We won a Hackathon at Brown University 🏆
Source: Dev.to
Inspiration
We’ve all faced household‑repairing issues without knowing where to start. A woman living alone in an apartment, or a college freshman who just learned how to do laundry (that’s me!), may run into everyday problems: from clogged toilets to leaks in a water pipe.
Sometimes it feels uncomfortable inviting strangers into our living space just to check a minor issue. And in cities like New York, even a quick technician visit can be expensive, which becomes a real financial burden for both young adults and seniors. We realized that many people mainly need clear, step‑by‑step guidance on what to do first and what is actually safe to try.
That’s what inspired us to build an interactive home‑troubleshooting platform that feels like FaceTiming your dad: someone who has experience dealing with household appliances and repairs.
What it does
HandyDaddy helps when you’re dealing with household issues, ranging from a simple fan problem to more stressful tasks like figuring out how to plunge a toilet. Before HandyDaddy, we often ended up calling our dad or spending a long time searching online for information, but those options don’t provide live feedback for your specific situation.
HandyDaddy solves that by using live video to give step‑by‑step guidance based on what it sees. Instead of only prompting a language model and trusting whatever it generates, HandyDaddy uses a more reliable pipeline: structured outputs + RAG‑backed retrieval, so the response stays grounded, efficient, and safe.
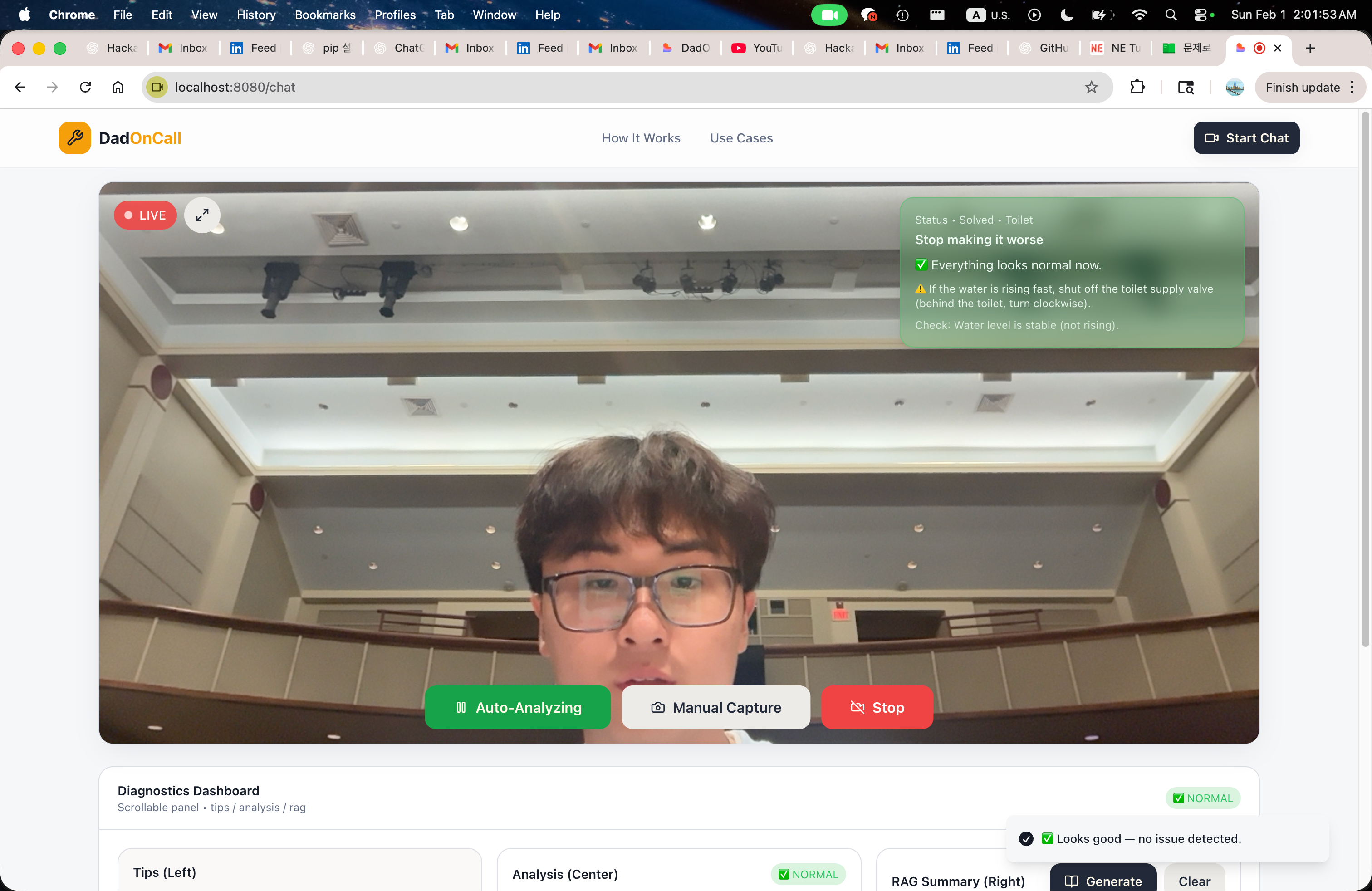
How we built it
We built HandyDaddy as a personal real‑time, vision‑first home‑repair assistant. The core idea was simple: instead of asking users to describe a problem, we let them SHOW it.
-
Vision layer – The system continuously captures images from a live video feed and sends them to Gemini, which acts as a vision model. For each frame, Gemini produces a structured analysis in JSON, identifying the fixture, location, potential issues, and safety level. This structured output becomes the groundwork for everything that follows and also generates a semantic search query optimized for documentation.
-
Retrieval‑Augmented Generation (RAG) – We built our own vector store using FAISS and sentence embeddings, indexing real repair and safety documents written in Markdown. Instead of asking the model to “figure it out,” we retrieve the most relevant information and feed it directly into the solution stage.
-
Planning layer – A high‑performance LLM from Groq synthesizes a clear, step‑by‑step plan from three inputs: the refined analysis, the retrieved documents, and safety constraints. This separation (vision → reasoning → retrieval → planning) keeps each model focused on a single responsibility and makes the system easier to debug and trust.
-
State management – All intermediate states are stored per session in Redis, allowing the system to track progress over time rather than treating each image as an isolated request. To make this transparent, we built a local “backstage viewer” that shows exactly how data flows through the pipeline, from raw vision output to final guidance.
Overall, HandyDaddy is similar to our dad: less about speed and power, but with careful orchestration—constraining outputs, separating responsibilities, and grounding decisions in real documentation.
Challenges we ran into

