Agent Factory Recap: Agent Evaluation, Practical Tooling, 그리고 Multi-Agent Systems에 대한 심층 탐구
Source: Dev.to
번역할 텍스트를 제공해 주시면 한국어로 번역해 드리겠습니다.
에이전트 평가 해체
단위 테스트를 넘어: 에이전트 평가가 다른 이유
Timestamp: 02:20
에이전트를 평가하는 것은 전통적인 소프트웨어 테스트와 근본적으로 다릅니다.
- 전통적인 소프트웨어 테스트는 결정론적이며, 동일한 입력은 항상 동일한 출력을 생성합니다 (A = B).
- LLM 평가는 학교 시험과 유사합니다: 정적 지식을 Q&A 쌍으로 탐색하여 모델이 “무언가를 알고 있는지” 확인합니다.
- 에이전트 평가는 직무 성과 평가와 더 비슷합니다. 우리는 자율성, 추론, 도구 사용, 그리고 예측 불가능한 상황 처리 등을 포함한 복합 시스템의 행동을 평가합니다. 에이전트는 비결정론적이기 때문에 동일한 프롬프트가 서로 다르지만 동등하게 유효한 결과를 낼 수 있습니다.

전체 스택 접근법: 측정해야 할 것
타임스탬프: 04:15
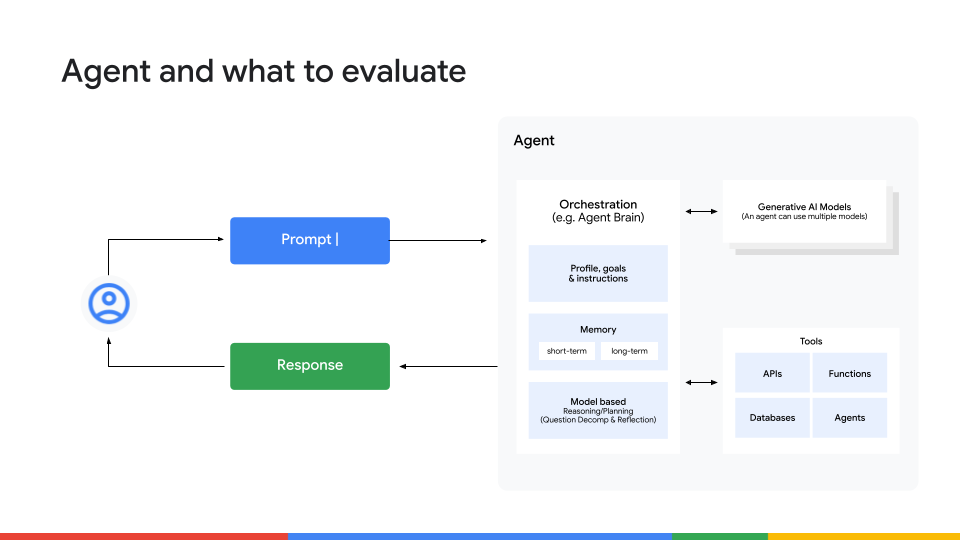
우리가 최종 결과만 보는 것이 아니라면, 무엇을 측정해야 할까요? 간단히 말하면 모든 것입니다. 에이전트의 행동을 네 가지 핵심 레이어로 살펴보는 전체 스택 접근법이 필요합니다:
-
최종 결과 – 에이전트가 목표를 달성했나요?
단순한 성공/실패를 넘어, 품질, 일관성, 정확성, 안전성, 그리고 환각 방지 등을 고려하세요. -
사고 흐름 (추론) – 에이전트가 어떻게 답에 도달했나요?
작업을 논리적인 단계로 나누었는지, 추론이 일관적인지 확인하세요. 운으로 정답을 맞춘 에이전트는 신뢰할 수 없습니다. -
도구 활용 – 에이전트가 올바른 도구를 선택하고 올바른 매개변수를 전달했나요?
효율성을 평가하고, 비용이 많이 드는 중복 API 호출 루프가 없는지 주시하세요. -
메모리 및 컨텍스트 유지 – 에이전트가 대화 초반의 정보를 필요할 때 기억할 수 있나요?
