Norway's 2 petabytes of Huawei flash storage and LLM training
Source: Hacker News
Norway’s National Library LLM Project
Overview
Norway’s National Library is developing a large‑language model (LLM) that understands the Norwegian language and is using 2 PB of Huawei OceanStor Dorado flash storage in its AI training data pipeline.

Marius Husnes, Head of IT Platform at the library
Marius Husnes discussed the project at Huawei’s ID Forum 2026 in Paris, noting that no commercial LLM provider was developing a local (Norwegian) language model. He argued that any country whose language lacks a sovereign LLM is at a disadvantage: a globally trained, English‑centric model would miss the nation’s history, news, and culture expressed in the local language.
The Norwegian Ministry of Culture tasked the National Library with building a sovereign AI because the library holds the single largest digital collection of Norwegian books, newspapers, web pages, and other cultural material. Its legal‑deposit mandate extends beyond books to all of Norway’s cultural heritage.
Data Access & Storage
An agreement with Norwegian newspapers permits LLM training on copyrighted content. As Husnes put it, “No private company has this.”
The library has been digitising its collection since 2005 and now stores 20 PB of unique data in a 3‑2‑1 configuration (3 copies, 2 media types, 1 off‑site), amounting to roughly 60 PB overall. The digitisation pipeline (text, audio, video, images, web content) generates extensive OCR data, metadata, and APIs for online access.
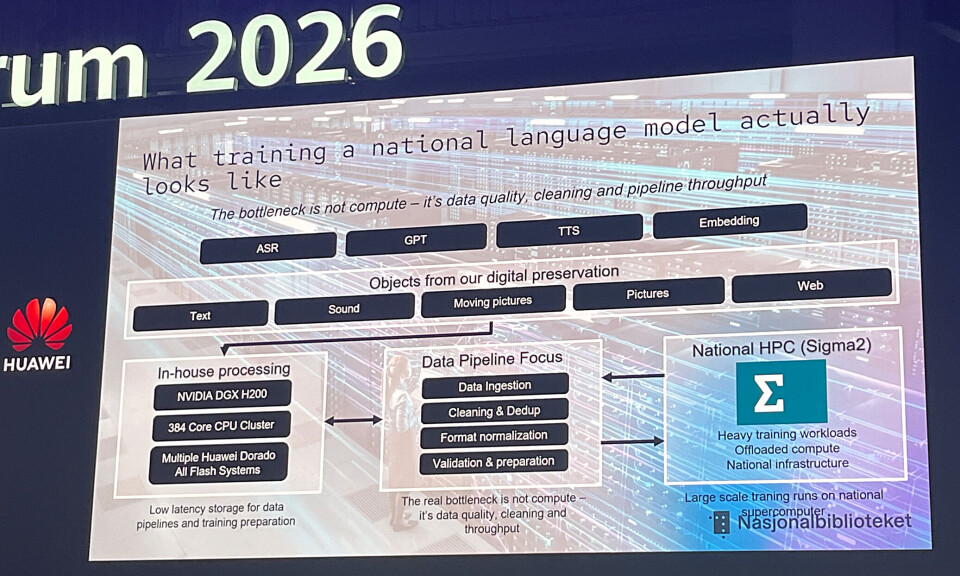
The bulk of this data resides in a digital disk‑plus‑tape archive (a preservation system). Husnes’ challenge is moving this data into the LLM training pipeline. He identified the bottleneck not as compute, but as data quality, cleaning, and pipeline throughput.
First processing stage
- Compute: Nvidia DGX H200, a 384‑core CPU cluster.
- Storage: Huawei OceanStor Dorado all‑flash arrays (2 PB total), providing low‑latency storage for data pipelines and training preparation.
Husnes – training national LLM
The pipeline performs ingestion, cleaning, deduplication, format normalisation, validation, and preparation. Once processed, the data is sent to Norway’s national supercomputer, the Sigma2 Olivia system, for the actual training runs.
- Olivia: HPE Cray EX system with 448 GPUs and 64 512 CPU cores.
- Storage: 5.3 PB Cray ClusterStor E1000.
Storage‑system challenges
The 60 PB preservation system is optimised for durability and cost, not for fast I/O, resulting in high read latency. Conversely, the AI‑pipeline storage is built for high‑throughput, low‑latency parallel access. Husnes noted that “nobody was talking about the problems involved in moving PB‑scale datasets from an archive to, and through, an AI data‑pipeline system.” His team had to devise the solution themselves.

Husnes – preservation and AI pipeline storage
Ongoing Learnings
The LLM training is still in progress. Husnes summarised the three main areas his team is still exploring:
- Evaluation – No standard tools exist to assess a sovereign Norwegian LLM. The language has two written forms, multiple dialects, and historical variations, so they are building a custom evaluation suite on the fly.
- Governance – Who controls access to a sovereign LLM? Who decides its permissible uses? These are institutional and political questions without easy answers.
- Orchestration – Integrating three systems—preservation archive, on‑prem AI environment, and the national Sigma2 supercomputer—remains an ongoing engineering effort.
Takeaway
Huawei’s OceanStor Dorado flash storage is playing a serious and significant role in enabling a European nation to build its own sovereign language model, demonstrating the importance of high‑performance, low‑latency storage in large‑scale AI pipelines.
Market Insight
…and two, that any country developing a sovereign, local‑language LLM would do well to consult with Husnes and get acquainted with what’s involved.
As Husnes put it: “Norway is a small country solving a problem every non‑English‑speaking nation will face—how do you build AI that reflects your language, your culture, and your history? AI needs custodians, not just builders.”