Version Your Cache Keys or Your Rolling Deployments Will Break
Source: Dev.to
Overview
Rolling deployments are designed to let multiple versions of a service run at the same time without downtime. Most teams think about compatibility at the API and database layers, but there’s another place where versions quietly interact: the cache.
We ran into this during a production rollout, and the fix turned out to be simpler than the incident itself.
The Incident
A production deployment started failing partway through the rollout.
- Deserialization errors appeared in the logs
- Request latency increased
- Error rates climbed
The change that triggered it was small: we renamed a single field in a model class.
This was a backward‑incompatible change. In general, such changes should be avoided, but sometimes they’re unavoidable — especially when consuming schemas owned by other teams or external systems.
We made the required changes to ensure downstream services would not break, and we updated our integration tests so they would pass. There were no API contract changes and no database migrations. From the perspective of our external dependencies, the change appeared safe.
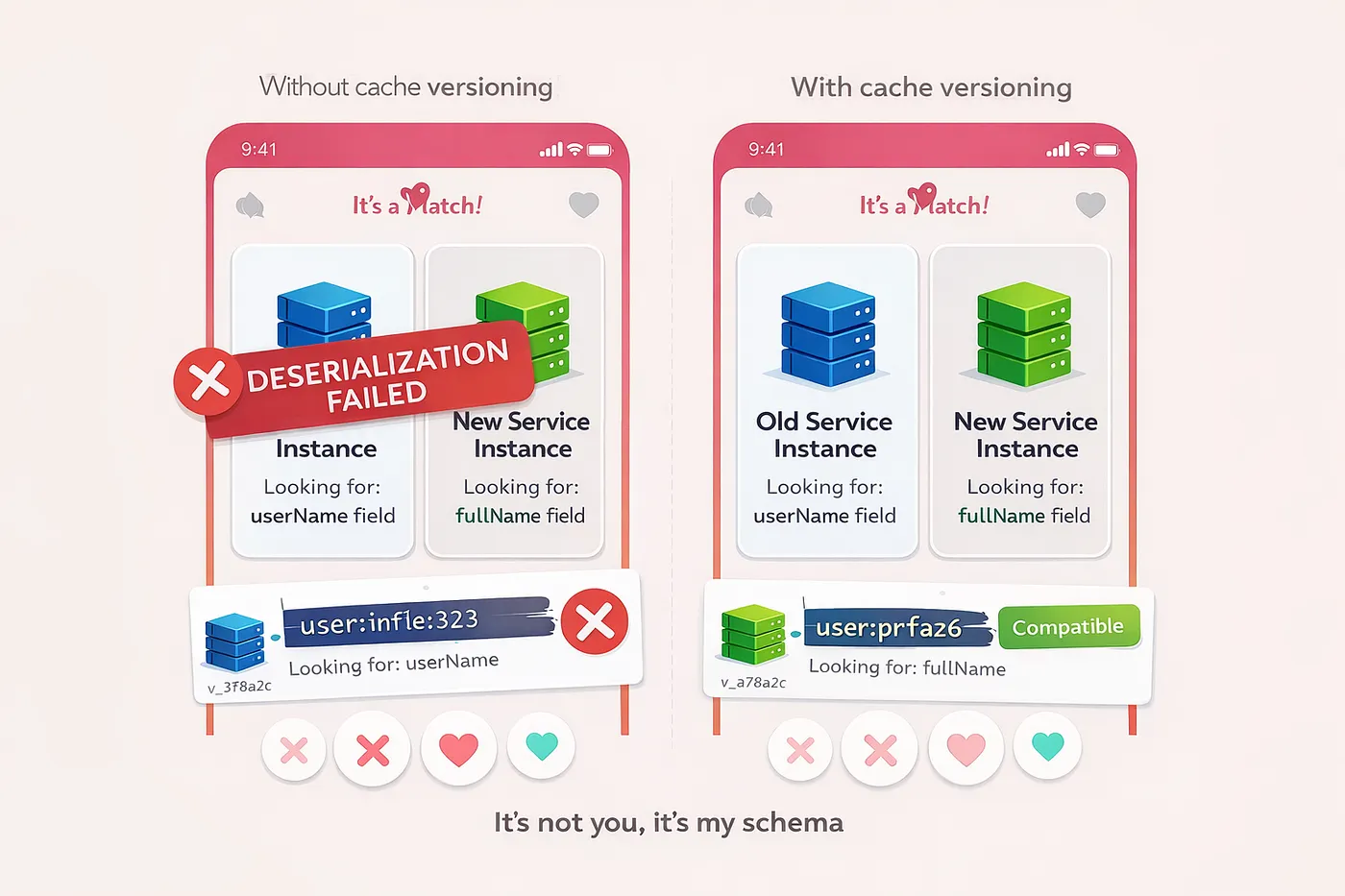
What we didn’t anticipate was the cache.