새로운 정보가 기존 지식과 충돌할 경우, 충돌을 올바르게 해결할 수 있나요?
Source:
How to Measure: Ground Truth, LLM‑as‑a‑Judge, and Human‑in‑the‑Loop
Timestamp: 06:43
Once you know what to measure, the next question is how. Below are three popular methods, each with its own pros and cons:
| Method | Strengths | Limitations |
|---|---|---|
| Ground‑Truth Checks | • Fast, cheap • Reliable for objective measures (e.g., “Is this a valid JSON?” or “Does the format match the schema?”) | • Cannot capture nuance or subjective quality |
| LLM‑as‑a‑Judge | • Scales well • Can score subjective qualities like plan coherence | • Judgments inherit the model’s training biases and may be inconsistent |
| Human‑in‑the‑Loop | • Gold‑standard accuracy • Captures nuance and domain expertise | • Slow and expensive |
Key Takeaway
Don’t rely on a single method. Combine them in a calibration loop:
- Create a golden dataset – have human experts produce a small, high‑quality set of annotated examples.
- Fine‑tune an LLM‑as‑a‑judge on that dataset until its scores align with the human reviewers.
- Deploy the calibrated judge for large‑scale automated evaluation.
This approach gives you human‑level accuracy at an automated scale.
공장 현장: 에이전트를 5단계로 평가하기
Factory Floor 섹션은 고수준 개념에서 Agent Development Kit (ADK) 를 활용한 실용적인 데모로 이동합니다.
실습: ADK 로 5단계 에이전트 평가 루프
타임스탬프: 08:41
ADK 웹 UI는 개발 중 빠르고 인터랙티브한 테스트에 최적입니다. 아래는 잘못된 도구를 사용하고 있던 간단한 제품 조사 에이전트를 디버깅하기 위해 사용한 5단계 “내부 루프” 워크플로우입니다.
-
“골든 패스” 테스트 및 정의
- 프롬프트:
Tell me about the A‑phones. - 에이전트가 잘못된 정보를 반환했습니다 (고객 설명 대신 내부 SKU).
- Eval 탭에서 응답을 수정하여 첫 번째 “골든” 테스트 케이스를 만들었습니다.

- 프롬프트:
-
골든 테스트에 에이전트 실행
- Run 탭에서 테스트를 실행합니다.
- 출력이 이제 기대한 설명과 일치하는지 확인합니다.
-
에지 케이스 테스트 추가
- 프롬프트 변형을 도입합니다 (예: 다른 제품명, 모호한 질의).
- 기대 결과를 Eval 탭에 기록합니다.
-
프롬프트 / 도구 선택 반복
- 실패에 따라 에이전트의 프롬프트 또는 도구 선택 로직을 조정합니다.
- 전체 테스트 스위트를 다시 실행해 회귀가 발생하지 않도록 합니다.
-
루프 자동화
- 테스트 스위트를 CI 파이프라인에 내보냅니다.
- ADK의 CLI를 사용해 각 커밋마다 평가를 자동으로 실행합니다.
Evaluation Workflow (with Screenshots)
-
평가 및 실패 식별
테스트 케이스를 저장한 뒤 평가를 실행했습니다. 예상대로 바로 실패했습니다.
