Your Coding Agent Doesn't Need a Bigger Context Window. It Needs Coworkers.
Source: Dev.to
I’ve been building with Claude Code for months. It’s genuinely impressive — until your codebase gets big enough that the agent starts drowning in its own context.
The 1 M‑token context window sounds huge, but feed it a real project — a few hundred files, import chains six layers deep, config scattered across YAML and .env files — and you start hitting walls. Responses slow down, quality degrades, and costs climb because the model spends half its tokens reading code that isn’t relevant to your question.
The instinct is to wait for bigger context windows, but that’s the wrong fix. A smarter CTO doesn’t mean the CTO should personally review every line of code.
Enter AgentHub – a lightweight Python library that splits your codebase into specialized agents, routes queries to the right one, and lets them collaborate when a question spans multiple domains.
The Problem in Practice
Say you’re working on a Django project. You ask your coding agent:
“How does the payment flow work?”
The agent now has to process your auth middleware, URL routing, serializers, payment service, Stripe webhooks, database models, test fixtures… all of it loaded into one context window, most of it irrelevant.
The real answer lives in maybe 4‑5 files across 2‑3 modules, but the agent doesn’t know that upfront. It ingests everything, burns through tokens, and gives a diluted answer because it’s trying to hold too many things in its head at once.
This is a routing problem, not a capacity problem.
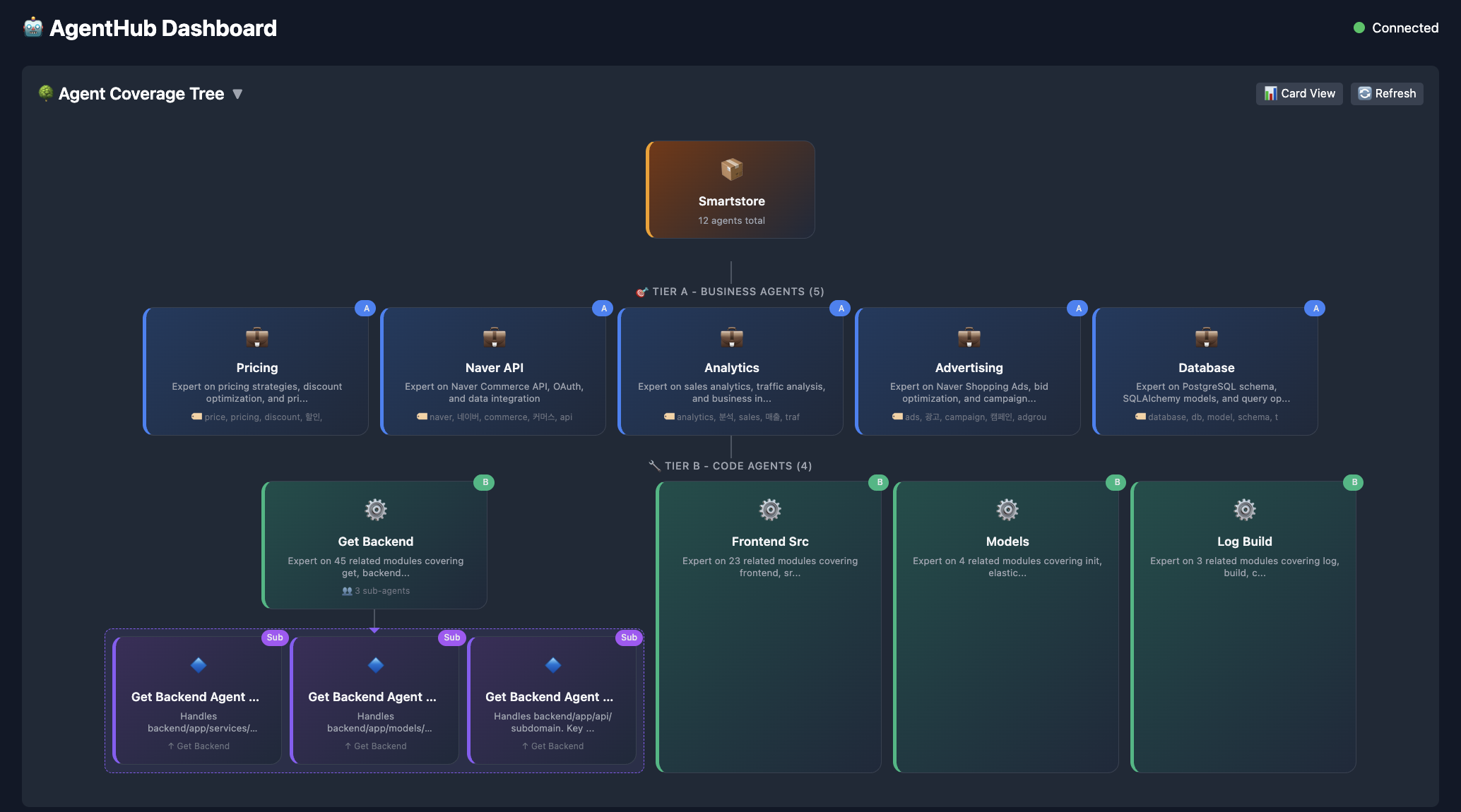
Layer 1: Auto‑Generated Domain Agents
The first insight is that your codebase already tells you where the natural boundaries are.
