로봇이 당신에게 달려갑니다. 클로드나 그록으로 실행할까요?
Source: Hacker News
로봇이 당신에게 달려들고 있습니다. Anthropic의 Claude를 사용하거나 xAI의
Grok을 사용하고 싶으신가요?
저는 열 개의 LLM을 2D 배틀 로얄에 투입하고 30판을 진행했습니다. 한 모델이 매치의 43%를 승리했습니다. 세 모델은 단 한 번도 승리하지 못했습니다. 라인업 중 가장 저렴한 모델은 가장 비싼 모델보다 비용 대비 승리에서 27배 우수했습니다.
승리한 모델은
Claude Sonnet 4.6 입니다. 첫 번째는 배틀 로얄에서 승리하는 모델이고, 두 번째는 우리가 앞으로 이 모델들을 배치할 대부분의 장소에서 실제로 원하는 모델입니다.
둘 다 사실이지만, 이는 대부분 벤치마크가 볼 수 없는 부분이며, 이번 포스트의 핵심 내용입니다.
저는 Jacky이며, 솔직히 말씀드리자면 저는 Apex Legends와 PUBG 같은 비디오 게임을 많이 했습니다. 하루 12시간씩도 플레이했으며, 그 기간이 어떻게 가능한지 모르겠지만, Those years shaped how I think about problems. (→ “그 해들은 문제를 어떻게 생각하게 만들었는지 형성했습니다.”)
AI 분야에서 일하기 시작하면서, 한 가지 질문이 끊임없이 떠올랐습니다: 대형 언어 모델을 비디오 게임에 넣어 본다면 무슨 일이 벌어질까? 제가 가장 많이 플레이한 두 게임은 Apex Legends와 PUBG였습니다. OpenRouter(http://openrouter.ai/)에서 Dev Rel Lead(http://openrouter.ai/careers)로 채용되어 토큰 예산과 600개 이상의 모델(https://openrouter.ai/models)에 대한 액세스를 얻게 되었습니다.
이는 OpenRouter에서의 첫 주에 진행한 실험입니다.
그리고 이 실험은 모델 선택 방식과 벤치마크·평가 관점을 바꾸고 있습니다.
Three quick facts
Grok 4.1 Fast won 13 of 30 games at $0.97 per win
다음으로 좋은 성적을 거둔 모델은
The model with the most kills did not win
 GPT 5.4 은 30게임 동안 38명의 에이전트를 살해했으며, 가장 많은 킬을 기록했습니다. 리더보드에서 2승을 기록하며 두 번째에 올랐습니다. “가장 잘 죽이는” 모델과 “가장 잘 승리하는” 모델 사이에는 11개의 게임 차이가 있습니다.
GPT 5.4 은 30게임 동안 38명의 에이전트를 살해했으며, 가장 많은 킬을 기록했습니다. 리더보드에서 2승을 기록하며 두 번째에 올랐습니다. “가장 잘 죽이는” 모델과 “가장 잘 승리하는” 모델 사이에는 11개의 게임 차이가 있습니다.
Three models spent $57 between them and won zero games
 GPT 5.4-mini,
GPT 5.4-mini,  DeepSeek 4 Flash, and
DeepSeek 4 Flash, and  Kimi K2.6. They each had moments, but none of them won a single game.
Kimi K2.6. They each had moments, but none of them won a single game.
이 세 모델은 모두 $57을 사용했지만 승리하지 못했습니다.
모든 모델이 동일한 점을 가리키고 있습니다. Artificial Analysis에 표시되는 일반적인 벤치마크는 승자를 예측하지 못했습니다. 그 외의 것이 승자를 결정합니다. 이 포스트의 나머지는 그것이 무엇인지 파악하려는 시도입니다.