-
근본 원인 찾기
Trace view를 열어 에이전트의 단계별 추론 과정을 확인했습니다. 에이전트가 잘못된 도구(lookup_product_information)를 선택한 것이 즉시 드러났습니다 (get_product_details가 아니라).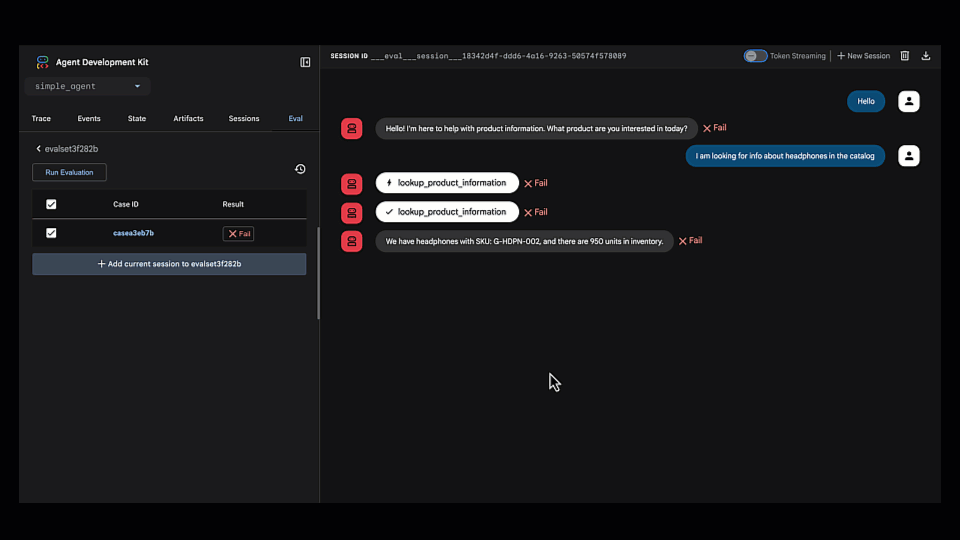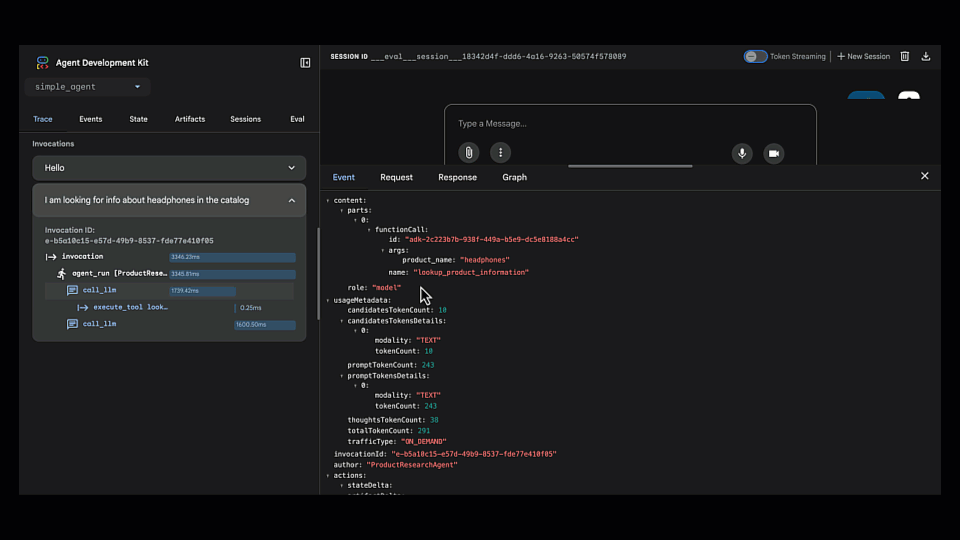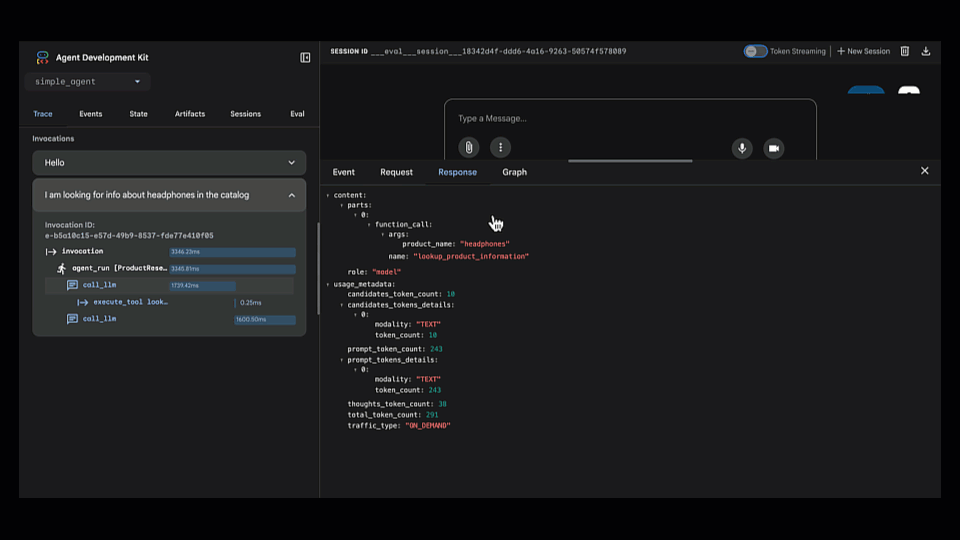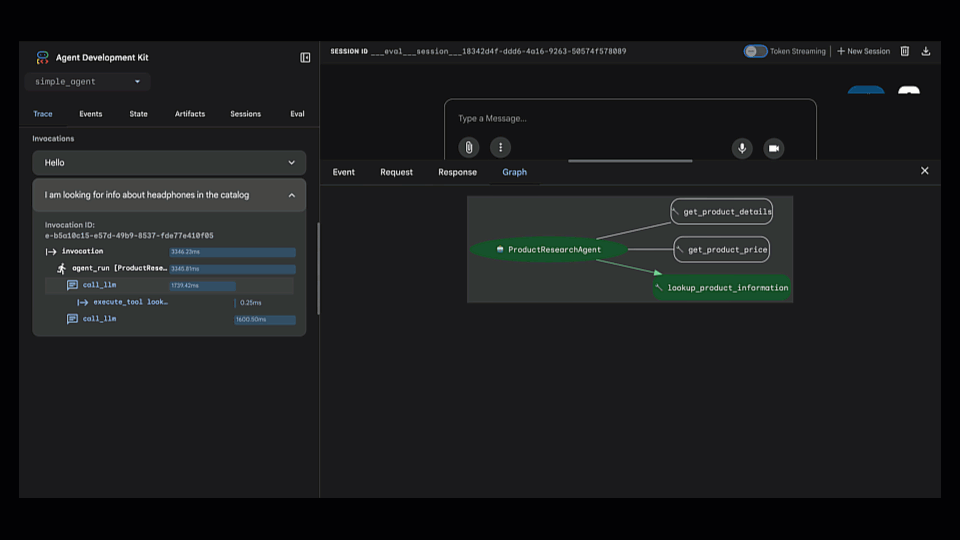
-
에이전트 수정
근본 원인은 모호한 지시였습니다. 고객용 요청과 내부 데이터 요청에 사용할 도구를 명확히 지정하도록 에이전트 코드를 업데이트했습니다. -
수정 검증
ADK 서버가 코드를 핫 리로드한 후 평가를 다시 실행했습니다. 이번에는 테스트가 통과했고 에이전트가 올바른 고객용 설명을 반환했습니다.
개발에서 프로덕션으로
ADK 워크플로는 개발에 뛰어나지만 확장성이 부족합니다. 프로덕션‑급 요구 사항을 위해서는 대규모 평가를 처리할 수 있는 플랫폼으로 이동하세요.
내부 루프에서 외부 루프로: ADK와 Vertex AI
Timestamp: 11:51
- 내부 루프용 ADK – 개발 중 빠르고 수동적인 인터랙티브 디버깅.
- 외부 루프용 Vertex AI – 풍부한 메트릭(예: LLM‑as‑a‑judge)과 함께 대규모 평가 실행. 복잡하고 정성적인 평가를 처리하고 모니터링 대시보드를 구축하려면 Vertex AI Gen AI evaluation services 를 사용하세요.
