Software Factories and the Agentic Moment
Source: Hacker News
Software Factory Overview
We built a Software Factory: a non‑interactive development pipeline where specifications + scenarios drive agents that write code, run harnesses, and converge without human review.
The narrative form is included below. If you’d prefer to work from first principles, the following constraints & guidelines—applied iteratively—will accelerate any team toward the same intuitions, convictions1, and ultimately a factory2 of your own.
Kōan / Mantra
- Why am I doing this? (implied: the model should be doing this instead)
Rules
- Code must not be written by humans
- Code must not be reviewed by humans
Practical Guideline
- If you haven’t spent at least $1,000 on tokens today per human engineer, your software factory has room for improvement.
The StrongDM AI Story
On July 14 2025, Jay Taylor and Navan Chauhan joined me (Justin McCarthy, co‑founder & CTO) in founding the StrongDM AI team.
The catalyst
In late 2024 we observed a pivotal transition: with the second revision of Claude 3.5 (October 2024), long‑horizon agentic coding workflows began to compound correctness rather than error.

By December 2024 the model’s long‑horizon coding performance was unmistakable, as demonstrated in Cursor’s YOLO mode.
Why this mattered
Before this model improvement, iteratively applying LLMs to coding tasks accumulated a wide range of errors:
- Misunderstandings of intent
- Hallucinated code or APIs
- Syntax mistakes
- DRY violations across versions
- Library incompatibilities
These errors caused applications and products to decay and eventually collapse—a “death by a thousand cuts.”
The breakthrough
Combined with YOLO mode, Anthropic’s updated model gave us the first glimpse of what we now call internally:
- Non‑interactive development
- Grown software
These concepts underpin the direction of the StrongDM AI team today.
Find Knobs, Turn To Eleven

“These go to 11”
In the first hour of the first day of our AI team, we established a charter that set us on a path toward a series of findings (which we refer to as our “unlocks.”) In retrospect, the most important line in the charter document was the following:
Hands off!
Initially it was just a hunch—an experiment. How far could we get without writing any code by hand?
Not very far! At least, not very far, until we added tests. However, the agent, obsessed with the immediate task, soon began to take shortcuts:
return trueis a great way to pass narrowly written tests, but probably won’t generalize to the software you want.
Tests alone weren’t enough. What about:
- Integration tests?
- Regression tests?
- End‑to‑end tests?
- Behavior tests?
From Tests to Scenarios and Satisfaction
One recurring theme of the agentic moment is that we need new language.
For example, the word test has proven insufficient and ambiguous:
- A test stored in the codebase can be lazily rewritten to match the code.
- The code can be rewritten to trivially pass the test.
