Scaling AI-Driven Conversations from 10K to 100K While Maintaining Real-Time Consistency
Source: Salesforce Engineering
by Ashima Kochar and Deepak Mali.
What is your team’s mission in building the Conversation Storage Service (CSS), and how does it support AI‑driven customer engagement in Service Cloud?
CSS is not just a storage system — it is the source of truth for conversational context, which directly powers real‑time AI systems such as sentiment analysis, agent assist, and supervisor insights. It provides a scalable, reliable foundation for persisting and retrieving interactions across digital channels with near‑real‑time availability.
The team behind CSS builds a scalable, reliable foundation for conversational data to enable AI‑driven engagement within Service Cloud. This platform persists every interaction across digital channels while ensuring that data remains almost immediately available for downstream systems.
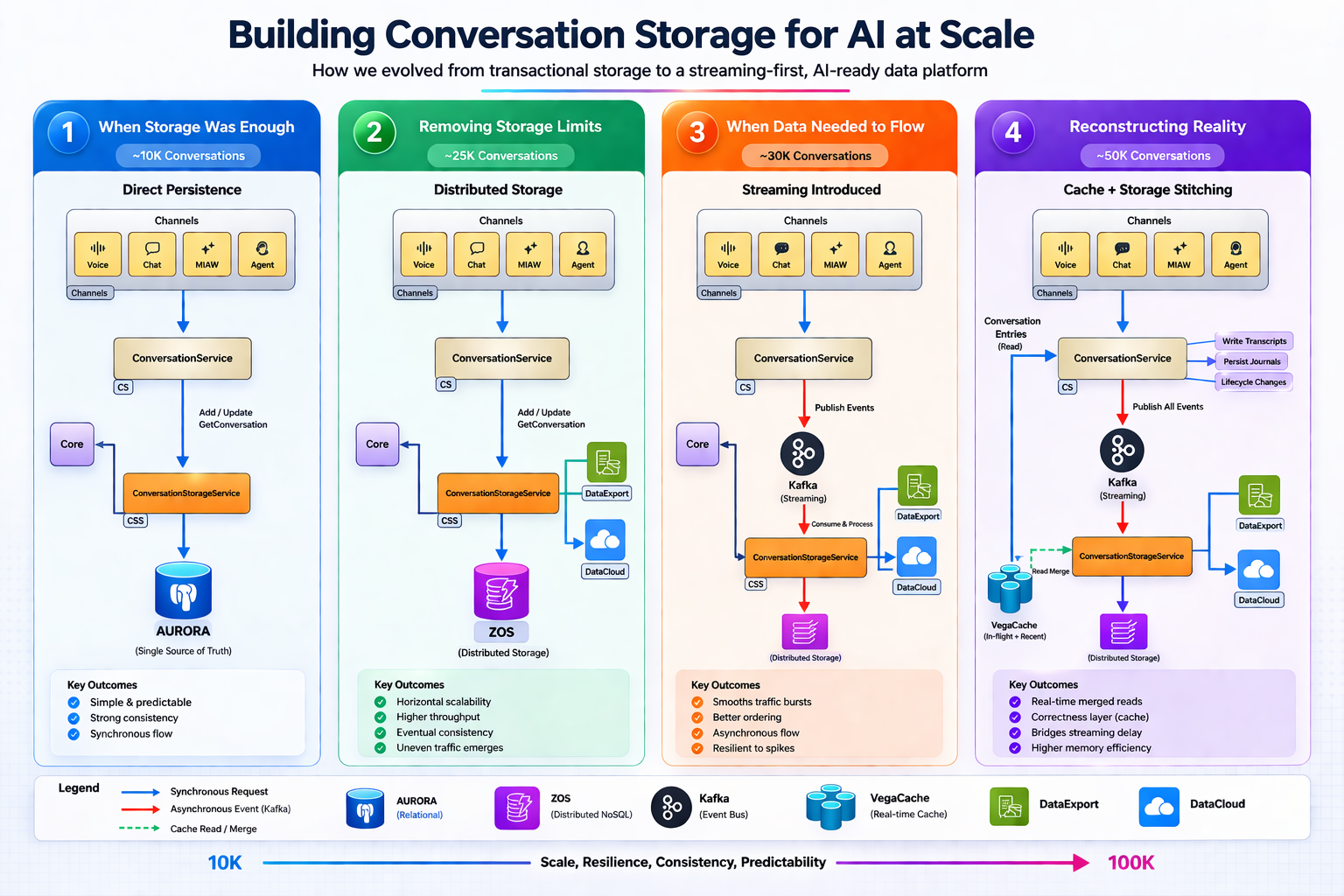
As organic data growth and the adoption of Agentforce and CcaaS increase, workloads must support up to 50 000 concurrent conversations with a target of 100 000 at peak throughput. These interactions involve larger payloads, longer threads, and higher expectations for real‑time access.