- Folders → domains
- Files → responsibilities
- Import graph → dependencies
Why not use that structure to create agents automatically?
AgentHub’s build command scans your repo and generates Tier B agents — one per logical domain, each pre‑loaded with only the files it owns.
from agenthub import AgentHub
from agenthub.auto import discover_all_agents
hub, summary = discover_all_agents("./my-project")
response = hub.run("How does user authentication work?")How it works
- File‑tree walk – maps the folder structure, sizes, and languages.
- Import graph construction – parses
importstatements to know, e.g.,api/views.py→services/auth.py→models/user.py. - Agent creation – builds focused agents, each with a context window loaded only with the files in its domain.
When a query arrives, a router scores it against each agent’s keywords and domain, then dispatches to the best match:
src/api/agent → API questionssrc/models/agent → schema questions
No wasted tokens.
Tier A agents (optional) are hand‑written for business logic that can’t be inferred from code structure, e.g., a pricing agent that knows margin rules or an analytics agent that knows KPI definitions.
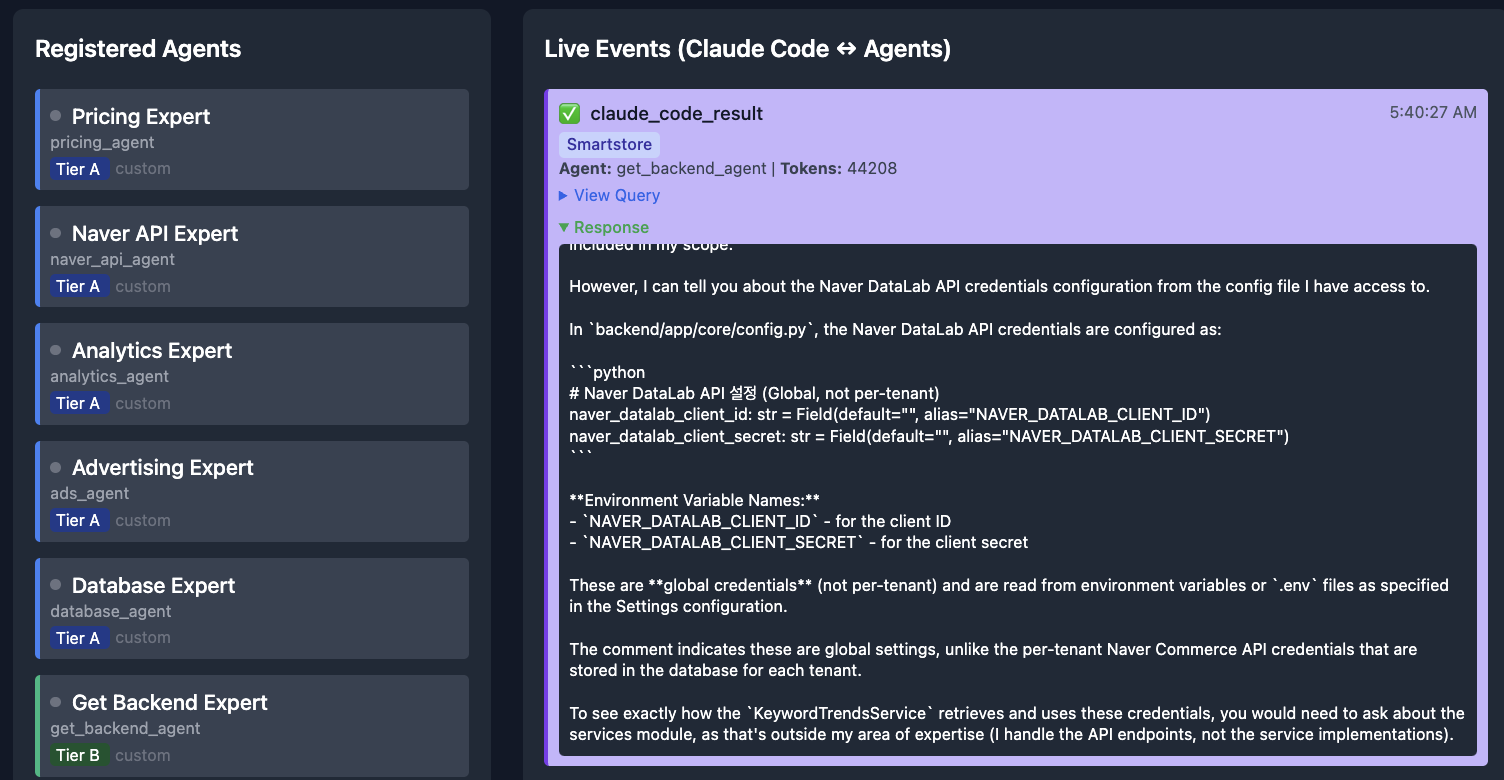
Layer 2: DAG Teams for Cross‑Cutting Questions
Single‑agent routing works great for scoped questions (“What does the UserSerializer class do?”). It breaks down for cross‑cutting ones (“How does the checkout flow work end‑to‑end?”), where the answer lives across API, service, model, and payment layers.
For these, AgentHub spins up a DAG team:
- Complexity classifier detects that the query spans multiple domains.
- Decomposer identifies the relevant agents.
- Import graph provides dependency edges between them.
- Execution – independent agents run in parallel; dependent ones run sequentially.
- Synthesizer merges the results into a coherent answer.
The DAG is built per query from the import graph, so the collaboration structure mirrors the actual code connections, not an imagined architecture.
Layer 3: Parallel Sessions
When a developer says, “Add a save button to the toolbar and build a time‑series chart component,” those are two independent tasks touching completely different files. Today, coding agents handle them sequentially. Why not run them in parallel?
AgentHub’s parallel sessions layer:
- Decomposes multi‑part requests into separate tasks.
- Analyzes file overlap using the import graph.