The service was a data aggregator. It consumed upstream data, enriched it, and published results downstream. It didn’t own persistent storage. But during the rolling deployment, with two versions of the service running simultaneously, new instances couldn’t deserialize cached data written by old instances — and old instances failed on data written by the new ones.
This wasn’t something our integration tests caught. The issue only emerged during the rollout, when multiple service versions were alive at the same time.
The failure wasn’t in our APIs, database layer, or downstream dependencies.
It was in the shared cache.
When This Problem Exists (and When It Doesn’t)
The issue doesn’t apply to every architecture.
If your cache is:
- Local
- In‑memory
- Scoped per instance or per host
then each service version only sees data it wrote itself, and schema changes are naturally isolated.
The problem appears only when all of the following are true:
- The cache is shared or distributed (Redis, Memcached, etc.)
- Multiple service versions run simultaneously
- Those versions read and write the same cache entries
In other words: rolling deployments + shared cache.
If that’s your setup, this failure mode isn’t rare — it’s inevitable.
What Actually Went Wrong
Most teams treat cache as an internal optimization. But a shared cache is shared state, and shared state between independently deployed versions is effectively a contract.
During a rolling deployment, the cache outlives any single service version. Old code and new code both interact with it at the same time.
Simplified Timeline
14:23:01 - Deployment starts, new instances come up
14:23:15 - Old instance writes: {"userId": 123, "userName": "alice"}
14:23:18 - New instance reads same key, expects: {"userId": 123, "fullName": "alice"}
14:23:18 - Deserialization fails
14:23:19 - New instance writes: {"userId": 456, "fullName": "bob"}
14:23:20 - Old instance reads same key, expects: {"userId": 456, "userName": "bob"}
14:23:20 - Deserialization failsRenaming a field introduced a breaking change — not at the API layer, but at the cache layer.
Why Common Alternatives Don’t Scale Well
When this happens, teams usually consider one of the following:
- Pausing or draining traffic during deploys
- Flushing the entire cache
- Coordinating tightly timed releases across teams
