The path to ubiquitous AI (17k tokens/sec)
Source: Hacker News
Overview
Many believe AI is the real deal. In narrow domains it already surpasses human performance. Used well, it is an unprecedented amplifier of human ingenuity and productivity. Its widespread adoption is hindered by two key barriers: high latency and astronomical cost.
- Latency – Interactions with language models lag far behind the pace of human cognition. Coding assistants can ponder for minutes, disrupting a programmer’s flow and limiting effective human‑AI collaboration. Meanwhile, automated agentic AI applications demand millisecond latencies, not leisurely human‑paced responses.
- Cost – Deploying modern models demands massive engineering and capital: room‑sized supercomputers consuming hundreds of kilowatts, with liquid cooling, advanced packaging, stacked memory, complex I/O, and miles of cables. This scales to city‑sized data‑center campuses and satellite networks, driving extreme operational expenses.
Although society seems poised to build a dystopian future defined by data centers and adjacent power plants, history hints at a different direction. Past technological revolutions often started with grotesque prototypes, only to be eclipsed by breakthroughs yielding more practical outcomes.
Consider ENIAC: a room‑filling beast of vacuum tubes and cables. ENIAC introduced humanity to the magic of computing, but it was slow, costly, and unscalable. The transistor sparked swift evolution—through workstations and PCs, to smartphones and ubiquitous computing—sparring the world from ENIAC sprawl.
General‑purpose computing entered the mainstream by becoming easy to build, fast, and cheap.
AI needs to do the same.
About Taalas
Founded 2.5 years ago, Taalas developed a platform for transforming any AI model into custom silicon. From the moment a previously unseen model is received, it can be realized in hardware in only two months.
The resulting Hardcore Models are an order of magnitude faster, cheaper, and lower‑power than software‑based implementations.
Taalas’ work is guided by the following core principles:
1. Total specialization
Throughout the history of computation, deep specialization has been the surest path to extreme efficiency in critical workloads. AI inference is the most critical computational workload humanity has ever faced, and the one that stands to gain the most from specialization. Its computational demands motivate total specialization: the production of optimal silicon for each individual model.
2. Merging storage and computation
Modern inference hardware is constrained by an artificial divide: memory on one side, compute on the other, operating at fundamentally different speeds.
- Paradox – DRAM is far denser (and therefore cheaper) than the types of memory compatible with standard chip processes. However, accessing off‑chip DRAM is thousands of times slower than on‑chip memory. Conversely, compute chips cannot be built using DRAM processes.
This divide underpins much of the complexity in modern inference hardware, creating the need for advanced packaging, HBM stacks, massive I/O bandwidth, soaring per‑chip power consumption, and liquid cooling.
Taalas eliminates this boundary. By unifying storage and compute on a single chip at DRAM‑level density, our architecture far surpasses what was previously possible.
3. Radical simplification
By removing the memory‑compute boundary and tailoring silicon to each model, we were able to redesign the entire hardware stack from first principles. The result is a system that does not depend on difficult or exotic technologies—no HBM, advanced packaging, 3‑D stacking, liquid cooling, or high‑speed I/O.
Engineering simplicity enables an order‑of‑magnitude reduction in total system cost.
Early Products
Guided by this technical philosophy, Taalas has created the world’s fastest, lowest‑cost/power inference platform.

Figure 1: Taalas HC1 hard‑wired with Llama 3.1 8B model.
Today we are unveiling our first product: a hard‑wired Llama 3.1 8B, available as both a chatbot demo and an inference API service.
- Performance – Taalas’ silicon Llama achieves 17 K tokens / sec per user, nearly 10× faster than the current state of the art.
- Cost – It costs 20× less to build.
- Power – It consumes 10× less power.
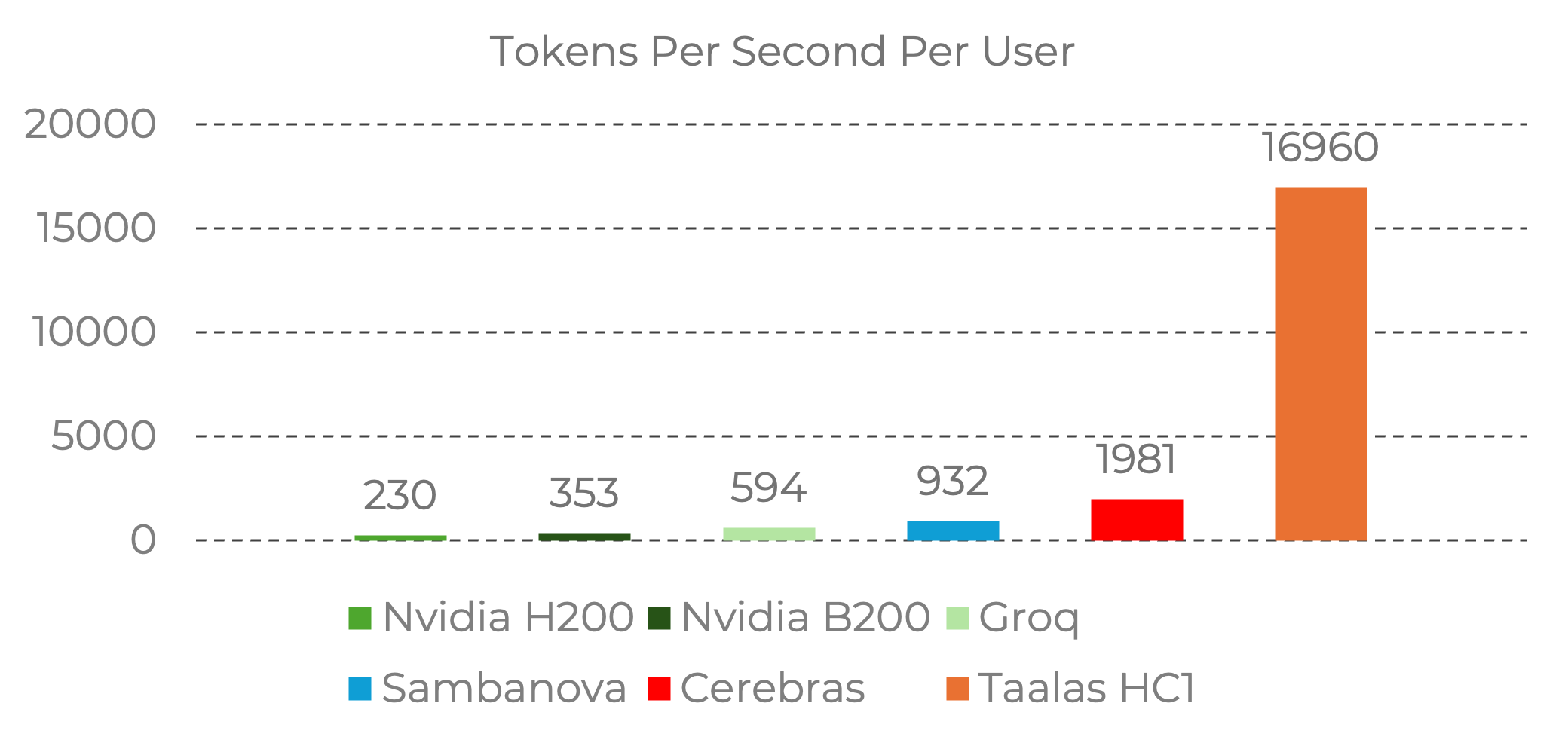
Figure 2: Taalas HC1 delivers leadership tokens / sec / user on Llama 3.1 8B.
Performance data for Llama 3.1 8B, input sequence length 1 k/1 k.
