The Data Warehouse Doesn’t Need a ‘House’ — And That’s Why It’s Faster
Source: Dev.to
Overview
We know that early databases do not distinguish between TP (transaction processing) and AP (analytical processing); all tasks are handled in a single database.
When dealing with TP business, it is important to ensure data consistency. Consistency only makes sense when the data are limited to a certain range, which gives rise to the concept of a “base.”
- The data to be loaded into a database must meet certain constraints; otherwise, they cannot be loaded.
- There is a clear distinction between data inside and outside the database—this characteristic is called closedness.
In addition to guaranteeing consistency, closedness can also guarantee data security when working with a Database Management System (DBMS).
From Database to Data Warehouse
A data warehouse is developed based on a database. When a single database can no longer serve both OLTP and OLAP workloads simultaneously, the AP workload is separated into its own database, giving rise to the data warehouse.
Therefore, a data warehouse inherits many characteristics of a database, including closedness. Inheriting closedness means inheriting rules such as:
- “The data can be used only after being loaded into the database.”
- “The data to be loaded must meet certain criteria.”
Naturally, the concept of a “house” of a data warehouse is formed.
Is Closed Storage Necessary?
- TP business – Yes, closed storage is necessary.
- Data‑warehouse (AP) business – Not necessarily.
Although the term data warehouse contains the word “house,” its main function is computation. Even if a warehouse can store data like a “house,” its value comes from calculating that data.
The competition among modern data warehouses focuses almost entirely on:
- Computing ability (performance, completeness of functions, richness of features).
- Storage – only as a means to support computation.
Thus, the key point of a data warehouse is computation, not storage.
Can We Provide a Powerful Computing Engine Without Binding Storage?
For most SQL‑based (relational‑algebra) data warehouses, the answer is no. The binding of storage and computation is inherent to the database origins of these warehouses and cannot be changed.
However, a new class of “no‑house” data warehouses does exist – esProc SPL!
What Is esProc?
- An open computing engine specialized in AP processing.
- Connects to diverse data sources and performs mixed calculations across them.
- Provides its own high‑performance file storage to ensure computing performance.
- Uses SPL (Structured Process Language) instead of SQL, offering advantages over traditional SQL.
The term “no house” in this article means no closed, private storage like that of a traditional data warehouse.
Where Are the Data Stored?
Below we answer this and related questions, and explore the benefits of a “no‑house” approach (i.e., the problems it overcomes).
Real‑Time Computation of Diverse Data Sources
Once data are generated, they are stored somewhere—a database, a file, or the web. In a broad sense, the data are already stored. Wouldn’t it be convenient if we could process the data directly, wherever they reside?
Enterprises today face diverse data sources and types. Being able to process them directly brings huge convenience.
esProc’s Capabilities
- Open‑format, multi‑source processing – No matter where the data live (RDBMS, NoSQL, files, Hadoop, RESTful APIs, etc.), esProc can read and calculate directly.
- Mixed computing – esProc can connect to different sources and perform calculations that span them.

When the ability to support diverse data sources (mixed calculation) is available, the limitation of a “house” is broken, yielding several advantages:
- Eliminates ETL overhead – No need to load data into a database before computing.
- Real‑time calculation – Guarantees up‑to‑date results across multiple sources.
- Reduced storage cost & DB pressure – Databases are no longer burdened with indiscriminate data loading, which is especially valuable during the early adoption stage when a data warehouse and esProc coexist.
Leveraging the Strengths of Each Source
| Source Type | Strength | How esProc Uses It |
|---|---|---|
| RDBMS | Strong computing ability | Perform part of the calculation in the RDBMS, then let esProc finish the rest. |
| NoSQL / Files | High I/O transfer efficiency | Read and calculate directly in esProc. |
| MongoDB | Multi‑layer data storage | SPL can consume MongoDB data directly. |
These benefits stem from openness. In contrast, a closed data warehouse cannot compute data outside its own storage. It must import (ETL) the data first, which:
- Increases programmer workload.
- Adds load to the database.
Summary
- Traditional databases enforce closedness to guarantee consistency and security.
