Magenta RealTime 2: Open and Local Live Music Models
Source: Hacker News
Jun 4, 2026
We’re excited to share Magenta RealTime 2 (MRT2), a state‑of‑the‑art open model and efficient real‑time inference engine that enables you to build and play AI musical instruments on your laptop!
To get started, download the apps on your MacBook (requires Apple Silicon).
Unlike other large generative music models that work offline to turn a prompt into a track, MRT2 is a live, interactive model that you can control with MIDI, audio, and text. It performs low‑latency on‑device inference to respond to your inputs instantly. You can run it as a standalone app, drop it into your DAW, or integrate it into other music software.
In addition to the open‑weights model, we are releasing a collection of playable instruments and experiences built with MRT2. Experiment with cloning sounds, blending styles, and creating live accompaniment with this low‑latency music model.
To explore the potential of live music models as instruments, today we are releasing:
- Magenta RealTime 2, an open‑weights model (2.4 B parameters) capable of high‑quality real‑time music synthesis with low‑latency real‑time controls via MIDI, text, and audio.
- An open source Python library (
pip install magenta-rt) offering inference via JAX/MLX using SequenceLayers. - An inference engine written in C++, enabling efficient streaming audio generation on a MacBook GPU via MLX.
- A suite of example applications built on the inference engine, showcasing the creative potential of MRT2 and serving as references for new instruments and software integrations.
For a decade, the Magenta team has championed a vision of AI as a tool for musicians, never a replacement. We released our first neural synthesizer, NSynth, back in 2017 which put machine learning into playable hardware. Subsequent AI Instruments include DDSP, Piano Genie, and the first version of Magenta RealTime, a live music model capable of generating and blending a wide range of musical styles. MRT2 achieves ~15× lower latency than version 1, works on standard hardware, and integrates directly into DAWs, making this live model a true musical instrument.
A live music model with lower latency and expanded control
| Feature | Magenta RealTime | Magenta RealTime 2 |
|---|---|---|
| Live music generation | ✅ | ✅ |
| Hardware required | TPU / GPU | MacBook (Apple Silicon) |
| Frame size | 2 s | 40 ms |
| Control latency | ~3 s | ~200 ms |
| Control modalities | Text, Audio | Text, Audio, MIDI |
| Model sizes | 760 M / 220 M | 2.4 B / 230 M |
Both MRT and MRT2 are codec language models operating on sequences of audio tokens from the SpectroStream codec. MRT2 achieves lower latency by performing frame‑level autoregression with frame‑aligned conditioning. To enable expressive musical control, MRT2 models audio that continuously follows MIDI inputs, alongside style prompts (audio or text) embedded via MusicCoCa. Signals are injected as frame‑aligned conditioning at every generation step, allowing the model to react within a single frame (40 ms, plus empirical latency sources; see Real‑world control latency below).
Key to this approach is a causal sliding‑window attention mechanism that enables continuous streaming generation while bounding memory usage. Learnable attention embeddings improve generalization to arbitrary durations and mitigate context‑eviction artifacts (e.g., ringing and feedback) during long‑context generation.
Fast C++ inference engine via MLX

While the original Magenta RealTime required a high‑power GPU or TPU, MRT2 brings live generation to the hardware musicians actually use. We built a C++ inference engine powered by MLX that runs natively on Apple Silicon. Apple’s MLX framework links Python and C++. The MRT2 model, implemented with the SequenceLayers library, is compiled into an .mlxfn file (containing weights and computational graph). The C++ engine loads this file and uses the MLX runtime to execute it efficiently on Apple Silicon GPUs, handling model state, audio buffering/resampling, and MIDI input.
MLX enables MRT2 to run on Apple Silicon (M‑series) devices:
| Model | Platform |
|---|---|
| Base (2.4 B) | MacBook M3 Pro (or higher) MacBook M2 Max (or higher) |
| Small (230 M) | Any Apple Silicon MacBook, including MacBook Air |
A suite of example applications for musicians and developers
A key goal of MRT2 is to let musicians integrate live music models within existing software and help developers build custom applications. Our codebase provides several examples, including standalone apps, plugins, and extensions.
What’s Next?
