Understanding Change Data Capture with Debezium
Source: Dev.to
Moving data between systems sounds simple – until it isn’t
As applications grow, teams quickly realize that copying data from one database to another reliably is much harder than it looks. Updates get missed, deletes are hard to track, and systems slowly drift out of sync.
This is where Change Data Capture (CDC) comes in.
In this post I’ll walk through what CDC is, why traditional approaches break down, and how Debezium captures data changes in a fundamentally different way.
How data is usually moved today (and why it fails)
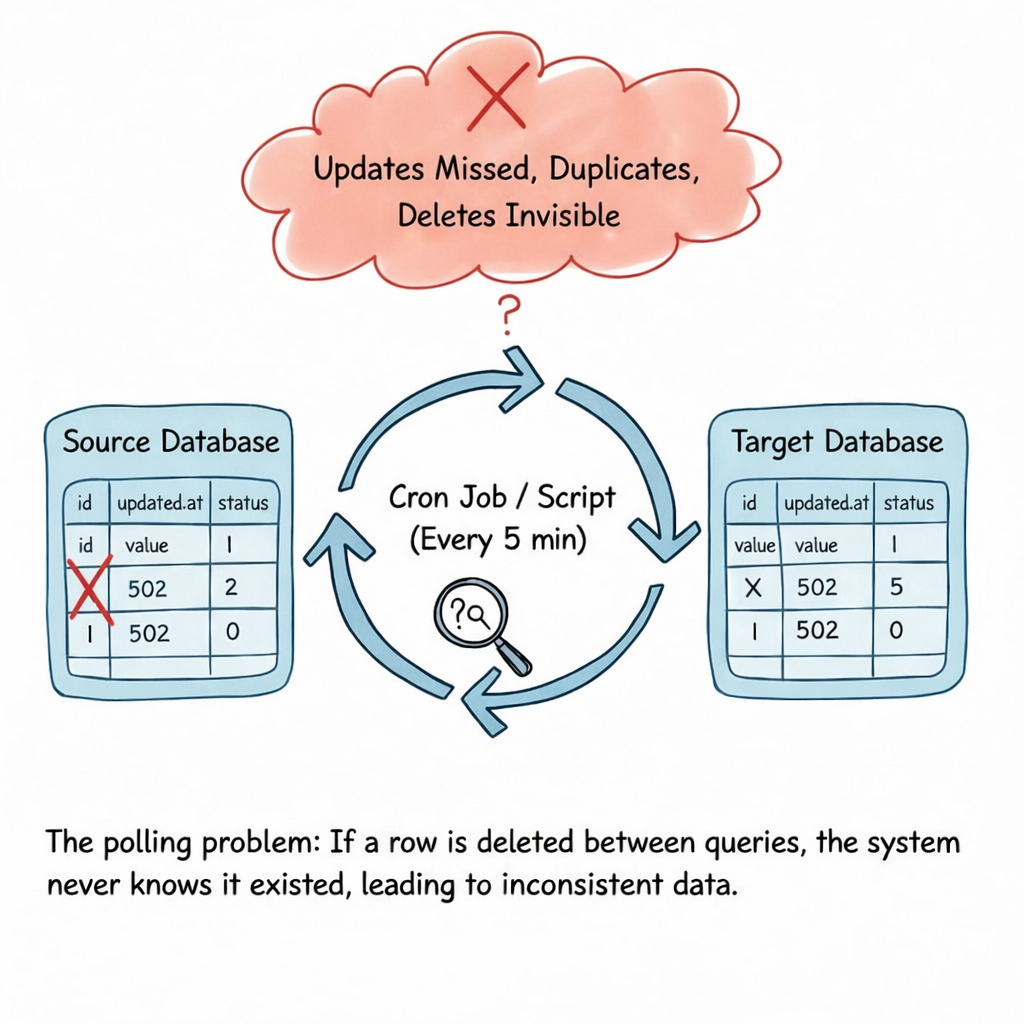
In many systems, data is moved by periodically querying a database for new or updated rows.