This scale is foundational to the Unified Agentic Communication Platform (UACP), enabling unified conversations across channels and agents with consistent, ordered context. CSS focuses on high‑throughput ingestion and low‑latency retrieval to deliver accurate data to Data 360, Core, and AI pipelines, ensuring both human and AI agents operate on a complete, up‑to‑date view of interactions.
What constraints emerged as CSS scaled to support high‑volume conversational workloads across distributed systems?
- CSS hit limits beyond 10 000 concurrent conversations because the Postgres-based system struggled with bursty traffic from high‑activity tenants. These surges created hotspots and degraded write performance across the platform.
- To address this, the team moved to a horizontally scaled No‑SQL DB to buffer and batch events in the application layer at the tenant level as ingestion rates increased.
- They also introduced Kafka with conversation‑level partitioning to distribute the load more evenly, smoothing spikes before they reached storage.
This shift still had a trade‑off: asynchronous processing introduced delays between writes and reads. Those read‑after‑write gaps could have impacted agent workflows, so the team added VegaCache to serve recent writes directly while persistence catches up.
These changes allowed CSS to scale throughput effectively. Now the system maintains faster read‑after‑write consistency and powers real‑time insights for AI‑driven conversational workloads.
What scale pressures shaped the CSS architecture as it moved from 10 K to 50 K and toward 100 K concurrent conversations?
The conversation platform underwent an architectural evolution to meet the UACP north star and CSS goals. Each scale inflection point exposed specific limitations and drove subsequent design decisions.
| Scale (concurrent) | Key Challenge | Architectural Response |
|---|---|---|
| ~10 000 | Transactional system performed well | Baseline design |
| ~25 000 | Uneven traffic—certain tenants generated disproportionate load | Moved to distributed storage |
| ~30 000 | Need to stabilize ingestion | Added Kafka for buffering & batching |
| ~50 000 | Lag from asynchronous pipeline impacted real‑time workflows | Introduced VegaCache for read‑after‑write consistency |
| ~100 000 (target) | Further latency and source‑of‑truth concerns | Transitioning to curated Kafka – turning the conversation stream into an ordered source of truth and reducing reliance on multiple storage layers |
What complexities emerged as AI‑driven conversational workloads increased in volume, payload size, and real‑time expectations?
AI‑driven conversational workloads significantly increased both the volume and complexity of data. Modern interactions now include:
- Longer dialogues and larger payloads (e.g., conversational email, voice transcripts, AI‑generated responses).
- Near‑real‑time access requirements for both human agents and automated systems, making low‑latency, consistent retrieval critical.
To address these challenges, CSS introduced several data‑efficiency and access optimizations:
- Compression – reduces storage footprint and network bandwidth for large payloads.
- Pagination – fetches long conversations in manageable segments.
- VegaCache – provides immediate visibility into recent updates, masking delays introduced by asynchronous streaming.
These improvements enable CSS to support the platform‑wide effort toward 100 000 concurrent conversations, ensuring AI‑driven agents and human users operate on a complete, up‑to‑date view of each interaction.
Vice Cloud Modernized Platform (SCRT2) Components
- CS enables high‑throughput ingestion.
- Ajna stabilizes flow.
- ZOS scales storage.
- VegaCache maintains real‑time visibility.
Together they ensure predictable scale without compromising latency or consistency.
What limitations surfaced in the CSS streaming pipeline when ingesting real‑time conversation events at scale?
- Consumer lag became the primary challenge once ingestion exceeded 30,000 events per minute.
- Heavy loads forced events into queues, delaying data persistence and creating gaps in information access.
- These delays could disrupt agent tasks and AI systems that require instant data.
Mitigations introduced
- VegaCache serves recent writes immediately, masking streaming delays.
- Conversation partitioning, batching, and back‑pressure controls reduce hotspots and steady the data flow.
These updates help the pipeline handle traffic spikes while keeping AI workloads consistent. As part of UACP, this streaming pipeline is the backbone for Unified Communication Services (UCP), enabling messages from multiple channels to converge into a single conversational flow while maintaining consistent ingestion at scale.
What integration constraints did you face ensuring CSS data could reliably power downstream systems such as Data 360, Core reporting, and AI pipelines?
- Diverse downstream formats created difficulties for schema mapping and data transformation.
- Defining data‑lake objects and data‑model objects for every interaction type made integration slow and heavyweight.
Solution
- Built a metadata‑driven integration layer that simplifies the addition of new data types and eliminates manual schema work.
- CSS also supports bulk exports through S3 for large‑scale analytics.
This positions CSS as a data distribution layer, not just a storage system, serving operational, analytical, and AI workloads simultaneously.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.