Our team has been building new instruments with machine learning for nearly 10 years (see NSynth). With MRT2, AI instruments finally gain the controllability and immediacy expected from music‑creation tools, but many avenues remain to explore: even lower control latency, audio‑streaming inputs for jamming, and richer real‑time interaction.
Upcoming features and applications include:
- Finetuning – customize the model by training on your own data.
- Example performance tools created with Manaswi Mishra.
We will also present a challenge centered on MRT2 at the Music Technology Hackathon in Boston in the coming days. Stay tuned for updates!
Citation
Please cite our work as:
Magenta Team. “Magenta RealTime 2: Open & Local Live Music Models”. https://magenta.withgoogle.com/magenta-realtime-2. June 2026
@article{mrt2,
title = {Magenta RealTime 2: Open & Local Live Music Models},
author = {Magenta Team},
year = {2026},
note = {https://magenta.withgoogle.com/magenta-realtime-2}
}Appendix: Technical Details
Low‑latency streaming generation
Codec language modeling background. A codec language model (LM) operates on discrete token sequences produced by a neural audio codec (encoder + decoder). The encoder maps raw stereo audio (\mathbf{a} \in \mathbb{R}^{T f_s \times 2}) to token matrices (\mathbf{x} \in \mathbb{V}_c^{T f_k \times d_c}).
The LM models these token matrices, typically using a hierarchical autoregressive framework with two Transformers: a Temporal encoder that compresses history into fixed‑length embeddings, and a Depth decoder that generates tokens depth‑wise conditioned on the current frame embedding.
[ P_{\theta,\phi}(\mathbf{x}) = \prod_{i=1}^{T f_k}!! \prod_{j=1}^{d_c} P_\phi!\bigl(x_i^j \mid \mathbf{x_i^{<j}}, \texttt{Temporal}\theta(\mathbf{x{<i}})\bigr) ]
We use the SpectroStream codec to compress 48 kHz stereo audio into tokens at 3 kbps ((f_k = 25) Hz, (d_c = 12), (|\mathbb{V}_c| = 2^{10})).
From chunk‑level to frame‑level autoregression.
Original Magenta RealTime generated on 2‑second chunks (400 tokens per chunk), which limited control latency to ≥ 2 s. MRT2 instead models individual frames (12 RVQ tokens per 40 ms frame), reducing the minimum control delay to ~0.2 s.
We adopt a decoder‑only architecture with sliding‑window attention (SWA), allowing continuous streaming while keeping the KV‑cache size fixed. At each step, new token keys/values are written, and entries older than the window size w are evicted.
To mitigate degradation when early tokens are evicted, we introduce a learnable attention sink embedding and drop learnable positional embeddings (using NoPE) in favor of causal masking and SWA, which naturally generalize to arbitrary sequence lengths.
| Aspect | Magenta RealTime | Magenta RealTime 2 |
|---|---|---|
| Autoregressive unit | 2‑second chunks (25 frames × 16 RVQ = 400 tokens) | Individual frames (12 RVQ tokens at 25 Hz = 40 ms) |
| Architecture | T5‑style bidirectional encoder + causal decoder (encoder processes full chunk before decoding) | Decoder‑only; conditioning injected each frame, no encoder bottleneck |
| Minimum control delay | ≥ 2 s (next‑chunk boundary) | ~0.2 s (frame processing + depth decode + codec decode) |
Precise control through frame‑by‑frame conditioning
MRT2 supports multi‑signal control: style (audio or text), note on/off, and drum on/off. Conditioning signals are tokenized at the audio frame rate (25 Hz) and concatenated into a single per‑frame vector (\mathbf{c}), which is injected via streaming cross‑attention.
Style control uses frozen MusicCoCa embeddings (audio + text). To bridge the modality mismatch between audio‑trained and text‑inferred embeddings, we train a generative mapper (pixel Mean Flow) that samples diverse audio embeddings from a text embedding, enabling high‑quality one‑step inference.
Note control is learned from (audio, MIDI) pairs. A 128‑channel pianoroll (one channel per MIDI pitch) encodes note activity at 25 Hz. Two inference modes are supported:
- Auto‑Strum – only pitch activity is provided; the model decides note onsets.
- Auto‑Strum OFF – explicit onset timing is supplied, giving precise attack control.
A 4‑token vocabulary (note‑off, note‑on, onset, continuation) and onset masking augmentation enable a single model to handle both modes.
