Top 8 Fal.AI Alternatives Developers Are Using to Ship AI Apps
Source: Dev.to
Why Look Beyond Fal.AI?
To be clear: Fal.AI is good at what it does. It focuses on:
- Fast inference
- Simple APIs
- Managed GPU access
But modern AI apps often need more than a single inference endpoint. They need orchestration, multi‑modal pipelines, global scale, and production reliability. That’s where alternatives start to make sense.
1. Hypereal AI

Hypereal positions itself as an infrastructure layer for AI apps, especially those dealing with rich media and real‑time interactions.

The core idea behind Hypereal is simple: developers should ship AI products, not manage GPUs. Everything from model routing to global inference is handled for you, so you can focus on building features instead of infrastructure.
Key highlights
- Unified neural interface for multiple AI modalities
- Built‑in orchestration across LLMs, diffusion, audio, and video models
- Adaptive inference with predictive auto‑scaling
- Sub‑50 ms latency paths optimized for real‑time use cases
- Dedicated AI compute using H100 and H200 tensor cores
- Curated catalog of production‑ready open‑source models
- REST APIs with real‑time streaming support
- Scale‑to‑zero with pay‑as‑you‑go pricing
Best suited for
- Teams building generative media products
- Real‑time avatars and digital humans
- Multi‑modal AI applications
- Products where AI is the core experience, not just a feature
2. Modal

Modal clicks instantly for Python developers. Write Python functions, attach compute resources, and let the platform handle scaling and execution.
Key highlights
- Python‑first development model
- Serverless execution for AI workloads
- Built‑in GPU support
- Automatic scaling based on demand
- Minimal gap between local code and production
Best suited for
- Python‑first teams
- Researchers moving models into production
- Small teams that value developer ergonomics
- Projects that need fast iteration over infrastructure control
3. RunPod

RunPod sits closer to the infrastructure side of the spectrum. It gives developers access to GPUs and lets them decide how much control they want.
Key highlights
- On‑demand and persistent GPU instances
- Support for custom containers
- Flexible pricing options
- Suitable for long‑running inference workloads
- Works well with self‑managed inference servers
Best suited for
- Teams comfortable managing deployments
- Developers optimizing GPU costs
- Custom‑engineered inference pipelines
Inference Setups
Workloads that don’t fit serverless execution models
4. AWS SageMaker
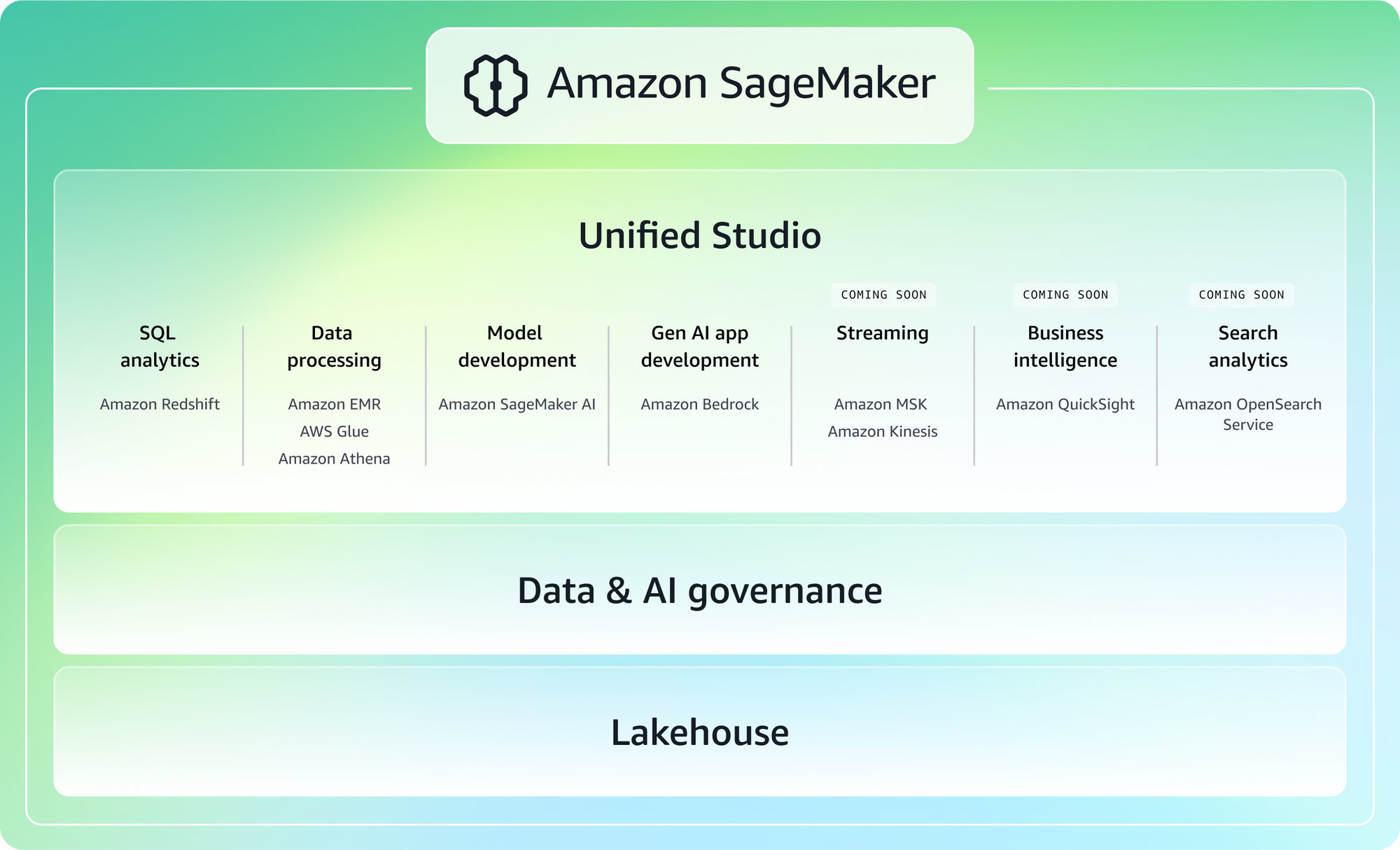
SageMaker is a big platform, designed to cover the entire machine‑learning lifecycle, from training to deployment to monitoring. It shows up most often in larger organizations or teams already deeply invested in AWS.
Key highlights
- End‑to‑end ML lifecycle management
- Managed training and inference
- Integration with AWS services
- Support for large‑scale ML workflows
- Strong focus on governance and security
Best suited for
- Enterprises already using AWS
- Teams with dedicated ML engineers
- Regulated or compliance‑heavy environments
- Organizations that need standardized ML pipelines
5. Google Vertex AI

