Using LMAX Disruptor to build a high-performance in-memory event broker in Java.
Source: Dev.to
Introduction
I spend most of my time writing Python code for data analysis, engineering, filesystem operations, and web projects, with some Go thrown in because its concurrency model feels simpler—or Rust for novelty. I started programming with C and learned OOP through Java back in the day. After seven years away from the JVM, I got curious about what’s changed and decided to dive back in by building something performance‑critical. The result is an event router that processes 7 + million dispatches per second on a laptop by eliminating the two main bottlenecks: locks and memory allocation.
Why Java when Python and Go exist?
As a Python developer, I’d typically reach for libraries like PyPubSub or Blinker for event handling. They work well for I/O‑bound applications but struggle with CPU‑intensive event processing due to the GIL (for Python versions before 3.14).
Go’s channel‑based concurrency model handles events elegantly with goroutines, and libraries like EventBus provide a pub‑sub pattern that feels natural in Go’s ecosystem. However, neither ecosystem has a direct equivalent to the Disruptor’s mechanical‑sympathy approach.
- Python’s interpreter overhead and Go’s garbage collector (though better than Python’s) both introduce latency that becomes visible at millions of events per second.
- If you’re building a system where a few microseconds per event multiplied by millions actually matters (financial systems, real‑time analytics, game servers), Java’s mature JIT compilation, fine‑tuned GC options, and libraries like Disruptor—which exploit CPU cache behavior—offer performance that’s hard to match.
Typical Event Bus Based on Locks
A typical event bus uses queues wrapped in synchronized blocks. When thread A wants to publish an event, it:
- Locks the queue.
- Adds the event.
- Unlocks the queue.
Thread B performs the same steps. At high throughput, threads spend more time waiting for locks than doing actual work.
Problems
- Lock contention – Frequent lock/unlock cycles become a bottleneck.
- CAS overhead – Even Java’s
ConcurrentLinkedQueuerelies on compare‑and‑swap operations, which introduce memory barriers and additional latency. - Object allocation – Creating a new
Eventinstance for every message generates a lot of garbage. With millions of events per second, the garbage collector runs constantly, causing noticeable pauses.
The Ring Buffer
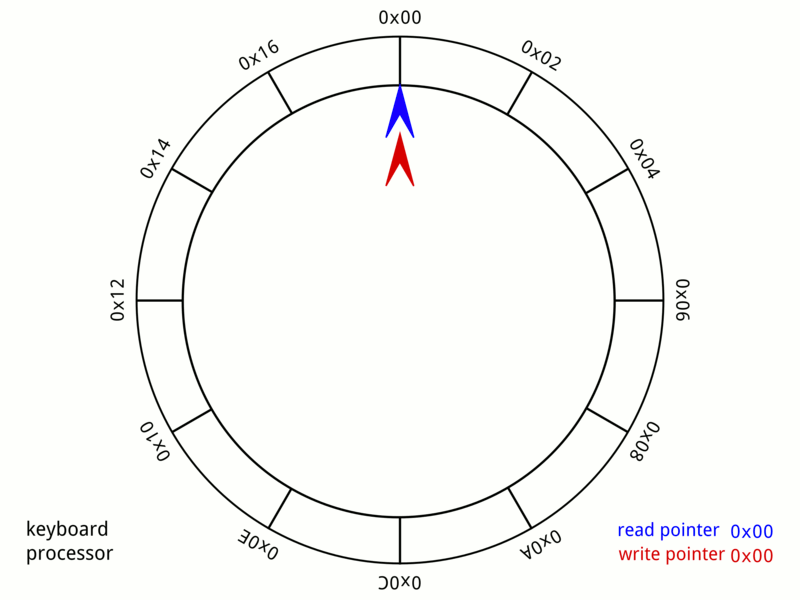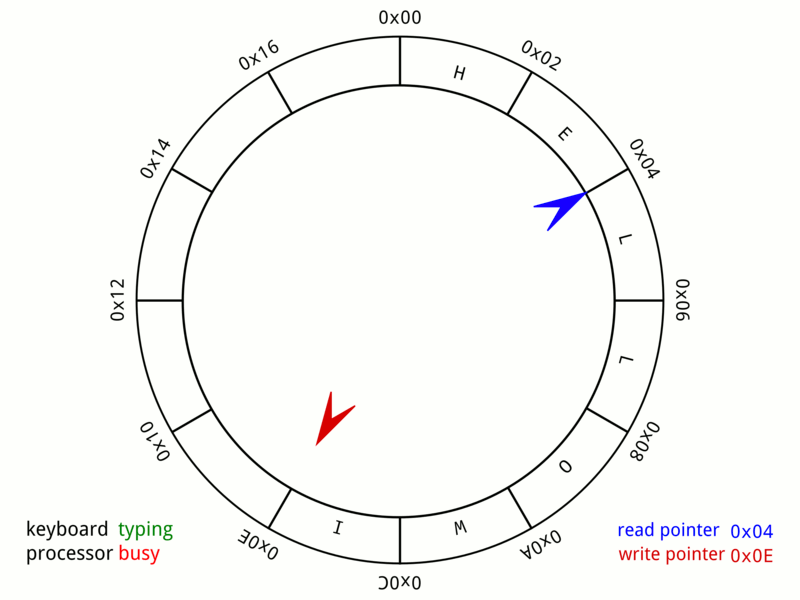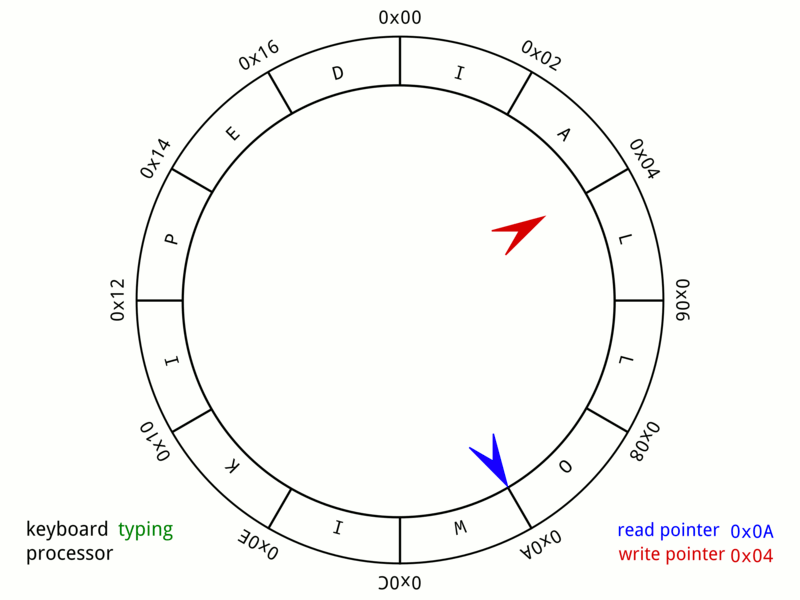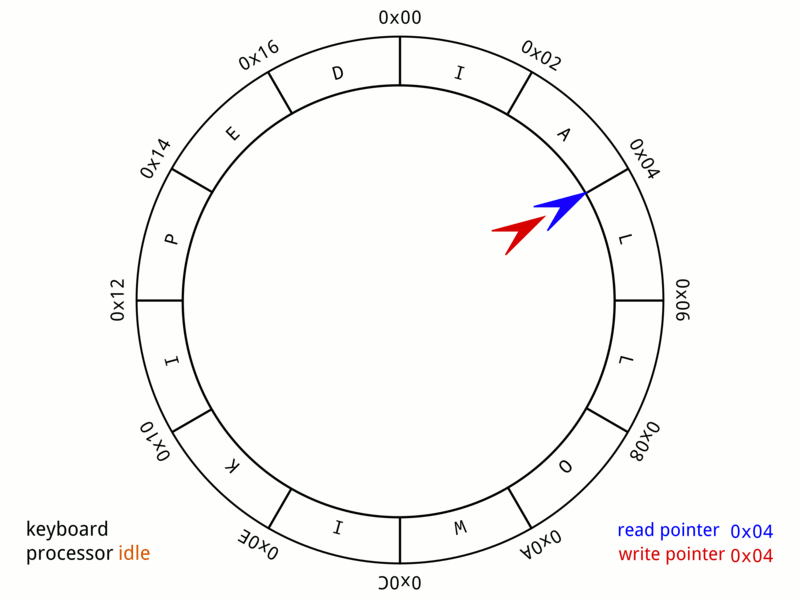
Disruptor is essentially a very well‑tuned application of the circular buffer data structure—a fixed‑size array that wraps around to reuse slots. Anyone who’s studied data structures and algorithms has likely encountered this pattern, but Disruptor optimizes it specifically for multi‑threaded event processing with lock‑free mechanics.

