FunctionGemma 파인튜닝 가이드
Source: Google Developers Blog
위에 제공된 소스 링크 외에 번역할 텍스트가 포함되어 있지 않습니다. 번역을 원하는 본문을 제공해 주시면 한국어로 번역해 드리겠습니다.
개요
Agentic AI 세계에서는 도구를 호출하는 능력이 자연어를 실행 가능한 소프트웨어 동작으로 변환합니다. 지난 달 우리는 **FunctionGemma**을 출시했으며, 이는 Gemma 3 270M 모델을 함수 호출에 특화하여 세밀하게 파인튜닝한 버전입니다. 이 모델은 자연어를 실행 가능한 API 동작으로 변환하는 빠르고 비용 효율적인 에이전트를 구축하는 개발자를 위해 설계되었습니다.
특정 애플리케이션은 종종 전문 모델을 필요로 합니다. 이 포스트에서는 tool‑selection ambiguity(도구 선택 모호성)를 처리하도록 FunctionGemma를 파인튜닝하는 방법을 보여줍니다—즉, 모델이 호출할 함수가 여러 개 비슷해 보일 때 어느 함수를 선택해야 할지 결정해야 하는 상황을 말합니다. 또한 **FunctionGemma Tuning Lab**을 소개합니다. 이 데모 도구는 훈련 코드를 한 줄도 작성하지 않고도 해당 과정을 손쉽게 수행할 수 있게 해줍니다.
Source: …
왜 툴 호출을 위해 파인‑튜닝을 할까?
FunctionGemma가 이미 툴 호출을 지원한다면, 파인‑튜닝이 여전히 유용한 이유는 무엇일까요?
답은 컨텍스트와 정책에 있습니다 — 일반 모델은 귀사의 비즈니스 규칙을 알지 못합니다. 파인‑튜닝을 하는 일반적인 이유는 다음과 같습니다:
선택 모호성 해소
사용자가 “여행 정책이 뭐야?”라고 물을 수 있습니다. 기본 모델은 공개된 구글 검색 결과를 기본으로 제시할 수 있지만, 기업 전용 모델은 내부 지식 베이스를 조회하도록 해야 합니다.초특화
공개 데이터에 존재하지 않는 틈새 작업이나 독점 포맷을 마스터하도록 모델을 학습시킵니다. 예를 들어 도메인‑특화 모바일 액션 (디바이스 기능 제어)이나 내부 API를 파싱해 복잡한 규제 보고서를 생성하는 작업 등이 있습니다.모델 증류
큰 모델을 사용해 합성 학습 데이터를 생성한 뒤, 그 워크플로를 효율적으로 실행할 수 있도록 더 작고 빠른 모델을 파인‑튜닝합니다.
사례 연구: 내부 문서 vs. 구글 검색
데이터셋
bebechien/SimpleToolCalling (Hugging Face TRL)
도전 과제
우리는 질의를 올바른 도구로 라우팅할 수 있는 모델이 필요했습니다:
| 도구 | 목적 |
|---|---|
search_knowledge_base | 내부 문서 |
search_google | 공개 정보 |
예시:
- 일반 질의: “Python에서 간단한 재귀 함수를 작성하기 위한 모범 사례는 무엇인가요?” → 구글 사용.
- 정책 질의: “여행 식비에 대한 환급 한도는 얼마인가요?” → 내부 지식 베이스 사용.
해결책
- 데이터셋 준비 – 데이터셋에는 두 도구 중 하나를 선택해야 하는 대화가 포함되어 있습니다.
- 학습‑테스트 분할 – 테스트 세트를 별도로 유지하여 보지 않은 데이터에 대한 평가를 수행하고, 모델이 라우팅 로직을 학습하도록 하며 예시를 암기하는 것을 방지합니다.
베이스 FunctionGemma 모델을 50 %/50 % 분할로 평가했을 때, 모델이 잘못된 도구를 선택하거나 정책을 “논의”하는 식으로 함수 호출을 제안하는 경우가 빈번했습니다.