Sources: Nvidia Baseline (H200) – measured by Taalas; Groq, Sambanova, Cerebras – from Artificial Analysis; Taalas Performance – run by Taalas labs.
We selected Llama 3.1 8B as the basis for our first product due to its practicality. Its small size and open‑source availability allowed us to harden the model with minimal logistical effort.
While largely hard‑wired for speed, the Llama retains flexibility through:
- Configurable context‑window size.
- Support for fine‑tuning via low‑rank adapters (LoRAs).
When we began work on our first‑generation design, low‑precision parameter formats were not yet standardized. Consequently, the first silicon platform used a custom 3‑bit base data type. The Silicon Llama is aggressively quantized, combining 3‑bit and 6‑bit parameters, which introduces some quality degradation relative to GPU benchmarks.
Our second‑generation silicon adopts standard 4‑bit floating‑point formats, addressing these limitations while maintaining high speed and efficiency.
Upcoming Models
Our second model, still based on Taalas’ first‑generation architecture, will target larger open‑source models (e.g., Llama 3.1 70B) and incorporate the new 4‑bit floating‑point format. This next‑generation hardware will further improve:
- Throughput – aiming for > 30 K tokens / sec per user.
- Energy efficiency – targeting sub‑0.5 W per token.
- Scalability – modular designs that can be tiled to support multi‑model workloads.
Stay tuned for announcements later this year.
For more information, visit taalas.com or contact us at info@taalas.com.
The t‑generation silicon platform (HC1) will be a mid‑sized reasoning LLM. It is expected in our labs this spring and will be integrated into our inference service shortly thereafter.
Following this, a frontier LLM will be fabricated using our second‑generation silicon platform (HC2). HC2 offers considerably higher density and even faster execution. Deployment is planned for winter.
Instantaneous AI, in Your Hands Today
Our debut model is clearly not on the leading edge, but we decided to release it as a beta service anyway – to let developers explore what becomes possible when LLM inference runs at sub‑millisecond speed and near‑zero cost.
We believe that our service enables many classes of applications that were previously impractical, and we want to encourage developers to experiment and discover how these capabilities can be applied.
Apply for access here, and engage with a system that removes traditional AI latency and cost constraints.
On Substance, Team and Craft
At its core, Taalas is a small group of long‑time collaborators, many of whom have been together for over twenty years. To remain lean and focused, we rely on external partners who bring equal skill and decades of shared experience.
The team grows slowly, with new members joining through demonstrated excellence, alignment with our mission, and respect for our established practices. Here, substance outweighs spectacle, craft outweighs scale, and rigor outweighs redundancy.
Taalas is a precision strike in a world where deep‑tech startups approach their chosen problems like medieval armies besieging a walled city—swarming numbers, overflowing coffers of venture capital, and a clamor of hype that drowns out clear thought.
Our first product was brought to market by a team of 24 members, with a total spend of just $30 M out of more than $200 M raised. This achievement demonstrates that precisely defined goals and disciplined focus achieve what brute force cannot.
Going forward, we will advance in the open. Our Llama inference platform is already in your hands. Future systems will follow as they mature. We will expose them early, iterate swiftly, and accept the rough edges.
Conclusion
Innovation begins by questioning assumptions and venturing into the neglected corners of any solution space. That is the path we chose at Taalas.
Our technology delivers step‑function gains in performance, power efficiency, and cost. It reflects a fundamentally different architectural philosophy from the mainstream—one that redefines how AI systems are built and deployed.
Disruptive advances rarely look familiar at first, and we are committed to helping the industry understand and adopt this new operating paradigm.
Our first products, beginning with our hard‑wired Llama and rapidly expanding to more capable models, eliminate high latency and cost—the core barriers to ubiquitous AI.
We have placed instantaneous, ultra‑low‑cost intelligence in developers’ hands and are eagerly looking forward to seeing what they build with it.