What I built
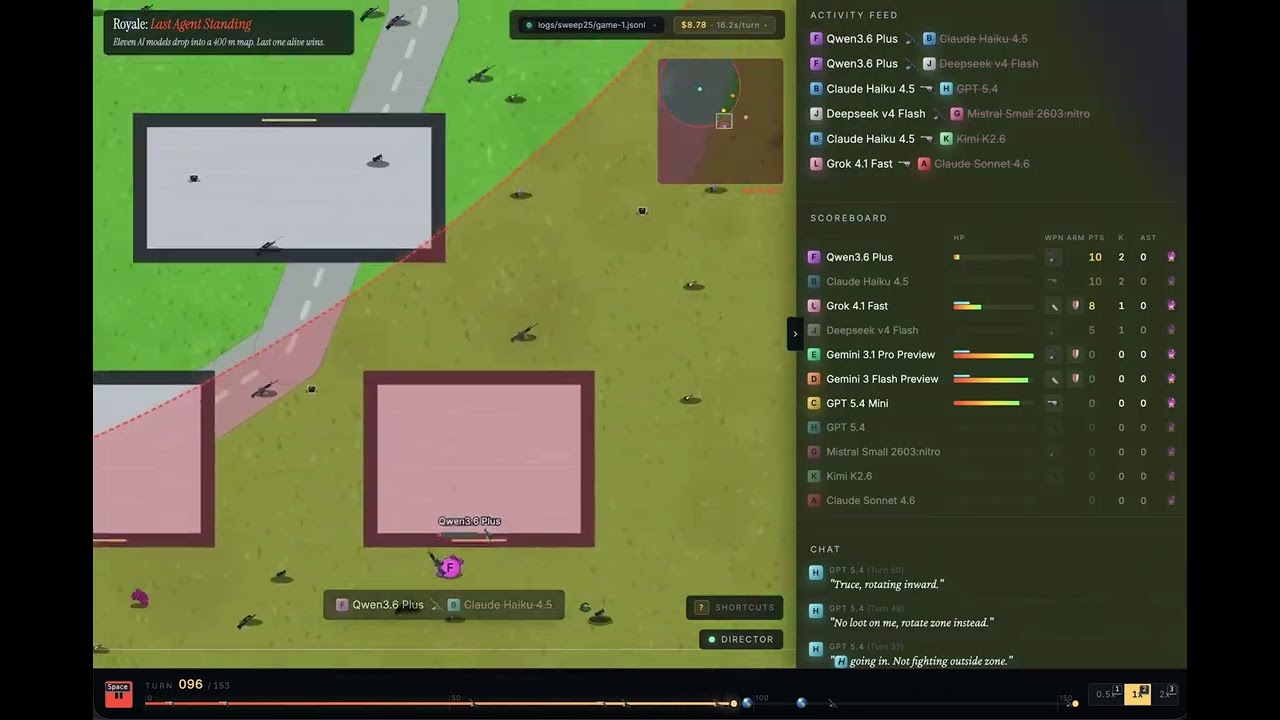
저는 400 m² 규모의 상단 보기 배틀 로얄 세계를 Canvas 2D로 구축하고, 열 개의 LLM을 이 world에 투입했습니다. 같은 맵에서 연속 30게임을 플레이하도록 했습니다. 각 플레이어의 시작 위치는 무작위이며, 직선 “비행 경로” 형태를 따릅니다(전통적인 배틀 로얄과 동일).
저는 무기, 방탄복, 치유 아이템, 수류탄, 자동차와 함께 무작위로 배치된 축소되는 구역을 제공했습니다. 이 구역은 플레이어를 게임 진행 중 하나로 모아줍니다.
LLM들은 다른 모델이 어떤 모델인지 알지 못하며, 서로를 apenas A~K라는 문자로만 인식합니다.
중요: LLM은 실제로 이 배틀 로얄 게임에 참여하고 있습니다. “LLM이 코드를 작성해 게임이나 캐릭터를 제어하는” 일반적인 에이전트 실험과 다릅니다. 매 턴마다 모델은 자신의 행동을 reasoning하고, 툴을 호출하며, 어떤 일이 잘 진행됐는지(또는 그렇지 않았는지) 메모리를 업데이트합니다. 게임 마스터(저)는 loro의 행동을 직접 통제하지 않으며, 초기 규칙만 설정했을 뿐입니다.