⚠️ 데이터 분포에 관한 중요한 주의사항
데이터를 어떻게 분할하느냐는 데이터 자체만큼 중요합니다.
from datasets import load_dataset
# Load the raw dataset
dataset = load_dataset("bebechien/SimpleToolCalling", split="train")
# Convert to conversational format
dataset = dataset.map(
create_conversation,
remove_columns=dataset.features,
batched=False,
)
# 50 % train – 50 % test (no shuffling)
dataset = dataset.train_test_split(test_size=0.5, shuffle=False)왜 중요한가
- 가이드에서는 원본 데이터셋이 이미 섞여 있기 때문에
shuffle=False와 함께 50/50 분할을 사용했습니다. - 소스 데이터가 카테고리별로 정렬되어 있는 경우(예:
search_google예시가 모두 먼저 나오고, 그 다음에search_knowledge_base예시가 온다면) 셔플을 비활성화하면 모델이 한 도구만 학습하고 다른 도구만 테스트하게 되어 성능이 크게 떨어집니다.
베스트 프랙티스
- 소스 데이터가 혼합되어 있는지 확인합니다.
- 순서가 불분명하면
shuffle=True(또는 분할 전에 셔플) 설정을 통해 모든 도구가 학습에 균형 있게 포함되도록 합니다.
결과
모델은 SFTTrainer(Supervised Fine‑Tuning)를 사용해 8 epoch 동안 미세조정되었습니다. 손실 곡선은 새로운 라우팅 로직에 빠르게 적응함을 보여줍니다:
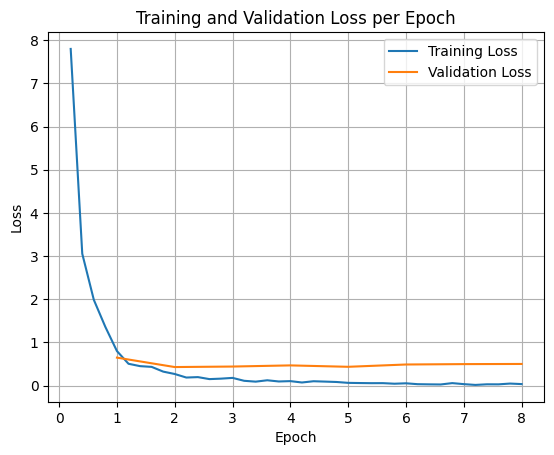
미세조정 후, 모델은 기업 정책을 안정적으로 따릅니다. 예를 들어, 다음 질의:
“새 Jira 프로젝트를 만드는 절차가 어떻게 되나요?”
는 이제 올바른 함수 호출을 반환합니다:
call:search_knowledge_base{query:Jira project creation process}모델은 내부 정책 질문과 공개 정보 질문을 구분하고, 적절한 도구를 자동으로 호출하도록 학습되었습니다.
FunctionGemma 튜닝 랩 소개
FunctionGemma 튜닝 랩은 Hugging Face Spaces에서 호스팅되는 사용자 친화적인 데모입니다. 모델에게 특정 함수 스키마를 학습시키는 전체 과정을 간소화합니다.
주요 기능
- 코드 없이 인터페이스 – UI에서 함수 스키마(JSON)를 직접 정의합니다; 파이썬 스크립트가 필요 없습니다.
- 맞춤 데이터 가져오기 – User Prompt, Tool Name, Tool Arguments가 포함된 CSV 파일을 업로드합니다.
- 원클릭 파인튜닝 – 슬라이더로 학습률과 에포크 수를 조정하고 즉시 학습을 시작합니다. 기본 설정은 대부분의 사용 사례에 적합합니다.
- 실시간 시각화 – 학습 로그와 손실 곡선이 실시간으로 업데이트되어 수렴을 모니터링할 수 있습니다.
- 자동 평가 – 학습 전후 성능을 자동으로 평가하여 개선 사항에 대한 즉각적인 피드백을 제공합니다.
튜닝 랩 시작하기
랩을 로컬에서 실행하려면 Hugging Face CLI로 저장소를 클론하고 앱을 시작합니다:
hf download google/functiongemma-tuning-lab --repo-type=space --local-dir=functiongemma-tuning-lab
cd functiongemma-tuning-lab
pip install -r requirements.txt
python app.py이제 코드를 작성하지 않고도 FunctionGemma를 파인‑튜닝할 준비가 완료되었습니다!
결론
TRL을 사용해 직접 학습 스크립트를 작성하든, FunctionGemma Tuning Lab의 데모 시각 인터페이스를 사용하든, 파인튜닝은 FunctionGemma의 전체 잠재력을 끌어내는 핵심입니다. 파인튜닝을 통해 일반적인 어시스턴트를 엄격한 비즈니스 로직을 준수하고 복잡한 독점 데이터 구조를 처리할 수 있는 전문 에이전트로 변환합니다.
읽어 주셔서 감사합니다!