New Apple-backed AI model can generate sound and speech from silent videos
Source: 9to5Mac

VSSFlow – A Unified Audio Generation Model
The new model, VSSFlow, uses a novel architecture to generate both sounds and speech within a single, unified system, delivering state‑of‑the‑art results.
Watch (and hear) the demos below.
Demo links go here (Replace the placeholder with the actual video URLs.)
The Problem
Most video‑to‑sound models (i.e., models that generate audio from silent video) struggle to produce realistic speech. Conversely, most text‑to‑speech systems fail to generate non‑speech sounds because they are designed for a different purpose.
Prior attempts to unify these tasks often assume that joint training degrades performance. Consequently, they adopt multi‑stage pipelines that teach speech and sound separately, adding unnecessary complexity.
What the researchers did
Three Apple researchers, together with six collaborators from Renmin University of China, introduced VSSFlow—a single AI model capable of generating both sound effects and speech from silent video.
Key points of the architecture:
- Joint training: Speech and sound training reinforce each other rather than interfere.
- Unified pipeline: Eliminates the need for separate stages, simplifying the workflow.
- Bidirectional benefit: Improvements in speech generation boost sound‑effect generation, and vice versa.
The Solution
VSSFlow leverages several generative‑AI concepts:
- Phoneme‑level tokenisation – transcripts are converted into sequences of phoneme tokens.
- Flow‑matching – the model learns to reconstruct sound from noise, i.e., it is trained to start from random noise and end with the desired audio signal. (See the detailed explanation here.)
These ideas are combined in a 10‑layer architecture that fuses video and transcript information directly into the audio‑generation pipeline. The result is a single system capable of producing both sound effects and speech.
Key insight: Joint training on speech and environmental sounds improved performance on both tasks rather than causing them to compete.
Training data
| Dataset | Content |
|---|---|
| V2S | Silent videos paired with environmental sounds |
| VisualTTS | Silent talking videos paired with transcripts |
| TTS | Standard text‑to‑speech data |
The model is trained end‑to‑end on this mixture, learning to generate sound effects and spoken dialogue simultaneously.
Fine‑tuning for simultaneous output
Initially, VSSFlow could not produce background sound and spoken dialogue in a single output. To overcome this, the authors fine‑tuned the pretrained model on a large collection of synthetic examples where speech and environmental sounds were mixed together (see the synthetic‑data pipeline here). This fine‑tuning teaches the model the joint acoustic characteristics of both modalities.
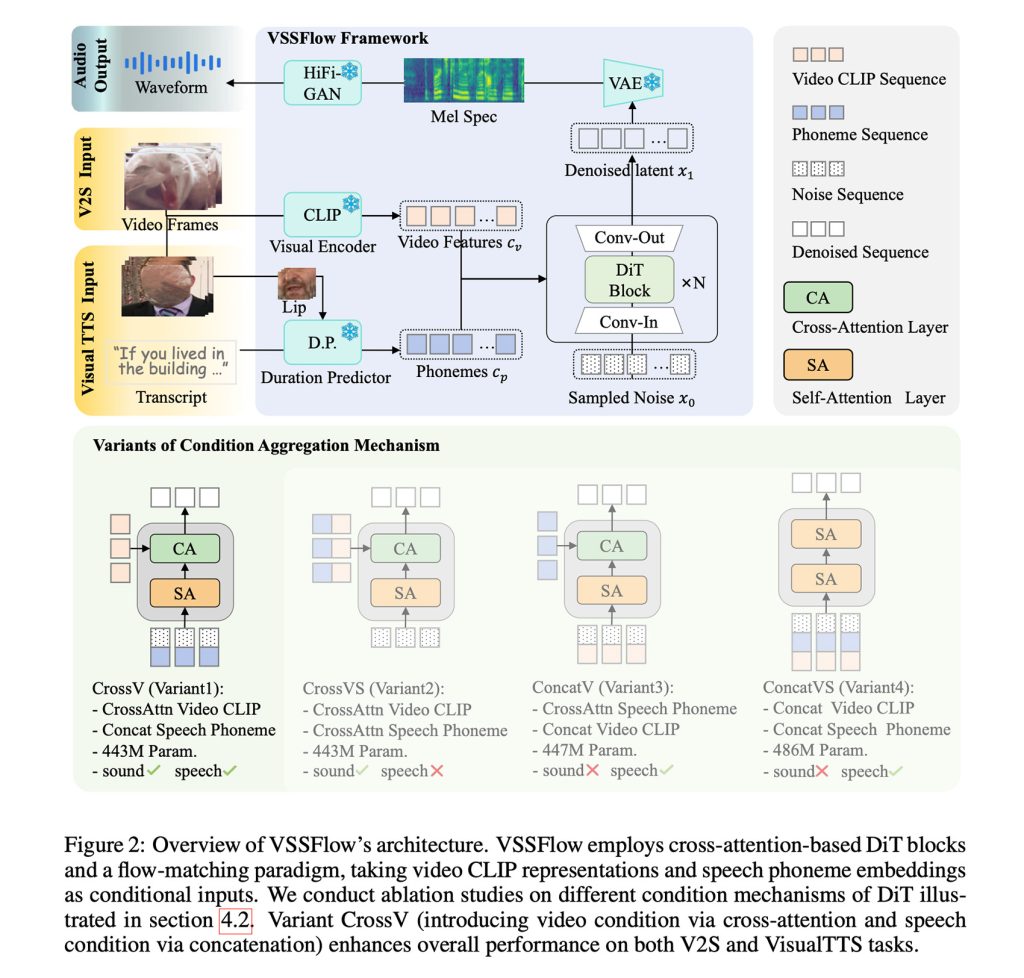
Figure: VSSFlow architecture
Putting VSSFlow to Work
To generate sound and speech from a silent video, VSSFlow starts from random noise and uses visual cues sampled from the video at 10 fps to shape ambient sounds. At the same time, a transcript of what’s being said provides precise guidance for the generated voice.