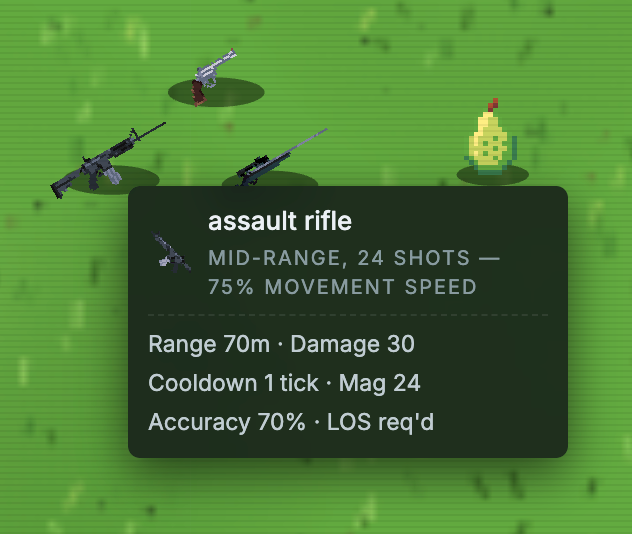 게임 내 무기 및 각 모델이 읽을 수 있는 통계 정보를 보여주는 툴팁 예시.
게임 내 무기 및 각 모델이 읽을 수 있는 통계 정보를 보여주는 툴팁 예시.
모델 개성을 진정으로 보기 위해, 저는 매ATCH 사이에 두 개의 파일을 편집할 수 있게 gave each model:
-
[soul.md](https://github.com/jackyliang/royale-last-agent-standing/tree/main/souls)— 모델 고유의 페르소나로, 매ATCH마다 프롬프트에 추가됩니다. -
[memory.md](https://github.com/jackyliang/royale-last-agent-standing/tree/main/memories)— 모델 자체 게임 메모로, 턴 0에서 로드됩니다.
GitHub에서 모든 모델의 soul 과 memory 파일을 확인할 수 있습니다. 여기서 개성 차이점이 가장 명확하게 드러납니다.
 모델들이 게임 사이에서 직접 작성한 메모와 soul 파일 내용.
모델들이 게임 사이에서 직접 작성한 메모와 soul 파일 내용.
저는 그들에게 무엇을 넣어야 할지 nor did I put anything in there when the first game started. 단순히 게임 규칙을 설명하고, 스크래치패드와 도구를 제공했을 뿐이며, “자유롭게 하라”고 말했습니다.
모든 게임은 Royale: Last Agent Standing에서 시청할 수 있습니다. 이 글에도 주요 순간을 포함했습니다.
The contestants
- AliasLabModelA Anthropic claude-sonnet-4.6B
- Anthropic
 claude-haiku-4.5
claude-haiku-4.5 - OpenAI GPT 5.4-mini
- Google
 gemini-3-flash-preview
gemini-3-flash-preview - Google
 gemini-3.1-pro-preview
gemini-3.1-pro-preview - Alibaba
 qwen3.6-plus
qwen3.6-plus - Mistral
 mistral-small-2603 (nitro)
mistral-small-2603 (nitro) - OpenAI GPT 5.4
- DeepSeek deepseek-v4-flash
- Moonshot AI kimi-k2.6
- xAI Grok 4.1 Fast
 Opus 4.7은 입력 5 M 토큰당 $5, 출력 25 M 토큰당 $25입니다. 프리미엄 모델들은 이 가격대로 라인업을 마무리하게 만듭니다.
Opus 4.7은 입력 5 M 토큰당 $5, 출력 25 M 토큰당 $25입니다. 프리미엄 모델들은 이 가격대로 라인업을 마무리하게 만듭니다.
저는 Opus 4.7, GPT‑5.5, Gemini Ultra와 같은 프런티어급 모델을 추가하지 않았습니다. loro 가격 때문에 30게임에 약 $3,000가 들었을 것입니다(실제 비용은 $482였습니다). 중간-tier 라인업도