RLAAS (Rate Limiting As A Service): Rate Limiting Across Modern Systems
Source: Dev.to
The Problem Nobody Talks About
Every engineering team knows they need rate limiting, but most solutions only protect one layer — the API gateway.
What happens to everything else?
| Pain point | Description |
|---|---|
| Log floods | A bug sends millions of error logs to your observability stack. Costs spike, dashboards break, and on‑call engineers drown in noise. |
| Metric storms | A chatty service emits 50× the normal Datadog metrics during a deployment. Your bill triples overnight. |
| Kafka cascades | A slow consumer falls behind. Retries pile up. One service can take down the entire event pipeline. |
| Sidecar blind‑spots | Traffic between services inside a mesh never hits your gateway, so nothing enforces limits there. |
| Copy‑paste rate limiting | Every team re‑implements throttling logic in their own service, with their own bugs, edge cases, and no shared policy. |
The root cause is the same in every case: rate limiting is treated as a gateway feature, not a platform capability.
That’s what I set out to fix.
Introducing RLAAS
RLAAS is an open‑source, policy‑driven platform written in Go. It applies consistent rate‑limiting decisions across multiple domains — HTTP, gRPC, telemetry, events, and sidecars — using one unified engine.
Instead of scattered, per‑service throttling code, you define policies once and enforce them everywhere.
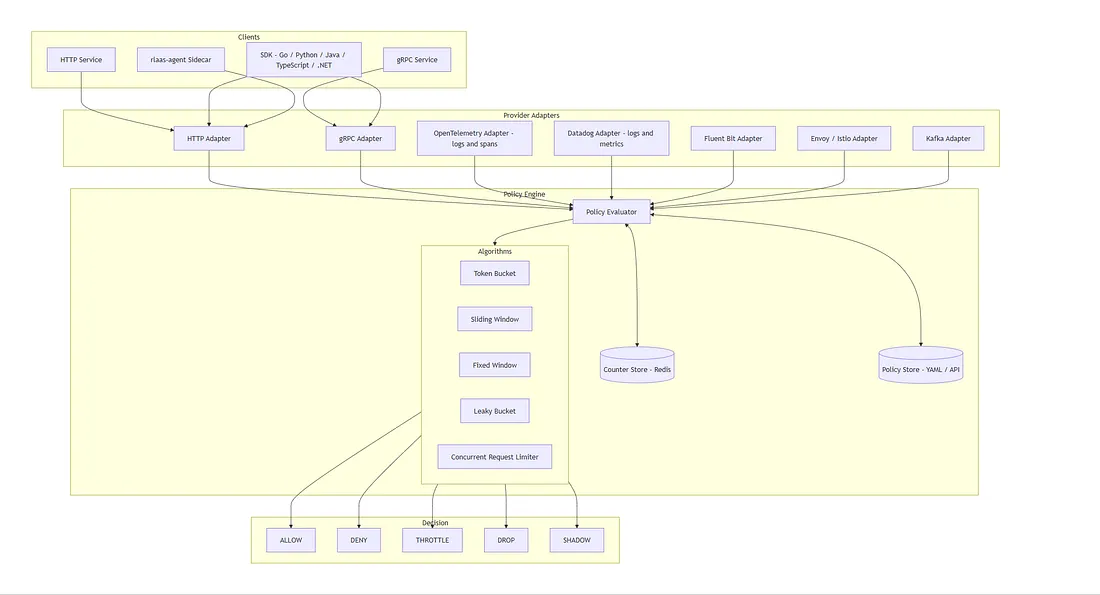
Core idea: one policy engine, multiple providers, multiple deployment models.
Algorithms It Supports Today
RLAAS doesn’t lock you into a single algorithm. Each policy independently chooses the algorithm that fits its traffic pattern:
- Token Bucket – A bucket refills tokens at a fixed rate. Requests consume tokens; when empty, requests are throttled. Great for bursty traffic you want to smooth out without hard‑blocking. Example: allow up to 100 API calls per minute with short bursts permitted.
- Sliding Window – Tracks requests across a continuously rolling time window. Eliminates the “boundary spike” problem where clients fire double the limit by straddling two fixed‑window edges. Best for accurate per‑user and per‑tenant quota enforcement.
- Fixed Window – Counts requests in a hard time slot (e.g., 0–60 s). Simple, cheap, and predictable. Best when coarse‑grained limits matter more than precision.
- Leaky Bucket – Enforces a strict, steady output rate regardless of how bursty the input is. Useful for protecting downstream services that can’t handle spikes even if the total volume is within limits.
- Concurrent Request Limiter – Caps the number of in‑flight requests at any moment. Essential for protecting slow upstream dependencies from being overwhelmed by parallel callers.