A common pattern looks like this:
- Run a job every few minutes
- Query rows where
updated_at > last_run_time - Copy the result downstream
- Repeat
At first this feels reasonable – it’s easy to implement and works fine at small scale.
But as systems grow, cracks start to appear.
Problems with this approach
- Missed updates when timestamps overlap
- Duplicate data when jobs retry
- Deletes are invisible unless handled manually
- High load on production databases
- Lag between when data changes and when consumers see it
This approach is commonly known as polling, and it breaks down fast under real‑world conditions.
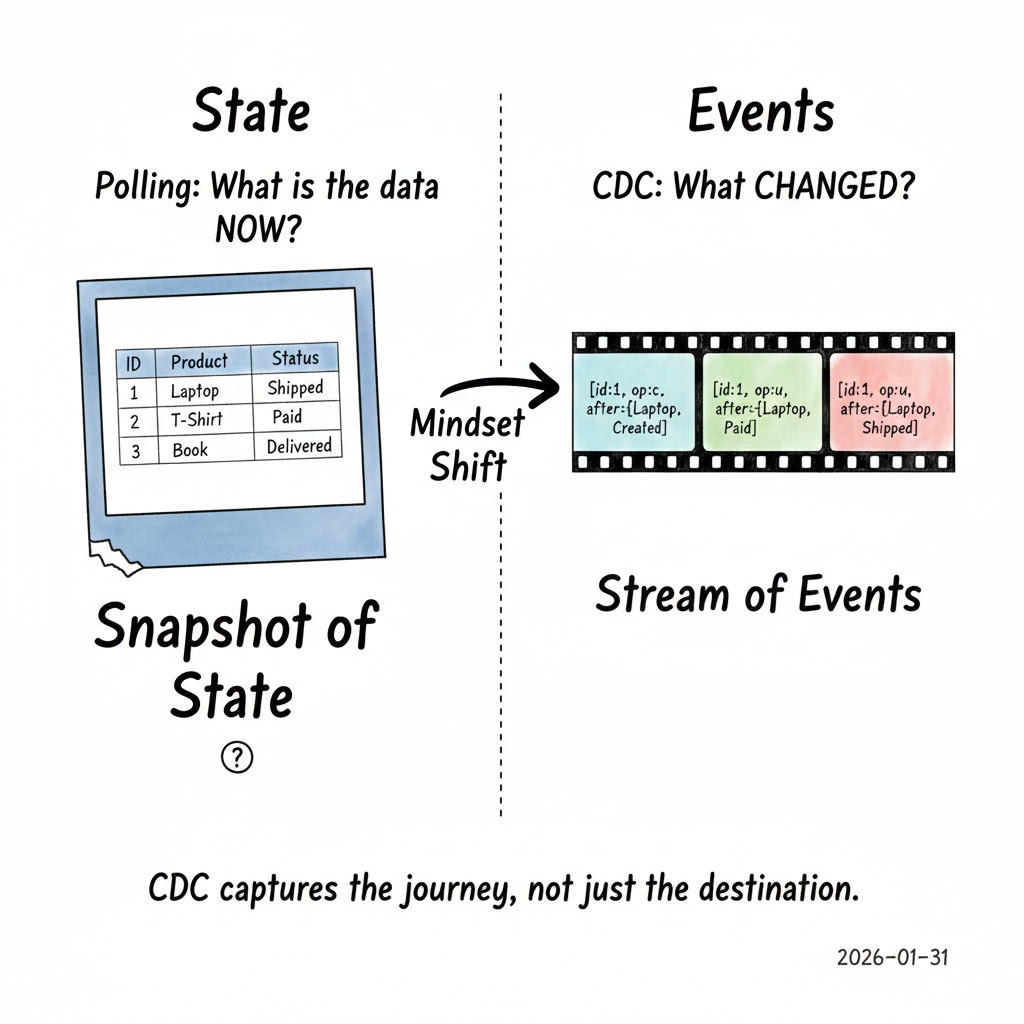
What is Change Data Capture (CDC)?
Instead of repeatedly asking:
“What does the data look now?”
CDC asks a different question:
“What changed?”
CDC treats inserts, updates, and deletes as events, not as rows in a snapshot.
