Publishing Pipeline - Refactoring
Source: Dev.to
Where We Started
The original setup had clear limitations:
- One script, one platform
- Tight coupling between:
- content loading
- publishing logic
- database access
- Minimal state tracking
- Hard to debug
- Hard to extend
- Impossible to reason about once it grew past a few hundred lines
In short: it worked, but it didn’t scale — neither technically nor mentally.
Original Flow
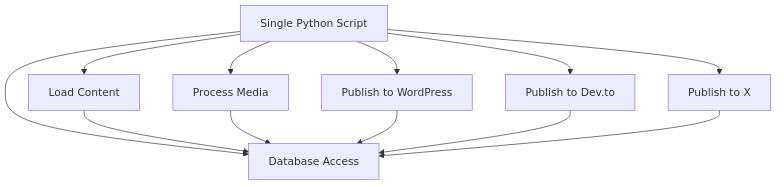
Characteristics of the Old Design
- One script owns everything
- Platform logic intertwined
- Hard to add new platforms
- Any change risks breaking unrelated behavior
- Re‑running safely is difficult
The New Architecture: Clear Responsibilities Everywhere
Over the past weeks, the pipeline was redesigned around layers, each with a single responsibility.
1. Pipeline Layer (Orchestration)
Responsible only for flow:
- Load posts
- Process media
- Inject backlinks
- Publish to enabled platforms
- Track results
No platform‑specific logic lives here.
2. Publisher Layer (Per‑Platform Semantics)
Each platform gets:
- a Publisher (what to publish, when, and how)
- a Client (how to talk to the API)
This distinction turned out to be crucial. For example:
| Platform | Update Support |
|---|---|
| WordPress | Supports updates |
| Dev.to | Supports updates with constraints |
| X (Twitter) | Publish‑once‑only |
That difference now lives exactly where it belongs: inside the publisher, not smeared across the pipeline.
3. Client Layer (Pure API Communication)
Clients do one thing only:
- Authenticate
- Send requests
- Return normalized results
They contain no:
- Database access
- Publishing decisions
- Content logic
This makes them:
- Testable
- Replaceable
- Reusable
4. Database Layer (State & Deduplication)
The database now tracks:
- What was published
- Where it was published
- Which content hash was used
- Which media assets already exist
- Canonical URLs
This enables:
- Idempotent runs
- Safe re‑publishing
- Deduplication of media
- Correct canonical handling across platforms
New Flow Diagram
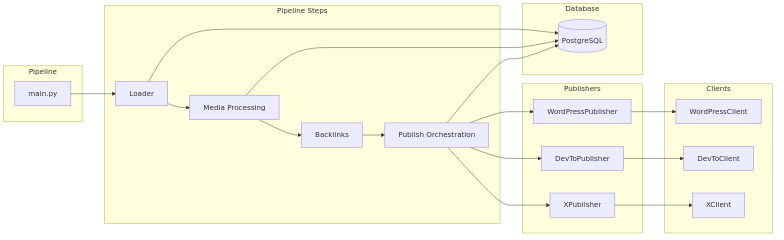
What Changed
- Pipeline only controls flow.
- Publishers decide what to do.
- Clients only talk to APIs.
- Database provides state and idempotency.
- Each part is testable and replaceable.
This is the turning point where the system stops being fragile.
Why This Is Faster (and Calmer)
One unexpected benefit: performance and reliability improved naturally—not because of clever optimizations, but because:
- Small modules load faster
- Less global state stays in memory
- Failures are isolated
- Logs are precise and meaningful
- Re‑runs are cheap and safe
Instead of hoping nothing breaks, the pipeline now knows when nothing needs to happen.
Adding a New Platform Is Now Boring (That’s a Compliment)
To add a new platform today, the steps are:
- Write a client (
platforms/foo_client.py) - Write a publisher (
publishers/foo.py) - Wire it into the composition root
No changes required to:
- Media handling
- Backlinks
- Canonical logic
- Database schema
- Pipeline flow
That’s the kind of boring you (well, I for certain) want.
Media, Backlinks, Canonicals — All Solved Properly
Some highlights that are now just working:
- Media deduplication via hashing → upload once, reuse everywhere
- Featured images correctly attached per post
- Backlinks injected deterministically
- Canonical URLs handled centrally and propagated correctly
- Per‑platform semantics respected (no more accidental re‑posting)
None of this required hacks—only the right separation of concerns.
What I Learned (The Unexpected Part)
This project wasn’t about learning Python—but it turned into exactly that. In three weeks, I learned more about:
- Python module design
- Data modeling
- Immutability vs. mutation
- Error handling
- API semantics
- Architectural boundaries
Key insight: Python becomes dramatically easier once the architecture is clean. Most complexity wasn’t Python at all—it was unclear responsibility.
What’s Next: Roadmap to v1.4.0
The current version 1.3.1 closes the stabilization phase.
The next milestone, 1.4.0, will focus on capabilities.
Planned Features
- Platform‑Aware Update Strategies
- … (details to be added)
# Publish‑once (X)
- **Update‑in‑place** (WordPress)
- **Conditional update** (Dev.to)
- **Future:** quote‑tweet or follow‑up logic
## 2. Rate Limiting & Scheduling
- Per‑platform throttling
- Optional delayed publishing
- CI‑safe dry‑run mode
## 3. Observability Improvements
- Structured logs
- Optional JSON output
- Better failure summaries New Platforms (Starting with One)
At least one new platform will be added in v1.4.0.
Candidates
- LinkedIn (high priority)
- Indeed (content‑syndication angle)
Later roadmap
- Substack
- Patreon
- Possibly others
Thanks to the current architecture, adding these is now a contained task, not a rewrite.
And Yes — This Will Become a Series
This post is likely the first of a small series covering:
- Python for infrastructure‑minded people
- Real‑world refactoring
- Automation that survives growth
- Designing for change, not just success
Not tutorials — but honest write‑ups of systems that evolved under real constraints.
Final Thoughts
What started as a utility script has become a small platform.
Not because it needed to be fancy — but because it needed to be understandable, extendable, and trustworthy.
And that, more than anything, made the difference.
Down the road it might become a service that interested people can use for their own writing. Since I am developing and running my own Kubernetes cloud, there should be nothing in the way of making this a container solution accessible for tenants.
Support
Did you find this post helpful? You can support me.