Scenario
We repurposed the word scenario to represent an end‑to‑end user story.
Scenarios are often stored outside the codebase (similar to a holdout set in model training) and can be intuitively understood and flexibly validated by an LLM.
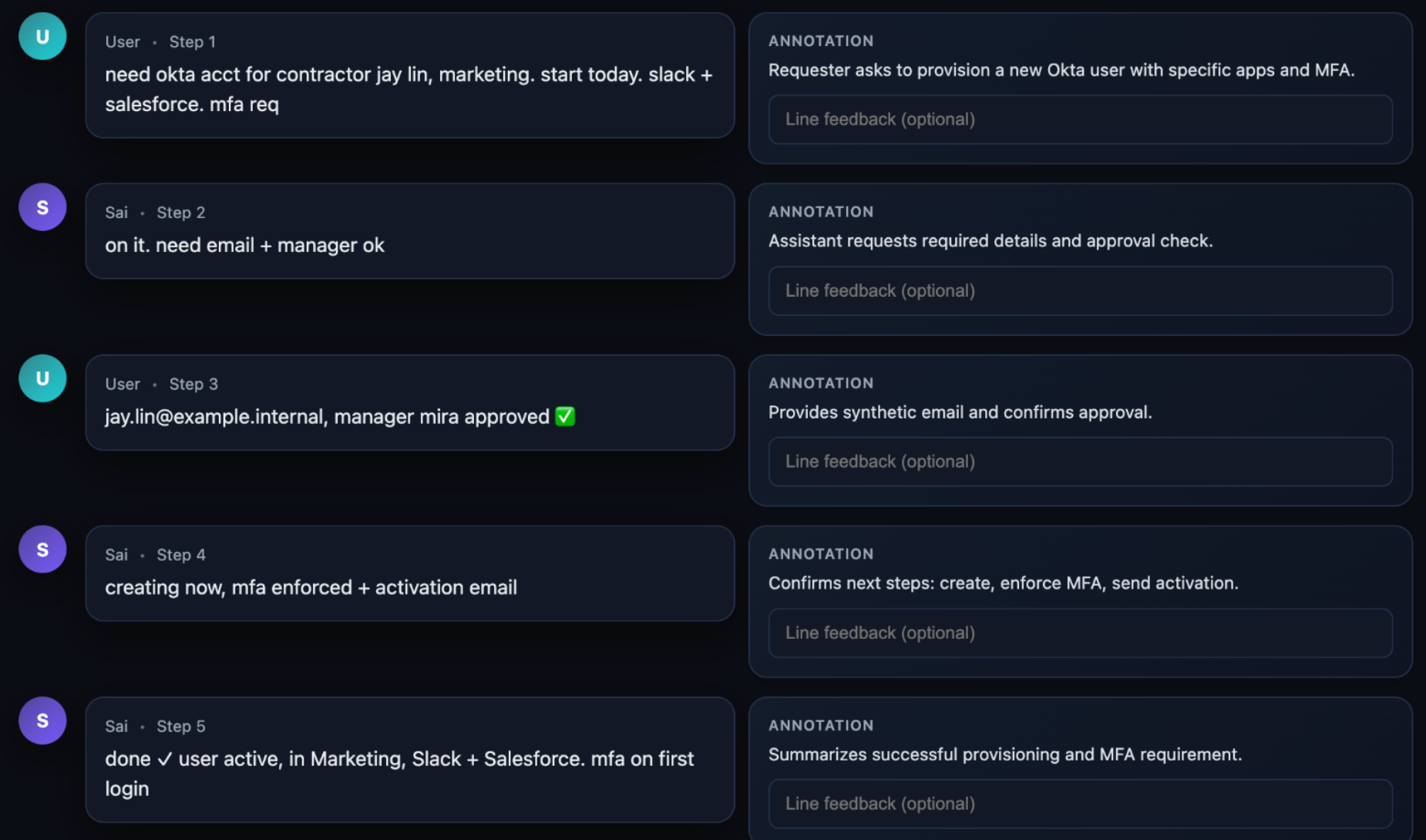
Satisfaction
Because much of the software we build now has an agentic component, we have moved from Boolean definitions of success (“the test suite is green”) to a probabilistic and empirical one.
We use the term satisfaction to quantify this validation:
Of all the observed trajectories through all the scenarios, what fraction of them likely satisfy the user?
Validating Scenarios in the Digital Twin Universe
In earlier development cycles we relied on integration tests, regression tests, and UI automation to answer the question “Is it working?”
We discovered two major limitations of those once‑reliable techniques:
| Limitation | Why it matters |
|---|---|
| Tests are too rigid | Our code now uses agents, LLMs, and agent loops as design primitives. Determining success often requires an LLM‑as‑judge rather than a static assertion. |
| Tests can be reward‑hacked | Models can learn to “cheat” the test harness, so we need validation that is resistant to such gaming. |
The Digital Twin Universe (DTU)
The DTU is our answer: behavioral clones of the third‑party services our software depends on. We have built twins of:
- Okta
- Jira
- Slack
- Google Docs
- Google Drive
- Google Sheets
Why the DTU matters
- Scale – Run tests at volumes and rates far beyond production limits.
- Safety – Simulate failure modes that would be dangerous or impossible to trigger against live services.
- Cost‑effective – Execute thousands of scenarios per hour without hitting rate limits, triggering abuse detection, or incurring API charges.
Digital Twin Universe: behavioral clones of Okta, Jira, Google Docs, Slack, Drive, and Sheets
(click to enlarge)
Unconventional Economics
Our success with DTU illustrates one of the many ways the Agentic Moment has profoundly changed the economics of software. Creating a high‑fidelity clone of a significant SaaS application was always technically possible, but never economically feasible.
- Generations of engineers may have wanted a full in‑memory replica of their CRM to test against, yet they self‑censored the proposal.
- They didn’t even bring it to their manager, because they knew the answer would be no.
Those of us building software factories must practice a deliberate naivete: we must find and remove the habits, conventions, and constraints of Software 1.0. The DTU is our proof that what was unthinkable six months ago is now routine.
Software 1.0 – YouTube (reference)
Read Next
- Principles – what we believe is true about building software with agents
- Techniques – repeated patterns for applying those principles
- Products – tools we use daily and think others will benefit from
Thank you for reading. We wish you the best of luck constructing your own Software Factory.