The key insight is that databases already record every change internally – CDC simply listens to those records. This makes CDC fundamentally different from polling.
Introducing Debezium
Debezium is an open‑source platform for implementing Change Data Capture.
At a high level:
- Debezium captures changes from databases
- Converts them into events
- Publishes them to Apache Kafka
One important thing to understand early:
Debezium does not query tables.
It reads database transaction logs.
This single design choice is what makes Debezium powerful.
How Debezium actually captures changes
Every relational database maintains an internal log:
| Database | Log name |
|---|---|
| PostgreSQL | WAL (Write‑Ahead Log) |
| MySQL | Binlog |
| SQL Server | Transaction Log |
These logs exist so databases can:
- Recover from crashes
- Replicate data
- Ensure consistency
Debezium taps into these logs.
The flow looks like this
- An application writes data to the database
- The database records the change in its transaction log
- Debezium reads the log entry
- The change is converted into an event
- The event is published to a Kafka topic
No polling. No guessing. No missed changes.
What does a CDC event contain?
A Debezium event usually includes:
before– the previous state of the rowafter– the new state of the rowop– the type of operation (c= create,u= update,d= delete)- Metadata such as timestamps and transaction IDs
Instead of representing state, CDC represents history. This is a subtle but powerful shift.
A real‑world example: order lifecycle events
Imagine a simple orders table in PostgreSQL.
What happens over time
| Action | Change |
|---|---|
| New order created | status = CREATED |
| Order paid | status changes CREATED → PAID |
| Order cancelled/completed | status changes again |
With polling you only see the latest state; deletes are often lost; intermediate transitions disappear.
With Debezium each change becomes an event, preserving the full lifecycle. Consumers can react in real time.
This makes CDC ideal for:
- Analytics
- Auditing
- Search indexing
- Cache invalidation
Where does Kafka fit in?
Kafka acts as the event backbone. Debezium publishes changes to Kafka topics, and multiple systems can consume them independently:
- One consumer updates a cache
- Another populates an analytics store
- Another writes data into a data lake
This decoupling is crucial for scalable architectures.
Where analytics systems come in (subtle but important)
Downstream systems can consume CDC events for analysis. For example, analytical databases like ClickHouse are often used as read‑optimized sinks, where:
- CDC events are transformed
- Aggregated
- Queried efficiently
In this setup:
- Debezium captures changes
- Kafka transports them
- Analytical systems focus purely on querying
Each system does one job well.
How CDC compares to other approaches
| Approach | Pros | Cons |
|---|---|---|
| Polling | Simple to implement | Fragile, inefficient, can miss data |
| Database triggers | Immediate capture | Invasive, hard to maintain, can impact performance |
| CDC via logs (Debezium) | Reliable, scalable, accurate | Requires additional infrastructure |
CDC isn’t magic – but it aligns with how databases actually work internally.
Trade‑offs to be aware of
Debezium is powerful, but not free of complexity. Consider:
- Kafka infrastructure is required
- Schema changes need careful planning
- Back‑filling historical data can be non‑trivial
- Operational visibility and monitoring are essential
CDC pipelines are systems, not one‑off scripts.
When does Debezium make sense?
Debezium is a good fit when you need:
- Near‑real‑time propagation of every data change
- Decoupled downstream consumers (analytics, caches, search, etc.)
- Strong guarantees that no updates or deletes are missed
- A scalable, fault‑tolerant architecture built around event streaming
If those requirements match your project, give Debezium a try!
When to use CDC
- You need near real‑time data movement
- Multiple systems depend on the same data
- Accuracy matters more than simplicity
When it may be overkill
- Data changes infrequently
- Batch updates are sufficient
- Simplicity is the top priority
Closing thoughts
Change Data Capture shifts how you think about data — from snapshots to events.
Debezium embraces this model by listening to the database itself, instead of repeatedly asking it questions. That difference is what makes CDC reliable at scale.
If you’ve ever struggled with missed updates, fragile ETL jobs, or inconsistent downstream data, CDC is worth understanding — even if you don’t adopt it immediately.