All of these can work, but they add operational overhead and reduce deployment flexibility. They also don’t scale well as systems and teams grow.
We wanted a solution that made rolling deployments boring again.
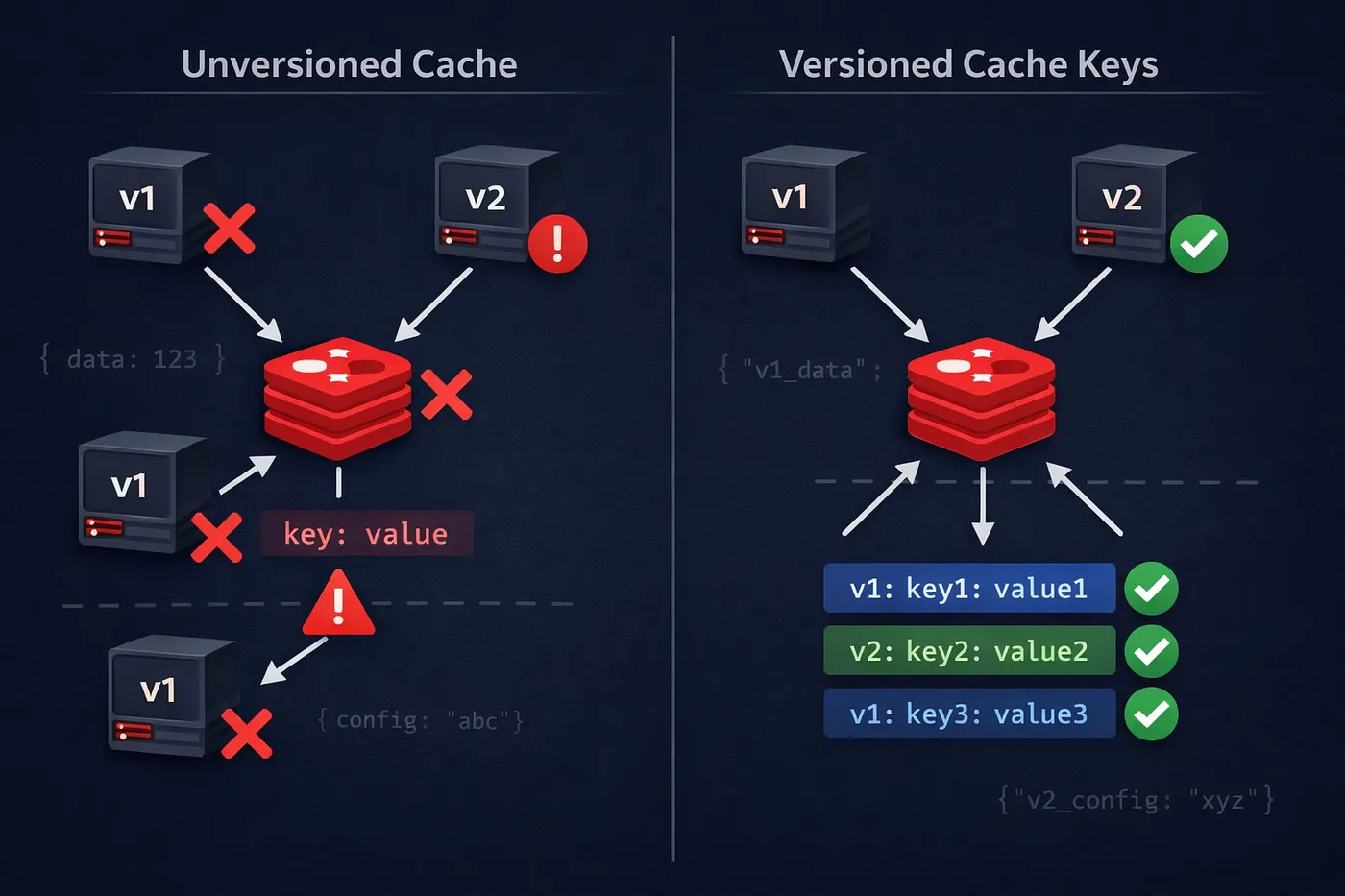
The Solution: Version Your Cache Keys
Instead of using cache keys like this:
user:123we added an explicit version prefix:
v1:user:123
v2:user:123Each service version reads and writes only the keys that match its own version.
That’s it.
How We Calculate the Cache‑Key Version
One open question with cache‑key versioning is how to manage the version itself.
Hard‑coding version numbers or manually bumping them works, but it’s easy to forget and adds process overhead. We wanted versioning to be automatic and transparent.
Our approach derives the version directly from the structure of the model class being cached:
- Inspect the model class using reflection.
- Extract its structural shape:
- Field names
- Field types
- Nested objects (recursively)
- Create a canonical representation of that shape.
- Compute a hash of the representation.
- Use the hash as the version identifier for cache keys.
Because the version is tied to the actual data schema, any change (e.g., renaming a field, adding/removing a field, changing a type) automatically produces a new version, eliminating the risk of human error.
Takeaways
- A shared cache becomes a contract between service versions during rolling deployments.
- Unversioned cache keys can cause deserialization failures when schemas evolve.
- Simple key versioning (
v1:…,v2:…) isolates each version’s data. - Deriving the version from the model’s structure makes the process automatic and fail‑proof.
By treating the cache as a versioned contract, rolling deployments stay smooth, and teams regain the freedom to iterate without costly coordination.
Fix for the Cache Key
Because the version is derived from the model structure:
- Any structural change (renamed field, type change, added or removed field) produces a new version.
- If nothing changes in the model, the version remains the same.
- Version bumps happen automatically and only when needed.
The version is per model class, not global. Each cached model evolves independently.
Conceptually, the cache key looks like this:
<version>:<model>:<id>This gives us transparent version bumps on any model‑structure change, without requiring developers to remember to update cache versions during refactors.