Source:
콜드‑스타트 문제: 합성 데이터 생성
Timestamp: 13:03
실제 데이터셋이 없을 때는 다음 네 단계 레시피로 합성 데이터를 만들 수 있습니다:
| 단계 | 설명 |
|---|---|
| 1️⃣ 작업 생성 | 대형 언어 모델(LLM)에 실제와 같은 사용자 작업을 생성하도록 프롬프트합니다. |
| 2️⃣ 완벽한 솔루션 작성 | “전문가” 에이전트를 사용해 각 작업에 대한 이상적인 단계별 솔루션을 작성합니다. |
| 3️⃣ 불완전한 시도 생성 | 약하거나 다른 에이전트가 동일한 작업을 시도하도록 하여 결함이 있는 출력을 생성합니다. |
| 4️⃣ 자동 채점 | LLM‑as‑a‑judge를 배치해 불완전한 시도를 완벽한 솔루션과 비교하고 점수를 부여합니다. |
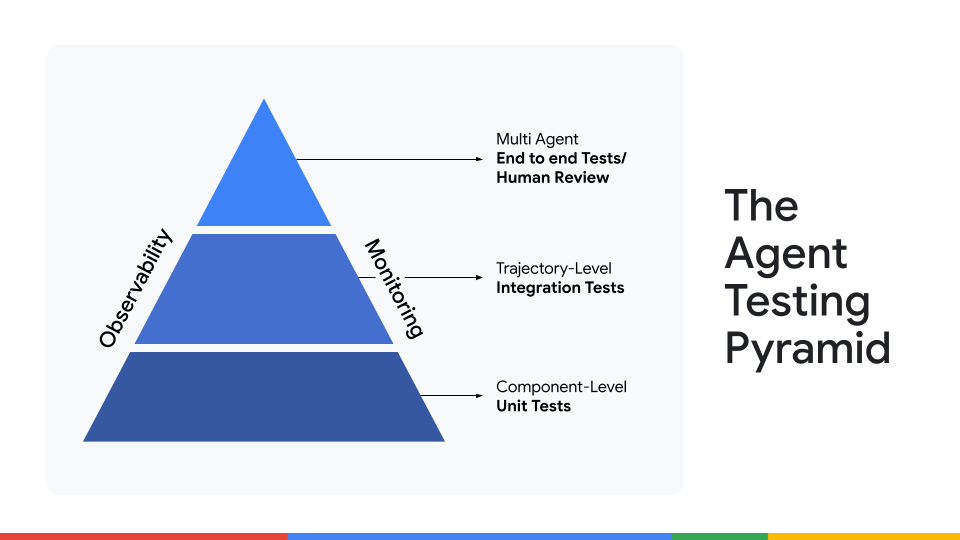
에이전트 테스트를 위한 3단계 프레임워크
타임스탬프: 14:10
평가 데이터를 보유하고 있다면, 세 단계로 확장 가능한 테스트를 설계하세요:
| 단계 | 목적 | 예시 |
|---|---|---|
| 1️⃣ 단위 테스트 | 가장 작은 구성 요소를 격리하여 테스트합니다. | fetch_product_price가 샘플 입력에서 올바른 가격을 추출하는지 확인합니다. |
| 2️⃣ 통합 테스트 | 단일 에이전트의 전체 다단계 여정을 평가합니다. | 에이전트에게 완전한 작업을 부여하고, 추론과 도구를 올바르게 연결하여 기대 결과를 도출하는지 확인합니다. |
| 3️⃣ 엔드‑투‑엔드 인간 검토 | 인간 전문가가 최종 출력의 품질, 뉘앙스, 정확성을 평가합니다. | “human‑in‑the‑loop” 피드백 시스템을 사용해 에이전트를 지속적으로 보정하고, 여러 에이전트 간 상호작용을 테스트합니다. |
The Next Frontier: Evaluating Multi‑Agent Systems
Timestamp: 15:09
단일 에이전트 파이프라인에서 다수의 에이전트를 오케스트레이션하는 방식으로 전환함에 따라 평가 방법도 진화해야 합니다. 향후 작업에는 다음이 포함됩니다:
- 시스템‑레벨 메트릭 정의 (예: 협업 효율성, 충돌 해결).
- 여러 에이전트를 가로질러 복잡한 사용자 여정을 시뮬레이션할 수 있는 자동화된 오케스트레이션 테스트 하니스 구축.
- 협업 결과를 평가하기 위해 LLM‑as‑a‑judge 프레임워크를 확장하여 개별 응답이 아닌 전체 협업을 판단하도록 함.
Evaluating Multi‑Agent Systems
에이전트를 개별적으로 판단하는 것만으로는 전체 시스템 성능에 대해 충분히 알 수 없습니다.
우리는 두 명의 에이전트가 있는 고객 지원 시스템을 예시로 사용했습니다:
- Agent A – 초기 연락을 담당하고 필요한 정보를 수집합니다.
- Agent B – 환불을 처리합니다.