Source: Wikipedia – Circular Buffer Animation
{kind=link}
Picture a circular array of 16 384 pre‑allocated Event slots. Publishers claim the next available slot, write their data directly into it, and mark it ready.
- No locks.
- No allocations.
- Only atomic sequence numbers coordinate who writes where.
When a producer publishes, it calls ringBuffer.next() to claim a sequence number, copies data into ringBuffer.get(sequence), and finally calls ringBuffer.publish(sequence). By “copying” we mean setting the attributes of the existing Event instance—no new object is created.
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import org.jetbrains.annotations.NotNull;
/**
* A router is an event bus for subscribers to attach to and receive relevant events.
*/
public class EventRouter {
private final @NotNull Disruptor disruptor;
private final @NotNull RingBuffer ringBuffer;
/**
* Publish an event in the event bus.
*/
public void publish(@NotNull Event e) {
long sequence = this.ringBuffer.next();
try {
// The Event class has custom attributes: type, from, payload, timestamp.
Event bufferedEvent = ringBuffer.get(sequence);
bufferedEvent.setType(e.getType());
bufferedEvent.setFrom(e.getFrom());
bufferedEvent.setPayload(e.getPayload());
bufferedEvent.setTimestamp(e.getTimestamp());
} finally {
this.ringBuffer.publish(sequence);
}
}
}The consumer sees published sequences and processes them in order.
Dispatch Strategy
Once an event is placed in the ring buffer, the router dispatches it to all registered subscribers. Each event type maintains a subscriber list so the router can quickly locate the listeners that are interested in that type. When an event arrives, the router:
- Looks up the subscriber list for the event’s type.
- Submits a dispatch task to a thread‑pool for each subscriber.
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.jetbrains.annotations.NotNull;
/**
* Thread pool for dispatching events to subscribers.
* The pool size matches the number of available CPU cores, keeping the CPU busy
* without oversubscribing.
*/
private final ExecutorService DISPATCH_POOL =
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
/**
* Dispatch an event to all its subscribers.
*
* @param e the event to dispatch
* @param sequence the sequence number of the event in the ring buffer
*/
private void dispatch(@NotNull Event e, long sequence) {
// Retrieve the list of subscribers for the event's type.
List<Subscriber> subs = subscriberMap.get(e.getType());
if (subs == null || subs.isEmpty()) {
return; // No one is interested.
}
// Submit a dispatch task for each subscriber.
for (Subscriber sub : subs) {
DISPATCH_POOL.submit(() -> sub.handle(e, sequence));
}
}- Thread‑pool sizing –
Runtime.getRuntime().availableProcessors()ensures the pool has exactly as many threads as CPU cores, avoiding unnecessary context switches. - Zero‑allocation dispatch –
Eventobjects are pre‑allocated and reused, so dispatching only involves method calls and minimal bookkeeping, producing no additional garbage.
Conclusion
By combining a lock‑free ring buffer (the Disruptor pattern) with a lightweight dispatch thread pool, we eliminate the two primary performance killers of traditional event buses:
- Locking contention
- Excessive object allocation
The result is an event router capable of handling 7 + million dispatches per second on a modest laptop, proving that Java still has a compelling place in the high‑throughput, low‑latency world alongside Python and Go.
// See section “Copy‑on‑Write subscribers”
public void onEvent(Event e, boolean endOfBatch) {
SubscriberList holder = this.subscribers.get(e.getType());
if (holder == null) return;
var subs = holder.list;
if (subs.isEmpty()) return;
if (subs.size() == 1) {
subs.getFirst().onEvent(e);
} else {
for (Subscriber sub : subs) {
DISPATCH_POOL.submit(() -> sub.onEvent(e));
}
}
}The thread‑pool size matches the number of CPU cores. This parallelises subscriber callbacks across multiple threads while keeping the main ring‑buffer processing single‑threaded and fast.
Each subscriber has its own single‑threaded executor (onEvent) that queues incoming events. This preserves ordering per subscriber (event A always processes before event B if A was published first) while preventing one slow subscriber from blocking others.
/**
* A subscriber listens to a given number of event types in his scope's range.
*/
public abstract class Subscriber implements AutoCloseable {
/**
* This executor ensures events are processed one at a time, in the order they are received,
* without blocking the event router.