Example (Java)
Below is a simplified example showing how to derive a stable hash from a class structure using reflection:
import java.lang.reflect.Field;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.util.*;
import java.util.stream.Collectors;
public class RecursiveCacheVersioner {
public static String getVersion(Class<?> rootClass) {
// Use a Set to prevent infinite recursion on circular dependencies
String schemaBuffer = buildSchemaString(rootClass, new HashSet<>());
return hashString(schemaBuffer);
}
private static String buildSchemaString(Class<?> clazz, Set<Class<?>> visited) {
// Base case: if we've seen this class or it's a basic type, just return the name
if (isSimpleType(clazz) || visited.contains(clazz)) {
return clazz.getCanonicalName();
}
visited.add(clazz);
StringBuilder sb = new StringBuilder();
sb.append(clazz.getSimpleName()).append("{");
// Sort fields to ensure the hash is deterministic
List<Field> fields = Arrays.stream(clazz.getDeclaredFields())
.sorted(Comparator.comparing(Field::getName))
.collect(Collectors.toList());
for (Field field : fields) {
sb.append(field.getName()).append(":");
// RECURSIVE STEP: if the field is another model, get its structural string too
sb.append(buildSchemaString(field.getType(), visited));
sb.append(";");
}
sb.append("}");
return sb.toString();
}
private static boolean isSimpleType(Class<?> clazz) {
return clazz.isPrimitive()
|| clazz.getName().startsWith("java.lang")
|| clazz.getName().startsWith("java.util");
}
private static String hashString(String input) {
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte[] hash = digest.digest(input.getBytes(StandardCharsets.UTF_8));
// Java 17+ native hex formatting
return HexFormat.of().formatHex(hash).substring(0, 8);
} catch (Exception e) {
return "default";
}
}
}What the generator sees:
For a User class with an Address object, the builder generates a canonical string like this:
User{address:Address{city:String;zip:String;};id:int;name:String;}This string is then hashed to create the version prefix.
Note on Language Support
This approach works best in strongly‑typed languages where type information is available at runtime (e.g., Java, Kotlin, C#). Reflection makes it possible to reliably inspect model structure and derive a stable version from it.
In more dynamic languages like JavaScript, where runtime type information is limited or implicit, the same technique may require a different approach—such as explicitly defined schemas, schema versioning, or build‑time code generation. The underlying idea still applies, but the implementation details will differ.
Note on Performance
Cache‑key versions are computed once per model class at service startup, not on every cache read or write. This keeps runtime overhead negligible and ensures that cache operations remain as fast as before. Version calculation is part of initialization; steady‑state request handling stays unaffected.
Why This Approach Works Well
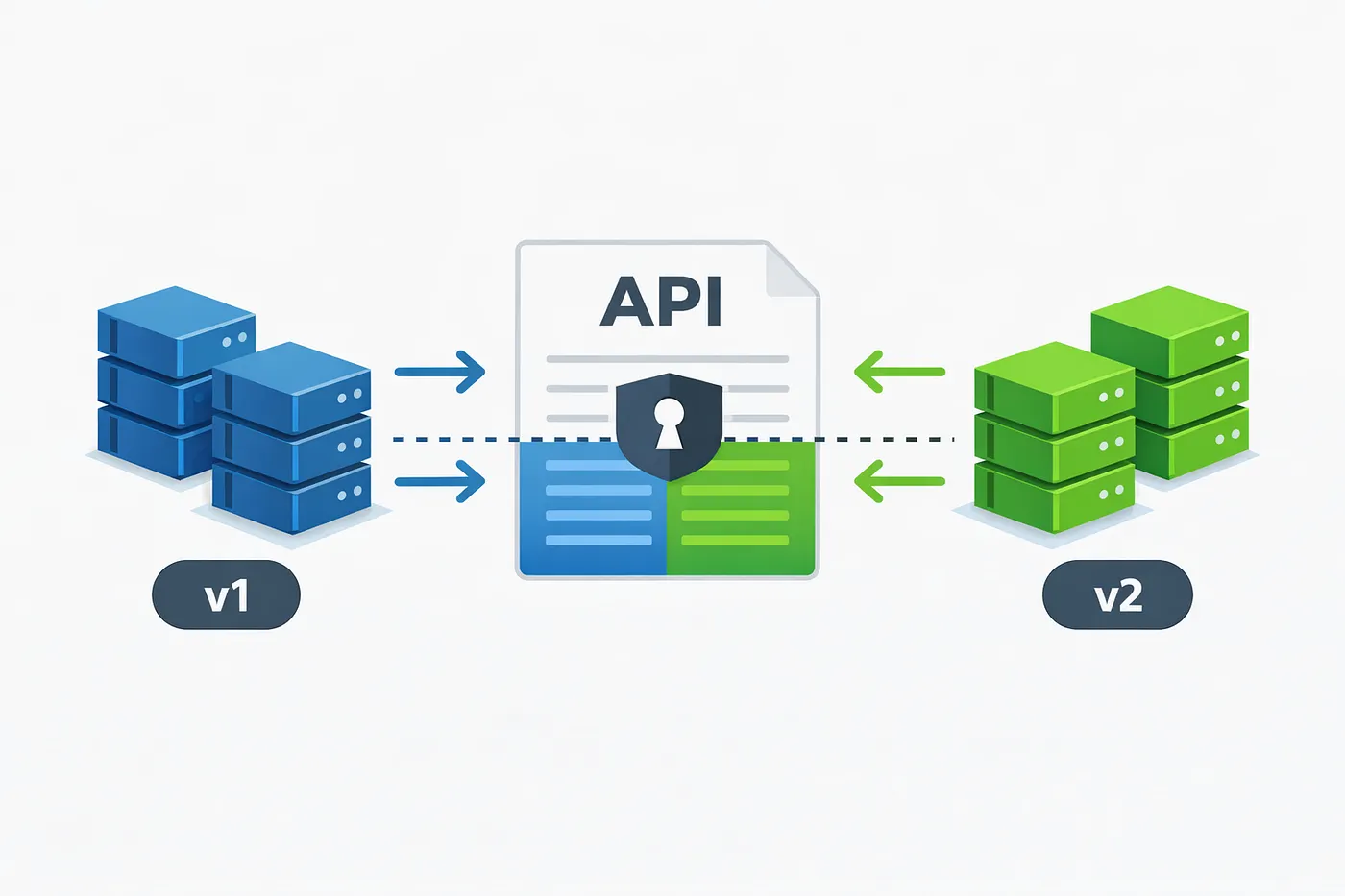
Versioning cache keys allows old and new service versions to safely coexist during a rolling deployment. Each version reads and writes only the data it understands, so incompatible representations never collide.