- Data warehouses inherit this closedness, but for AP workloads the primary value lies in computation, not storage.
- A “no‑house” architecture—exemplified by esProc SPL—decouples computation from storage, enabling real‑time, multi‑source processing without the overhead of ETL.
By embracing openness, organizations can reduce costs, accelerate development, and fully exploit the strengths of each data source.
Real‑time Data Challenges
The real‑time nature of data is often lost. External data usually comes in irregular formats, making it difficult to load directly into a database with strict constraints. Even when an ETL process is used, the raw data must first be loaded into the database to leverage its computing power. Consequently, ETL often turns into ELT, adding extra burden to the database.
Computation can be performed regardless of where the data resides—this is one of the key benefits of the “no‑house” approach that esProc provides.
High Performance
When esProc reads from diverse data sources, the logical status may be the same, but read performance (and thus total computation time) can vary because the efficiency of each source’s interface differs. For some interfaces (e.g., an RDBMS via JDBC), read performance is very low.
While direct access to many data sources is convenient, it can lead to poor computing performance. To guarantee high performance, esProc offers a specialized binary file storage format together with several optimization mechanisms:
- Compression
- Columnar storage
- Ordering
- Parallel segmentation
Note: esProc’s file storage is open—the files live in the regular file system alongside text files, Excel sheets, etc. esProc does not own these files; it merely provides optimization strategies to make file access more efficient.
In contrast, traditional data‑warehouse storage (“house”) is closed and private. Its performance depends on the optimizer of the underlying engine. A good database can choose an efficient execution plan for simple SQL, but once the SQL becomes moderately complex, the optimizer may fail and fall back to a literal execution path, causing a sharp performance drop. Because the storage is closed, we cannot intervene (e.g., sort data by primary key) to improve performance.
esProc’s open file storage is highly flexible: we can design storage layouts based on any algorithm, adjust the data accordingly, and thus achieve superior performance.
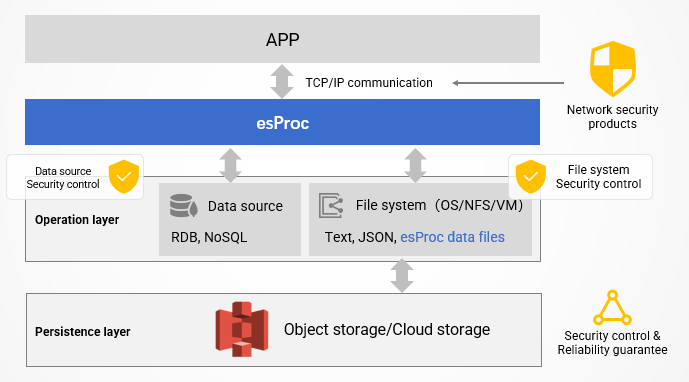
Security and Reliability
Open computing and file‑based storage raise a natural question: traditional data warehouses ensure security and reliability through their closed nature—how can esProc, which does not bind storage, guarantee the same?
The answer is simple: esProc does not manage data security; it relies on the security mechanisms of the underlying data sources.
- Databases provide authentication, authorization, auditing, etc.
- File systems / virtual machines offer access control, identity verification, and transmission encryption.
- Object storage services (e.g., Amazon S3) can be used to retrieve data before computation, and their built‑in security features are leveraged. Cloud storage often offers stronger security and reliability than many on‑premise databases.
For application access, the independent esProc service communicates via standard TCP/IP and HTTP. Network security products can monitor and protect this traffic, and the responsibility for those security measures lies with the products themselves.
Why “no‑house” Can Be More Secure
Traditional “house” databases often have coarse permission management, granting all application users high‑privilege access for the sake of convenience. This includes dangerous permissions such as compiling stored procedures, which weakens overall security.
esProc focuses solely on computation:
- It operates on data stored securely by other systems.
- It does not alter or interfere with the storage layer.
Reliability, like security, is proportional to investment. Even with expensive “two‑site, three‑center” architectures, reliability can still fall short of what professional storage technologies (e.g., cloud object storage) already provide.
