: Wrapped in UnsafeCell because Rust cannot guarantee
// the Host isn’t writing here (even if the protocol prevents it).
pub data: [UnsafeCell; BUFFER_SIZE],
}
// Note: In production, use #[repr(align(128))] instead of manual arrays
// for better portability, but manual padding illustrates the concept here.
3. 프로토콜: Acquire/Release 의미론
뮤텍스를 잊고 메모리 배리어를 사용하세요.
Producer (Host):
data[head % BUFFER_SIZE]에 메시지를 씁니다.- Release 의미론으로
head를 증가시킵니다.
이렇게 하면 데이터 쓰기가 인덱스 업데이트가 관찰되기 앞에 보이게 보장됩니다.
Consumer (Rust):
- Acquire 의미론으로
head를 읽습니다. head != tail이면 데이터를 읽고tail을 증가시킵니다.
- Acquire 의미론으로
동기화는 하드웨어‑네이티브이며, 운영체제 개입이 필요하지 않습니다.
4. 기계적 친화성 및 잘못된 공유
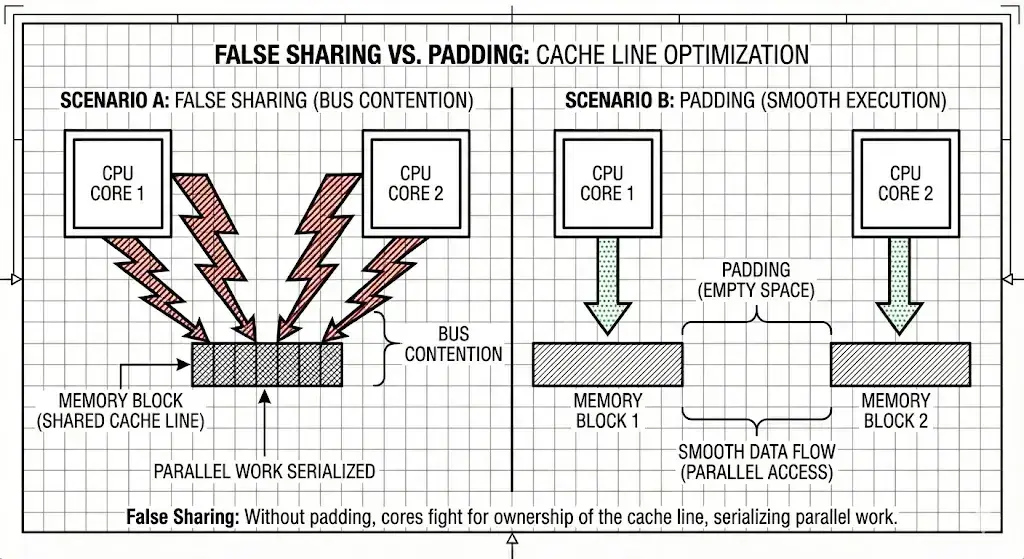
하드웨어를 무시하면 처리량이 급격히 감소합니다. 잘못된 공유는 head와 tail이 같은 캐시 라인에 존재할 때 발생합니다.
Core 1 (예: Python) 이 head를 업데이트하면 → 전체 캐시 라인이 무효화됩니다.
Core 2 (Rust) 가 그 같은 라인에 있는 tail을 읽으면 → MESI 프로토콜을 통해 캐시 라인이 동기화될 때까지 대기해야 합니다. 이는 성능을 한 단계(10배) 정도 저하시킬 수 있습니다.
Solution: 위 구조체와 같이 두 원자 변수 사이에 최소 128 바이트(패딩)의 물리적 간격을 강제로 두세요.
5. Wait Strategy: Don’t Burn the Server
무한 루프(while true)는 코어 하나를 100 % 사용하게 되며, 이는 클라우드 환경이나 배터리 구동 장치에서는 허용될 수 없습니다.
올바른 전략은 Hybrid(하이브리드)입니다:
- Busy Spin (≈ 50 µs):
std::thread::yield_now()를 호출합니다. OS에 실행을 양보하지만 “따뜻한” 상태를 유지합니다. - Park/Wait (Idle): X번 시도 후에도 데이터가 도착하지 않으면, 가벼운 차단 프리미티브(예: Linux의
Futex또는Condvar)를 사용하여 신호가 올 때까지 스레드를 잠재웁니다.
// Simplified Hybrid Consumption Example
loop {
let current_head = ring.head.load(Ordering::Acquire);
let current_tail = ring.tail.load(Ordering::Relaxed);
if current_head != current_tail {
// 1. Calculate offset and access memory (unsafe required due to FFI nature)
let idx = current_tail % BUFFER_SIZE;
let msg_ptr = ring.data[idx].get();
// Volatile read prevents the compiler from caching the value in registers
let msg = unsafe { ptr::read_volatile(msg_ptr) };
process(msg);
ring.tail.store(current_tail + 1, Ordering::Release);
} else {
// Backoff / Hybrid Wait strategy
spin_wait.spin();
}
}6. 포인터 함정: 진정한 제로‑카피
“Zero‑Copy”는 이 경우에 세부 조건이 따릅니다.
Warning:
Msg구조체 안에 포인터(Box,&str,Vec)를 절대 전달하지 마세요.
Rust 프로세스와 호스트 프로세스(Python/Node)는 서로 다른 가상 주소 공간을 사용합니다. Node에서 유효한 0x7ffee…와 같은 포인터는 Rust에서는 쓰레기값이며(그리고 대부분 세그멘테이션 오류를 일으킴) 됩니다.
데이터를 평탄화해야 합니다. 가변 길이 텍스트를 보내야 한다면 고정 버퍼([u8; 256])를 사용하거나 문자열‑슬랩 할당자를 위한 보조 링‑버퍼를 구현하되, 메인 구조는 평탄하게 유지하십시오(POD).
결론
공유 메모리 링 버퍼를 구현하면 Rust를 “빠른 라이브러리”에서 비동기 코프로세서로 변환합니다. 우리는 마샬링 비용을 없애고, 처리량이 거의 전적으로 RAM 대역폭에 의해 제한되도록 달성합니다.
하지만 이로 인해 복잡성이 증가합니다: 메모리를 수동으로 관리하고, 구조체를 캐시 라인에 맞게 정렬해야 하며, 컴파일러의 도움 없이 경쟁 조건을 방지해야 합니다. 표준 FFI가 명백히 병목인 경우에만 이 아키텍처를 사용하십시오.
Tags: #rust #performance #ipc #lock‑free #systems‑programming
추가 읽을거리