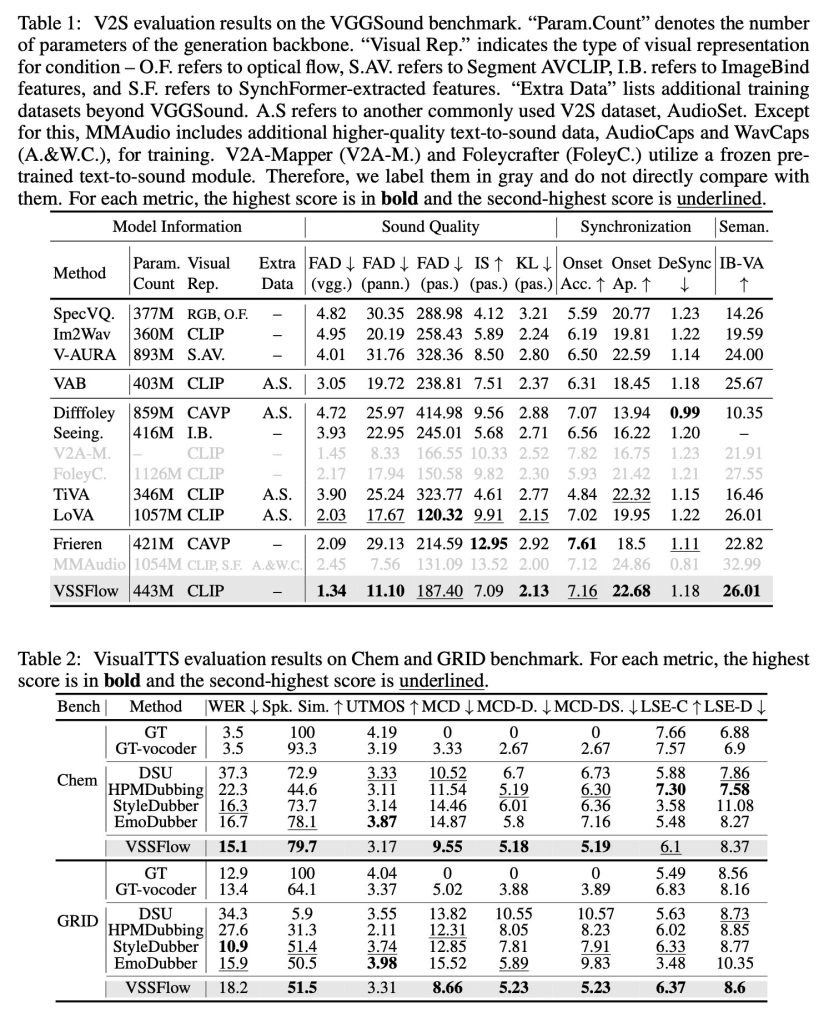
When tested against task‑specific models built only for sound effects or only for speech, VSSFlow delivered competitive results across both tasks, leading on several key metrics despite using a single unified system.
The researchers published multiple demos of sound, speech, and joint‑generation (from Veo3 videos) results, as well as comparisons between VSSFlow and several alternative models. You can watch a few of the results below, but be sure to head over to the demos page to see them all.
Note: The researchers have open‑sourced VSSFlow’s code on GitHub (github.com/vasflow1/vssflow) and are working to release the model’s weights and an inference demo.
Future Directions (quoted from the authors)
“This work presents a unified flow model integrating video‑to‑sound (V2S) and visual text‑to‑speech (VisualTTS) tasks, establishing a new paradigm for video‑conditioned sound and speech generation. Our framework demonstrates an effective condition‑aggregation mechanism for incorporating speech and video conditions into the DiT architecture. Besides, we reveal a mutual‑boosting effect of sound‑speech joint learning through analysis, highlighting the value of a unified generation model.
For future research, there are several directions that merit further exploration. First, the scarcity of high‑quality video‑speech‑sound data limits the development of unified generative models. Additionally, developing better representation methods for sound and speech—methods that preserve speech details while remaining compact—is a critical challenge.”
To learn more about the study, titled “VSSFlow: Unifying Video‑conditioned Sound and Speech Generation via Joint Learning,” follow this link.
Accessory Deals on Amazon
- AirPods Pro 3
- Apple AirTag 4‑Pack
- Beats USB‑C to USB‑C Woven Short Cable
- Wireless CarPlay Adapter
- Logitech MX Master 4
![]()
![]()
FTC: We use income‑earning auto‑affiliate links. More info