Drum control is optional. During training we provide frame‑wise drum‑hit sequences (via OaF Drums) but at inference we use this signal solely to toggle drum‑less generation.
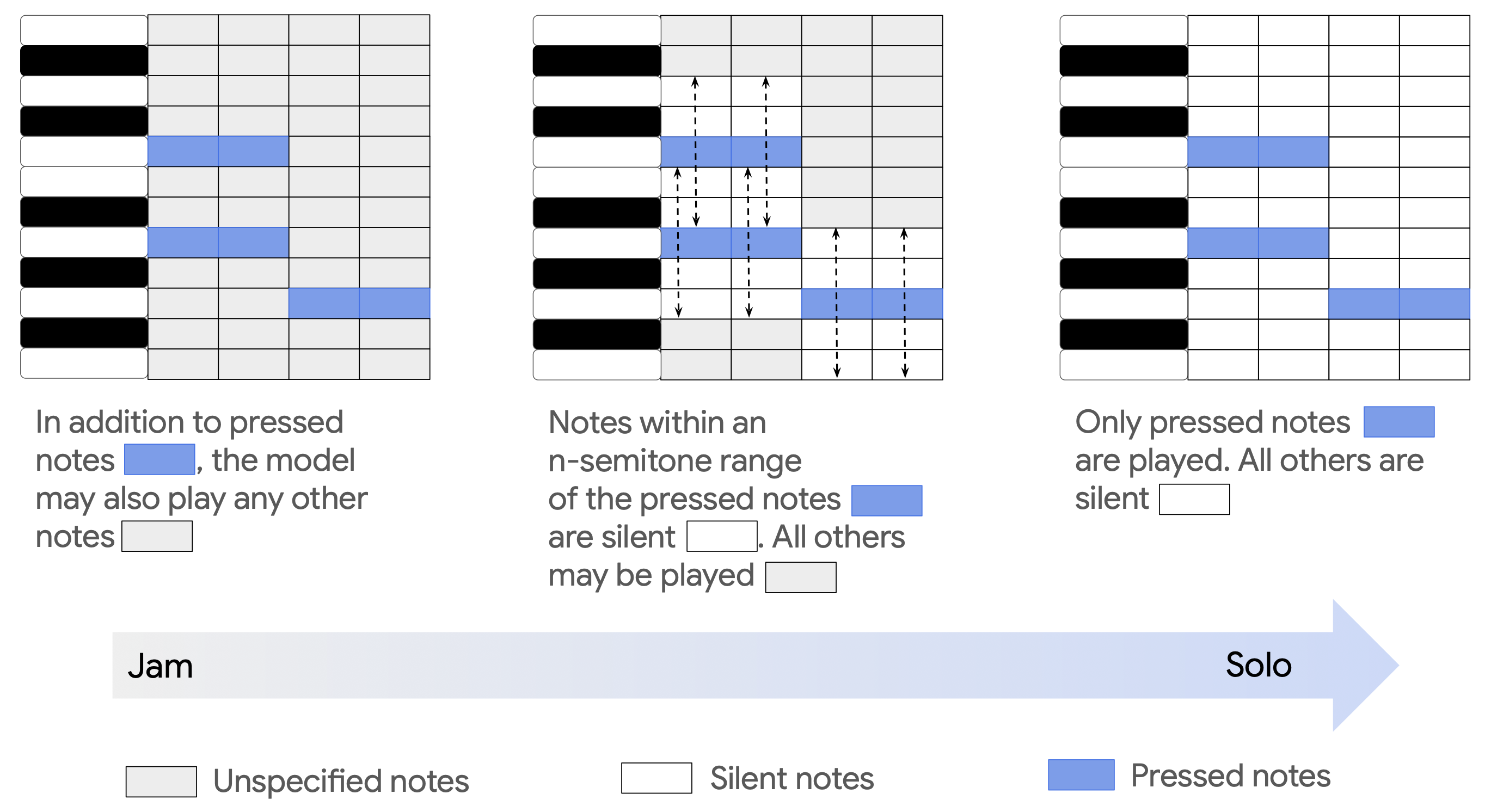
Inference‑time masking allows creative modulation of controls. Random contiguous masking of conditioning signals during training improves adherence to provided inputs and enables partially unconditional generation. Examples include:
- Masking all pianoroll pitches except those currently pressed → model adds harmonies.