- Spins up independent Claude Code sessions on separate Git branches for tasks that don’t intersect.
- Each session is scoped to the files relevant to its task.
- A merge coordinator brings the branches together, runs tests, and catches semantic conflicts that Git alone can’t detect.
Think of this as the company model: when a startup is two people, the CTO (your coding agent) knows everything. As the company grows, you hire specialists (Tier B agents) that each own a slice of the knowledge, while the CTO orchestrates collaboration.
Overview
When departments get big, you organize teams (DAG teams). And when there’s a company‑wide initiative, teams work simultaneously on their own tracks, syncing at boundaries.
The merge step is where it gets tricky. Textual conflicts are easy — git handles those. Semantic conflicts are harder: two branches that merge cleanly but break each other’s assumptions. For those, AgentHub runs the test suite post‑merge. If tests fail, a resolution agent examines the failure, traces it back to the conflicting changes, and either fixes it or escalates to the developer.
Where It Stands
AgentHub is at v0.1.0. The core auto‑agent generation, DAG teams, and parallel‑session infrastructure are all implemented. It ships as a Python CLI and integrates with Claude Code via MCP, so the agents appear as tools right in your terminal.
Current Status
- Auto‑agent generation – works well; point it at a repo and you get useful agents.
- DAG teams – functional but need tuning on the decomposer prompts.
- Routing layer – deciding which agent gets a query still requires manual tweaking to perform reliably across different codebases.
- Parallel sessions – most experimental; git orchestration is solid, but semantic conflict resolution is still rough around the edges.
I’m not open‑sourcing this yet. There are enough rough edges that I want to get the routing and agent quality to a place I’m happy with before releasing it. However, I’m sharing the architecture because the core ideas—using import graphs for agent boundaries, DAG‑based collaboration, and the company‑growth model—are useful regardless of implementation.
If you’re building with coding agents and hitting context limits, I’d love to hear how you’re solving it.
Built by John. The entire AgentHub codebase was developed collaboratively with Claude — which felt appropriately recursive.