Most Outages Are Preventable: Why Your System Needs Self-Healing Yesterday
Source: Dev.to
Introduction
Self‑healing systems are computer systems that can automatically fix themselves when something goes wrong. Instead of waiting for a human to notice a problem and manually intervene (“reactive firefighting”), these systems are proactive. They continuously monitor themselves to catch tiny signs of trouble or degradation (a slight performance drop or early error). When an issue is detected, they automatically take steps to correct it—restarting a faulty component, rolling back a bad update, or isolating a sick part of the system.
Why Self‑Healing Is Important?
- Prevents outages before users feel them – systems detect degradation (latency, memory spikes, failed health checks) and fix themselves before customer impact.
- Eliminates on‑call fatigue – frees Ops teams from 3 AM “restart the pod” or “scale up” fire drills.
- Improves reliability & SLO compliance – automated correction keeps availability high without waiting for humans.
- Stabilizes microservice ecosystems – in distributed systems, failures cascade; self‑healing stops the chain reaction.
- Faster recovery = better user experience – automated rollback / restart / resync is faster than human debugging.
Key Tools Involved in Self‑Healing Systems
Health Detection (Identifying the “Wound”)
How the system knows something is wrong.
Correction / Healing
Once a wound is identified, the corrective mechanism kicks in.
Self‑Healing Steps
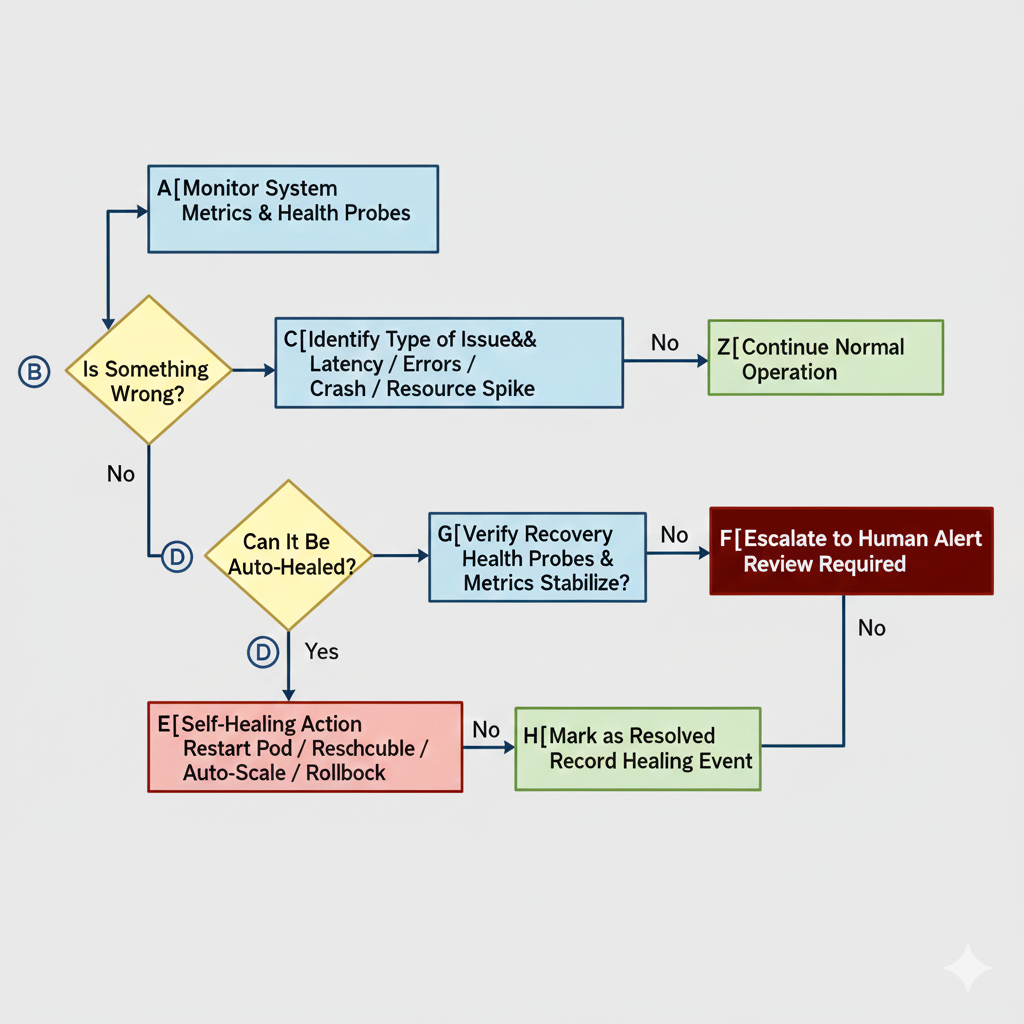
What Should Be Done During & After Self‑Healing
To ensure stability, engineering must treat self‑healing events as signals, not noise.
4.1 Record the Healing Event
- Timestamp
- Pod/container ID
- Failure reason
- Metrics snapshot
- Healing action performed
- Success/failure status
This becomes a goldmine for RCA later.
4.2 Analyze Pattern Trends
Look for:
- Pods restarting frequently
- High memory or CPU usage patterns
- Latency bursts after deployments
- Issues consistently after autoscaling
- Node‑specific failures
4.3 Continuous RCA
Self‑healing fixes symptoms. We must still fix the root cause:
- Memory leaks
- Deadlocks
- Bad deployments
- Faulty infrastructure
- Misconfiguration
- Resource starvation
4.4 Alert Humans Only When Needed
A healthy pattern:
- 1–2 self‑heals/day → OK
- 3 in a short window → alert
- Continual restarts → critical alert
4.5 Prevent Recurrence
Automate permanent fixes:
- Add throttling / rate‑limit
- Add retries with jitter
- Add circuit breakers
- Improve autoscaling thresholds
- Enforce resource limits
- Improve deployment validation
- Apply Helm rollback policies
Summary
Self‑healing is not just “auto restart.” It’s a full ecosystem:
Detect → Diagnose → Heal → Verify → Learn → Fix permanently
Jai Chinjo!