Consequences
- No cache flushes are required during deployments.
- No coordination with other teams is needed.
- Breaking schema changes are isolated by version.
- Old and new versions can run side‑by‑side without errors.
Because versions are derived automatically from the model structure, there’s no manual version management. Refactors that change the model naturally invalidate incompatible cache entries, while compatible changes don’t cause unnecessary cache churn.
Once the deployment completes, older versions stop accessing the cache and their entries expire naturally according to TTL. The cache no longer forces compatibility between versions that were never meant to be compatible.
When This Approach Is Especially Useful
Cache‑key versioning is particularly effective when:
- You use shared caches across multiple service instances.
- You deploy frequently using rolling updates.
- You don’t fully control upstream schemas.
- You operate aggregator or micro‑service architectures where different services may evolve independently.
Middleware Services
In our case, it allowed upstream provider teams to make changes without coordinating cache behavior with us, while keeping deployments safe on our side.
Trade‑offs and Limitations
Like most architectural decisions, cache‑key versioning comes with trade‑offs that are worth understanding upfront.
Multiple Versions in the Cache
During a rolling deployment, multiple versions of the same logical object can exist in the cache at the same time. In our case, deployments take around 15 minutes. With a 1‑hour TTL, this resulted in roughly double the cache entries for a short period.
Higher Temporary Cache Usage
This approach trades memory for safety. For us, the impact was small: cache utilization increased from ~45 % to ~52 % during deployments and returned to normal once older entries expired.
Not Suitable for Every Environment
If cache memory is extremely constrained, or if your system requires strict cross‑version consistency during deployments, this approach may not be a good fit.
Intentional Cache Misses During Transitions
New versions will miss the cache on first access and recompute values. This is expected and intentional—it’s safer than attempting to deserialize incompatible data. Cache TTLs and the cache‑miss path should be designed accordingly.
What you gain: safer rolling deployments, simpler operational behavior, and reduced risk during schema changes.
What you give up: some cache efficiency during deployments.
For us, that trade‑off was well worth it.
A Better Mental Model for Caches
Caches are often treated as implementation details. In reality, a shared cache is part of your system’s runtime contract.
If multiple versions of a service can read and write the same cached data, then cache compatibility matters just as much as API or storage compatibility.
Versioning cache keys makes that contract explicit.
Final Takeaway
If you’re doing rolling deployments and using a shared cache:
Version your cache keys by default.
It’s a small change with a large impact on reliability, and it keeps deployments predictable as systems evolve.