A single RLAAS deployment can run all algorithms simultaneously across different policies and resources.
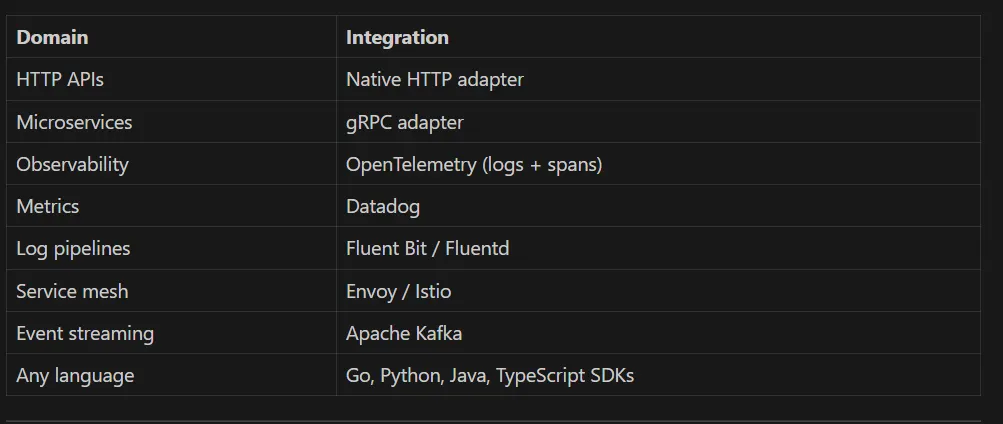
What RLAAS Integrates With
One policy engine, many integration points:
Decisions — More Than Just Allow or Deny
Most rate limiters return two answers: pass or reject. RLAAS returns five:
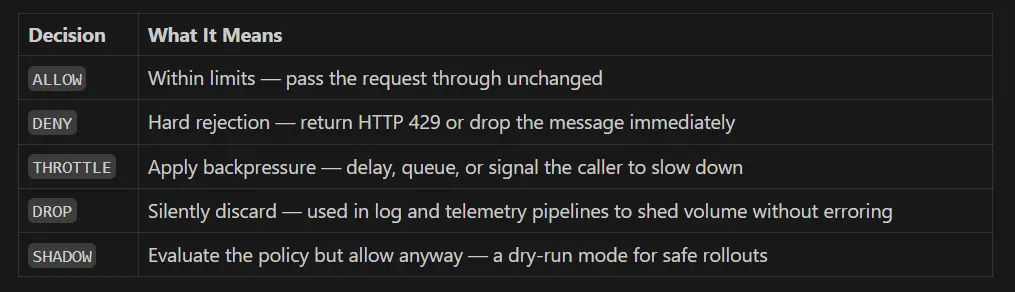
Shadow mode is especially powerful during rollouts. You can observe exactly what would have been throttled before flipping enforcement on — no surprises, no incidents.
Each policy declares its own action, so one policy can DENY abusive callers while another DROP noisy telemetry and a third runs in SHADOW mode while the team validates thresholds.
Three Ways to Deploy It
- Embedded SDK – Import the library directly into your service. Zero network hop, full control. Works in Go, Python, Java, and TypeScript.
- Centralized Service – Deploy
rlaas-serveras a shared microservice. All your services call it over gRPC or HTTP to get allow/deny decisions. One place to manage all policies. - Sidecar / Agent – Run
rlaas-agentas a sidecar next to your workload. No code changes needed. Intercepts traffic at the infrastructure level. Works with Kubernetes, service meshes, and bare‑metal alike.
How Policies Work
Policies are declarative and version‑controlled. You define who the policy applies to, which algorithm to use, the limit, the window, and what to do when the limit is hit.
{
"id": "nw-payments-logs",
"org_id": "northwind",
"resource": "payments.logs",
"algorithm": "sliding_window",
"limit": 5000,
"window_seconds": 60,
"action": "drop"
}No code changes. No redeploys. Policy updates take effect immediately.
Why Open Source?
Rate‑limiting logic is not your competitive advantage. It’s infrastructure — a shared, reusable capability that should be transparent, auditable, and community‑driven. Open‑sourcing RLAAS lets teams collaborate on a robust, battle‑tested solution while keeping the focus of each service on its core business logic.
RLAAS – Reinforcement Learning as a Service
The same way a load balancer or a message queue is infrastructure, RLAAS should be shared, composable, and policy‑driven rather than handcrafted inside each microservice.
RLAAS is MIT‑licensed. Every algorithm, every adapter, and every SDK is open source and built to be extended.
Try It
Docs:
GitHub:
If this solves a problem you’re dealing with, feel free to:
- Open an issue
- Contribute an adapter
- Share it with your team