*/
@NotNull
private final ExecutorService exec = Executors.newSingleThreadExecutor();
/**
* Return the scope of this subscriber.
*/
@NotNull
public abstract Scope scope();
/**
* Process an event received from a router.
*/
protected abstract void processEvent(@NotNull Event e);
/**
* Send data to this subscriber. This is fast and does not block the caller.
*/
public final void onEvent(@NotNull Event e) {
this.exec.submit(() -> this.processEvent(e));
}
@Override
public void close() throws TimeoutException, InterruptedException {
this.exec.shutdown();
if (!this.exec.awaitTermination(1, TimeUnit.MINUTES)) {
throw new TimeoutException("subscriber's executor thread termination timed out");
}
}
}Choosing a WaitStrategy
Disruptor offers several wait strategies that control how consumers behave when no new events are available.
| Strategy | Behaviour |
|---|---|
BlockingWaitStrategy | Uses locks; CPU‑friendly but adds latency. |
BusySpinWaitStrategy | Spins tightly; lowest possible latency but consumes 100 % CPU. |
SleepingWaitStrategy | Backs off progressively; balances CPU usage with reasonable latency. |
YieldingWaitStrategy | Calls Thread.yield() when idle; sits in the middle ground—low latency without full spin. |
I chose YieldingWaitStrategy because it provides low latency while avoiding wasteful CPU usage during idle periods. For a system that processes bursts of events with occasional quiet moments, yielding gives good throughput without pinning the CPU.
Additional Features of This Experimental Event Bus
Scope‑Based Security
Events have four scope levels:
| Scope | Visibility |
|---|---|
PUBLIC | Visible to remote actors |
FEDERATED | Visible to trusted servers |
PRIVATE | Visible to local trusted actors |
ROOT | Full access |
A component may interact only with events whose scope is at or below its own scope level.
- Registration – When an event type is registered, its scope must be specified.
- Subscription – The router checks that the subscriber’s scope is broad enough for the requested event type.
- Publishing – The router verifies that the event type exists before dispatching.
The EventRegistry stores registered events and their scopes in a ConcurrentHashMap. A lookup is a single hash‑table read, adding only microseconds of overhead.
Copy‑on‑Write Subscribers
Each event type maps to a SubscriberList that holds an immutable List. When a new subscriber registers, the router creates a new list containing the additional subscriber and swaps it in atomically.
- Readers see a consistent snapshot without any synchronization.
- Writers pay the cost of copying the list, but subscriptions are rare compared with dispatches.
This design optimises the hot path (dispatch) at the expense of the cold path (subscribing).
Benchmark Results
The benchmark spawns 4 producer threads, each publishing 250 000 events across 5 event types. Each type has 4 subscribers, resulting in 4 M total dispatch operations (1 M events × 4 subscribers each).
| Machine | Avg. Time (50 runs) | Dispatches / sec |
|---|---|---|
| Intel Core i7‑13600H, 16 GB RAM | 922 ms | 4.34 M |
| Intel Core Ultra 7‑155H, 32 GB RAM | 528 ms | 7.58 M |
The numbers were obtained with lightweight string payloads and subscribers that simply increment a counter. Real‑world throughput depends on what subscribers actually do with the events, but the router itself adds minimal latency. The Disruptor library is advertised to achieve even higher performance.
What This Experimental Event Bus Does Not Do
- No filtering beyond the event type.
- No wildcards, content‑based routing, or priority queues.
- No guaranteed delivery – if a subscriber falls too far behind and the ring buffer wraps, old unprocessed events are overwritten.
- The default ring buffer holds 16 K slots; being more than 16 K events behind can cause loss.
- No persistence – events exist only in memory. A process crash discards any in‑flight events. This is an in‑process event bus, not a durable message queue like Kafka.
- No back‑pressure – the single‑threaded executor per subscriber means slow subscribers build up queues; publishers are not throttled when consumers can’t keep up.
To Conclude
Disruptor was developed by LMAX, a trading platform that aims to be the “fastest trading platform in the world”. It demonstrates how a carefully engineered ring‑buffer can provide ultra‑low‑latency, high‑throughput event processing in a single‑process environment. This experimental bus showcases a practical, scoped, copy‑on‑write implementation built on top of that foundation, while also highlighting the trade‑offs and missing features that would be required for a production‑grade messaging system.
The code is available on GitHub.