- Masking neighboring pitches → model stays faithful to the input notes.
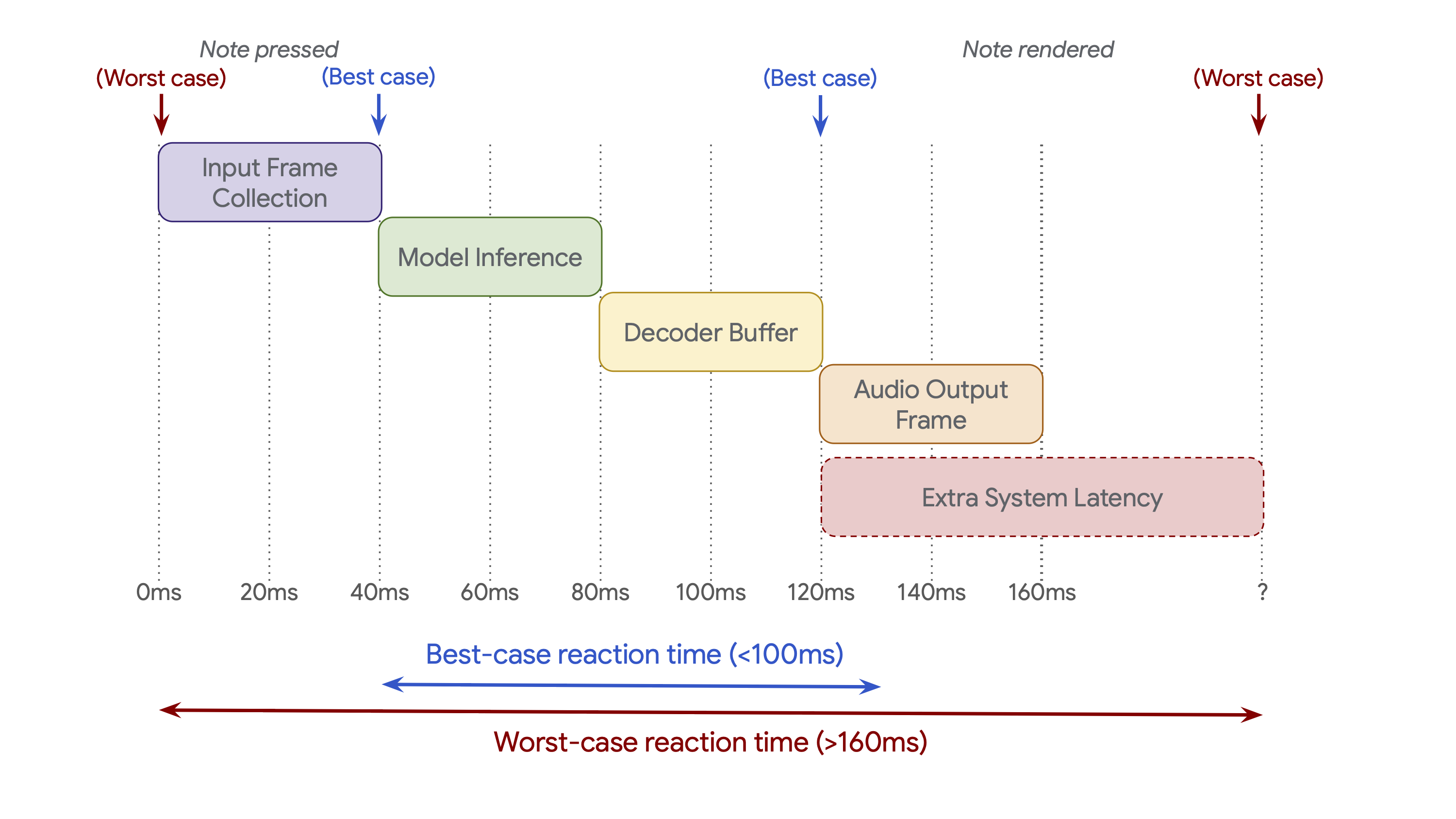
Real‑world control latency
Even with a 40 ms frame size, end‑to‑end latency includes input buffering, model inference, and output buffering. The diagram below sketches the total reaction time, accounting for additional latency introduced by external components.