Implement HTAP Requirement
In recent years, HTAP has become another hot spot in the database field. Most databases implement HTAP only by attaching certain AP capabilities to a TP database or by binding the two technologies together. Regardless of the method, database migration is unavoidable, bringing high risk and the closed‑ness and performance problems of the original data warehouse.
The HTAP requirement is essentially to query data in real‑time after the separation of databases. If this ability is available, the requirement can be implemented without modifying the original TP database (no migration risk).
We can introduce esProc based on the original independent TP and AP systems, and utilize esProc’s:
- Open cross‑source computing ability
- High‑performance storage and computing capabilities
- Agile development ability
to implement this requirement.
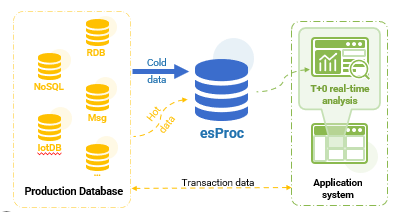
esProc implements HTAP in a way that cooperates with the existing system. It only needs a few modifications to the existing architecture, and there is almost no need to modify the TP database. Even the original AP data source can still be used, allowing esProc to gradually take over AP business.
- Once partially or completely taken over, the historical cold data are stored in esProc’s high‑performance file.
- The original ETL process that moves data from the business database to the data warehouse can be directly migrated to esProc.
When the cold data are large in amount and no longer change, storing them as esProc’s high‑performance file yields higher computing performance. When the amount of hot data is small, keeping them in the original TP data source enables esProc to read and calculate directly. Because the hot data volume is limited, direct querying on the TP source has minimal impact and acceptable latency.
By leveraging esProc’s mixed hot‑and‑cold data computing ability, we achieve real‑time query for the full dataset. The only operational task is to periodically:
- Store cold data as esProc’s high‑performance file.
- Keep the newly generated hot data in the original data source.
Thus, HTAP is not only implemented but also delivered with high performance and little impact on the application framework.
Implement True Lakehouse
The closed data warehouse cannot build a true Lakehouse. A data lake is often treated like a junkyard: it stores raw data of all types because it is impossible to predict which data will be useful in the future. The value of data is realized through calculation, which requires the computing ability of a data warehouse. However, traditional data warehouses are closed; data must be deeply organized before being loaded, and raw “junk data” in the lake cannot be calculated directly. Organizing data discards original information and introduces the diverse‑source problems mentioned above. Consequently, real‑time access is not guaranteed, and ETL costs are high, leading to poor timeliness.
Compared with the fake Lakehouse built on a traditional data warehouse, esProc can implement a true Lakehouse because it offers:
- Sufficient openness to calculate unorganized data directly.
- Mixed‑computation capability across many data sources while maintaining high performance via its high‑performance mechanisms.
Key Advantages
- Direct calculation of raw lake data – No constraints, no need to load data into a database.
- Mixed computation on diverse sources – Whether the lake is built on a unified file system or on heterogeneous sources (RDB, NoSQL, local files, web services), esProc can compute across them instantly.
- High‑performance file storage – esProc’s storage (the data‑warehouse function) can organize data orderly while computing. Converting raw data to esProc’s storage yields higher performance. The data remain in the file system and can be stored alongside the lake, achieving a true Lakehouse architecture.