Vertex AI provides a unified platform for building, training, and deploying machine‑learning models, with a strong emphasis on MLOps. It’s popular with teams that want structured workflows and long‑term maintainability.
Key highlights
- Unified training and inference platform
- Managed ML pipelines
- Strong MLOps tooling
- Deep integration with Google Cloud services
- Support for custom models and workflows
Best suited for
- Teams already on Google Cloud
- Organizations prioritizing MLOps
- Products with complex ML pipelines
- Long‑term, production‑focused ML systems
6. Hugging Face Inference Endpoints

If you’ve worked with open‑source models, you’ve almost certainly interacted with Hugging Face. Their inference endpoints make it easy to deploy models directly from the Hugging Face Hub.
Key highlights
- Direct deployment from Hugging Face Hub
- Support for popular transformer models
- Custom container options
- Simple API‑based access
- Familiar ecosystem for ML engineers
Best suited for
- Open‑source‑first teams
- Transformer‑heavy workloads
- ML engineers prototyping production APIs
- Teams already using Hugging Face models
7. Baseten

Baseten focuses heavily on the “production” side of AI inference. It’s built for teams that are shipping AI features to users and care deeply about reliability, latency, and observability.
Key highlights
- Production‑grade inference APIs
- Low‑latency model serving
- Built‑in observability
- Scalable deployment architecture
- Designed for real user traffic
Best suited for
- Product teams shipping AI features
- Applications with strict performance requirements
- Teams that need reliability at scale
- AI‑powered SaaS products
8. Self‑Hosted Inference (Kubernetes + GPUs)
Running everything yourself gives you full control, but also full responsibility. It’s not usually the first step, but for some teams it’s the right long‑term choice.
Key highlights
- Full ownership of infrastructure
- Custom scheduling and scaling
- No vendor lock‑in
- Works with Kubernetes and GPU nodes
- Highly customizable deployment pipelines
Best suited for
- Teams with strong DevOps and MLOps experience
- Regulated or security‑sensitive environments
- Organizations optimizing long‑term cost
- Products requiring full infrastructure control
How I’d Choose Between These Platforms
Instead of asking “Which one is better than Fal.AI?”, consider:
- Is AI a feature or the product?
- Do I need multi‑modal pipelines?
- How much infrastructure do I want to manage?
- What does scaling look like six months from now?
Different answers lead to different tools.
Final Thoughts
Fal.AI is still a solid choice for many use cases. But as AI products grow, infrastructure decisions start shaping what’s possible and what’s painful.
The platforms in this list reflect different philosophies around AI deployment. Some prioritize simplicity, others control, and others production‑scale orchestration. There’s no single “best” option, only what fits you.
If there’s one thing I’ve learned, it’s this:
The best AI platform is the one you won’t have to replace once your product actually takes off.