One of the hardest challenges was building the system architecture from the ground up while avoiding the temptation of creating just another GPT wrapper. We didn’t want HandyDaddy to feel like a chatbot that gives generic answers without actually understanding the situation. Since this tool is meant to help real people with real problems—sometimes involving water, electricity, or safety—guessing was not acceptable.
To make the system trustworthy, we had to design a much more complex architecture than we originally expected. Instead of letting one model do everything, we separated the system into clear stages:
- Visual understanding (Gemini)
- Structured reasoning & output (JSON)
- Document retrieval (RAG)
- Step‑by‑step planning (Groq)
Each stage has its own important role. This made development slower and more difficult at first, but it also resulted in a far more reliable product.
Another challenge was forcing the model’s output into a strict JSON schema instead of free‑form text. The early attempts produced many doubts and failures, but we soon realized that this constraint was essential. It allowed us to track state, reason about safety, and explain why the system made a particular recommendation.
Overall, the biggest challenge was choosing correctness and trust over speed and simplicity. Building a system for people means being careful, even when it’s inconvenient.
Accomplishments that we’re proud of

- Live vision‑first assistance – Users can simply point their phone camera at the problem and receive real‑time guidance.
- Safety‑first design – Structured JSON outputs let us enforce safety constraints and abort when a task is deemed hazardous.
- Grounded answers – RAG ensures every recommendation is backed by vetted repair documentation.
- Transparent pipeline – The backstage viewer lets developers and users see exactly how the system arrived at its advice.
- Scalable architecture – Decoupled components (vision, retrieval, planning, state) make it easy to swap models or add new knowledge sources.
HandyDaddy demonstrates how combining vision, structured reasoning, and retrieval‑augmented generation can turn a daunting home‑repair problem into a manageable, guided experience—just like having a knowledgeable dad on a video call.

We’re most proud of the complete full‑cycle architecture we built and how it works in real time. HandyDaddy doesn’t just analyze a single image; it reacts, updates, and guides users step‑by‑step based on what it sees **LIVE**. This makes the experience feel personal and practical, not theoretical.
The live feedback loop is something we genuinely find useful and are proud of. Seeing the system detect a situation, assess risk, and immediately guide the next safe action feels like a full circle—something we would actually want to use in our college dorm starting tomorrow.
We’re also proud that the system is transparent. Every decision, from vision detection to document‑based guidance, can be traced and inspected. That clarity gives us confidence that the system isn’t guessing, and it helps us improve it faster.What we learned

- The world is full of problems, but time is always limited. That tension makes building things exciting. Staying up late (sometimes sleeping less than a minute), debugging one line at a time, and watching the system come together was genuinely fun and meaningful for us.
- None of us had designed a full AI pipeline from scratch before. Reading research papers, watching YouTube videos, and experimenting with different approaches taught us far more than we expected. We learned not just how models work, but how systems work, and how small design decisions affect trust, safety, and usability.
- Most importantly, we realized how powerful it feels to build something that could help many different people: college students, families, and even older adults. That thought made every long night feel worth it.
What’s next for HandyDaddy
- Synchronize voice and image inputs – Right now, HandyDaddy supports image analysis and speech input, but they are processed separately. Because image capture and speech updates trigger different state resets in the frontend, true simultaneous submission is not fully solved yet.
- Combine the streams – Our next step is to capture voice and image together as a single input, so the system can understand not just what it sees, but what the user is saying at that exact moment. Solving this will make HandyDaddy feel much more natural and human.
- Expand scenario coverage – Beyond multimodal input, we want to handle more household scenarios while keeping the same core principle: complex reasoning, grounded and verified knowledge, and real usefulness for real people.