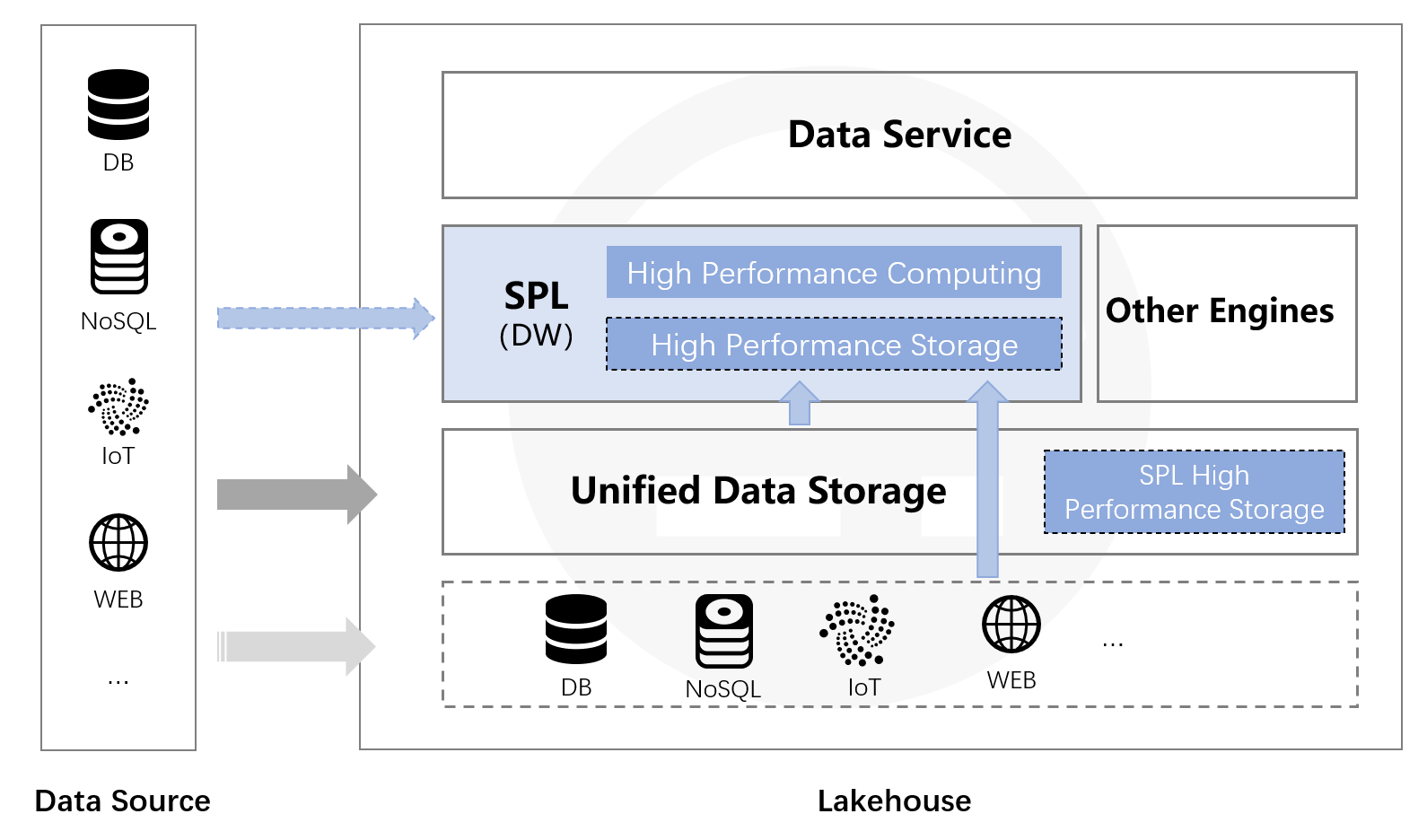
With esProc’s computing ability, organization and computation can occur simultaneously, allowing the data lake to be built stepwise and orderly. As the lake is constructed, the data warehouse is refined, endowing the lake with strong computing capability and thereby realizing a true Lakehouse.
From closed to open, this is the manifestation of continuous progress.
esProc and the “No‑House” Data Warehouse
The progress of technology drives every industry forward. The same is true for data warehouses: evolving from a “with‑house” (traditional, on‑premises) model to a “no‑house” (cloud‑native, serverless) model is an inevitable stage for modern data warehousing. Consequently, data warehouses are about to enter the era of “no‑house.”
While esProc may not be perfect, it represents a significant step toward realizing the capabilities of a “no‑house” data warehouse, and it is definitely worth trying.
Open‑Source Availability
SPL is now open‑source. You can obtain the source code from the official repository:
Try It for Free
Download the latest version and start experimenting:
Download esProc (free)