고객이 환불을 요청하면 Agent A는 정보를 수집하고 이를 Agent B에게 전달하는 역할을 합니다.
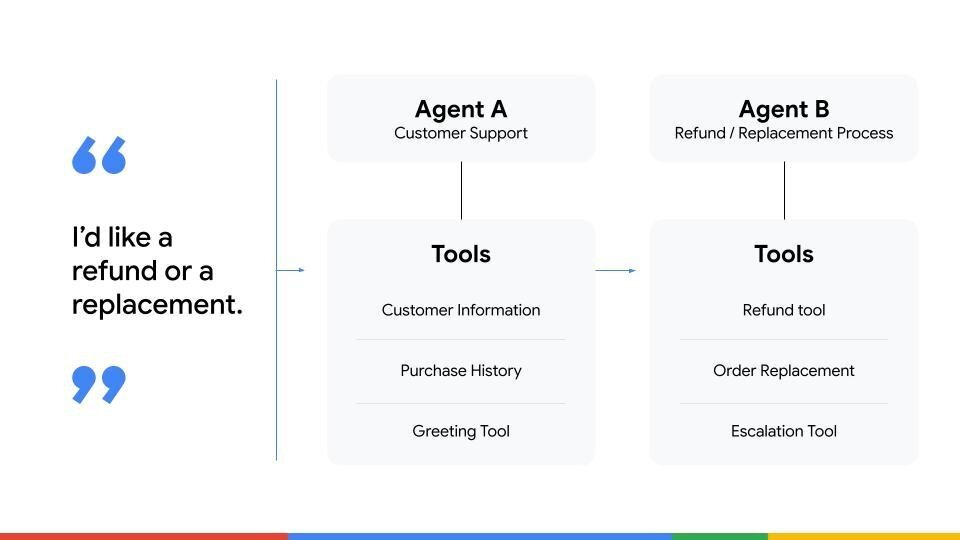
- Agent A만 평가하면 환불을 직접 수행하지 않기 때문에 작업 완료 점수가 0이 될 수 있습니다.
- 실제로는 작업을 성공적으로 전달함으로써 역할을 완벽히 수행했습니다.
- 반대로 Agent A가 잘못된 정보를 전달하면, Agent B의 로직이 완벽하더라도 전체 시스템이 실패합니다.
이 예시는 다중 에이전트 시스템에서 엔드‑투‑엔드 평가가 가장 중요함을 보여줍니다. 우리는 에이전트 간 작업 전달, 컨텍스트 공유, 최종 목표 달성을 위한 협업이 얼마나 원활하게 이루어지는지를 측정해야 합니다.
Open Questions and Future Challenges
Timestamp: 18:06
우리는 오늘 에이전트 평가에서 가장 큰 미해결 과제 중 일부를 짚어보며 마무리했습니다:
- 비용‑확장성 트레이드‑오프 – 인간 평가가 고품질이지만 비용이 많이 들고, LLM‑as‑a‑judge는 확장 가능하지만 신중한 보정이 필요합니다. 적절한 균형을 찾는 것이 핵심입니다.
- 벤치마크 무결성 – 모델이 점점 강력해짐에 따라 벤치마크 질문이 학습 데이터에 유출될 수 있어 점수의 의미가 감소합니다.
- 주관적 속성 평가 – 창의성, 주도성, 유머와 같은 에이전트 출력의 특성을 어떻게 객관적으로 측정할 수 있을까요? 이는 커뮤니티가 해결해야 할 미해결 질문으로 남아 있습니다.
직접 만들어 보기
이번 에피소드는 다양한 개념들로 가득했지만, 목표는 견고한 평가 전략을 사고하고 구현하기 위한 실용적인 프레임워크를 제공하는 것이었습니다. ADK의 빠르고 반복적인 루프부터 Vertex AI의 대규모 파이프라인에 이르기까지, 올바른 평가 마인드셋을 갖추는 것이 멋진 프로토타입을 프로덕션‑레디 에이전트로 전환시키는 핵심입니다.
전체 에피소드를 시청하여 데모를 직접 확인하고, 이러한 원칙을 여러분의 프로젝트에 적용해 보시기 바랍니다.